概述
使用 S3 下载文件的时候,我们往往会遇到一些多个小文件需要下载的场景,如果直接给终端用户端多个下载链接,会严重影响终端用户体验,且当小文件数量较多时,他们在 S3 目录结构无法的提供,因此,我们在 AWS 上使用 S3 下载多个小文件时,可以利用 Lambda 压缩小文件的方式,来提高终端的下载的体验。
使用 Lambda 压缩有两种方式:
- 批量文件上传时,可以使用 Lambda 的 S3 触发器,来设置触发条件,自动触发 Lambda,将文件批量压缩;
- 用户请求时,根据用户需求,Lambda 临时压缩文件并返回。
上述两种方式各有优缺点,如下:
- 方案 1:用户访问时无额外压缩时间,直接返回压缩好的内容,访问速度更快,但是终端用户请求往往不是固定的,所以灵活性有缺点,而且每次批量压缩后保存,会产生一些额外的 S3 存储成本;
- 方案 2:可以很灵活的匹配终端用户需要压缩文件变化的需求,但是因为临时生成压缩文件,因此会有一定的压缩时间消耗。
综合两种方式的优缺点,作者这里更加倾向于方案二。效率低的缺点,我们可以在 Lambda + API Gateway 之前接入 AWS Cloudfront,将计算的结果缓存,加速二次访问速度。而且主要针对小文件压缩,时间一般在几百 ms 左右的消耗,并且在获取 S3 源文件时,可以采用多线程等方式提高代码执行效率,降低整个请求的延迟,提高用户访问效率。而方案 1 无法灵活实现终端需求变化的缺点,却很难弥补。Ok,话不多说,我们先来看下整体的架构:

整体架构中,我们会使用到 API Gateway,Cloudfront, Lambda,S3 这些服务,在 API Gateway 和 S3 之前加一个 Cloudfront 来进行内容分发;API Gateway 主要作用为暴露 Lambda,且可以使用 IAM/JWT 等方式来对用户访问进行身份验证;Lambda 主要为压缩的计算单位;S3 用来存储临时数据存储。
Lambda 示例代码与配置方式
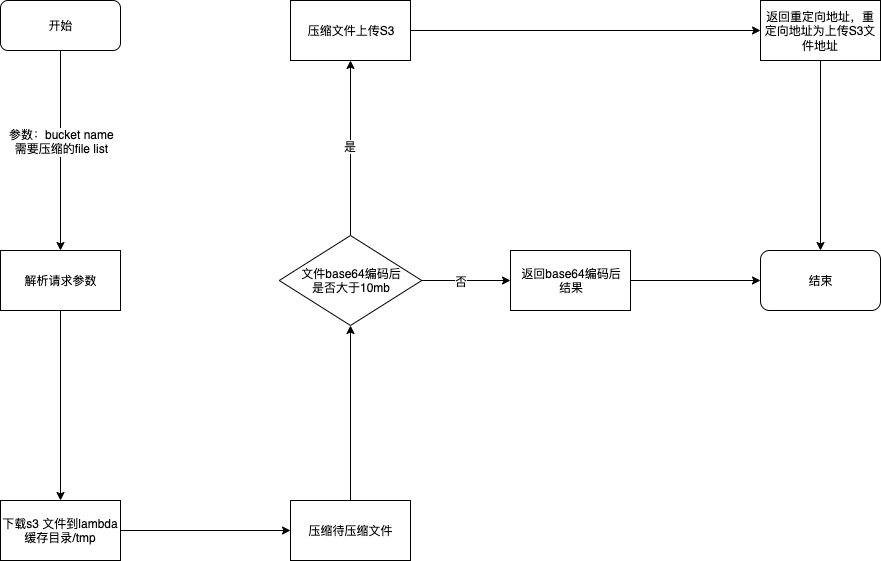
Lambda 是我们进行压缩的计算主体,因此,我们所有的代码逻辑都会使用 Lambda 实现,作者使用 Lamba 主要实现的业务逻辑流程图如下:

整个代码编写与部署中,有几个点我们需要注意:
1. Lambda 返回结果给 API Gateway 时,是一个 json 数据,整体大小不能超过 10MB,因此,我们需要将压缩后文件转成 base64 编码,且判断转换后字段长度是否超过 10MB,未超过,可以直接返回;
2. 直接返回时,我们一般希望用户浏览器端可以直接下载,所以需要对 json 中的 header 等字段设置,添加下载标头与 base64 解码信息,返回标头可以参考如下:
{
'headers': {
# 使用http 下载标头,标识下载文件与下载文件名
"Content-Type": "application/octet-stream",
"Content-Disposition": "attachment; filename=\"%s\"" % result_download
},
'isBase64Encoded': True, #body是否base64编码
'statusCode': 200,
'body': b64_content,
}
3. 若超过 10MB,我们可以将其上传至 S3,并将其 S3 + Cloudfront 地址设定为重定向地址,返回重定向请求,返回标头可以参考如下:
{
'headers': {
#重定向标头
"Content-Type": "text/html",
"Location": redirect_path
},
'isBase64Encoded': False,
'statusCode': 302
}
4. 从 S3 下载文件时,Lambda 的临时存储目录是/tmp,其他目录没有权限。
完整的 Lambda 代码可以参考:
import json
import os
import boto3
import base64
import random
import zipfile
import time
import re
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
executor = ThreadPoolExecutor(max_workers=100)
redirect_domain = os.environ['DOMAIN']
def lambda_handler(event, context):
# TODO implement
print(event)
params = event['queryStringParameters']
bucket = params['bucket']
keys = params['keys'].split(',')
print(keys)
result_download = generate_random_str()
client = boto3.client('s3')
tasklist = []
wait_compressed_files = []
for key in keys:
task = executor.submit(download_s3_file, client, bucket, key)
wait_compressed_files.append('/tmp/' + key)
tasklist.append(task)
wait(tasklist, return_when=ALL_COMPLETED)
# wait_compressed_files = down_all_s3_obj(bucket, keys)
print('all download completed')
print('need compressed', wait_compressed_files)
zip_files(result_download, wait_compressed_files)
b64_content = base64.b64encode(open('/tmp/' + result_download, 'rb').read()).decode('utf-8')
if len(b64_content) > 10000000:
redirect_path = 'https://' + redirect_domain + upload_to_s3_file(client, bucket, result_download)
return {
'headers': {
"Content-Type": "text/html",
"Location": redirect_path
},
'isBase64Encoded': False,
'statusCode': 302
}
return {
'headers': {
"Content-Type": "application/octet-stream",
"Content-Disposition": "attachment; filename=\"%s\"" % result_download
},
'isBase64Encoded': True,
'statusCode': 200,
'body': b64_content,
}
# 将压缩后文件上传到S3
def upload_to_s3_file(client, bucket, local_file):
data = open('/tmp/'+local_file, 'rb')
client.upload_fileobj(data, bucket, 'compressed/' + local_file)
return '/compressed/' + local_file
# 将s3文件下载到本地
def download_s3_file(client, bucket, key):
mkdir_function(key)
data = open('/tmp/'+key, 'wb')
client.download_fileobj(bucket, key, data)
print('download %s finished' % ('/tmp/'+key))
# conn.send('/tmp/'+key)
# conn.close()
# 正则贪婪匹配所有文件夹,没有则创建
def mkdir_function(path):
temp_path = path
if '/' not in temp_path:
return
if not temp_path.startswith('/'):
temp_path = '/' + temp_path
file_folder = '/tmp' + re.match(r'\/.*#?(?=\/)', temp_path).group(0)
print(file_folder)
if not os.path.exists(file_folder):
os.makedirs(file_folder)
# 压缩文件名称生成方法
def generate_random_str(randomlength=8):
random_str = ''
base_str = 'ABCDEFGHIGKLMNOPQRSTUVWXYZabcdefghigklmnopqrstuvwxyz0123456789'
length = len(base_str) - 1
for i in range(randomlength):
random_str += base_str[random.randint(0, length)]
return random_str + '.zip'
# zip压缩
def zip_files(download_name, files):
zf = zipfile.ZipFile('/tmp/' + download_name, mode='w', compression=zipfile.ZIP_DEFLATED)
for file in files:
zf.write(file, file.replace('/tmp', ''))
zf.close()
我们主要注意几个点:
1. Lambda 的权限需要注意,我们需要一个有读取和写入的 role 附加给 Lambda。

2. 大于 10mb 的文件会被重新穿回 S3 目录,并且需要重定向,需要给一个重定向的 host,以便组成新的 URL,该 host 在作者的示例代码中,我们用环境变量的形式给代码。

Python 代码直接直接在 AWS Lambda console 中编辑,因此我们可以直接创建对应的 Lambda,注意需要给 Lambda 赋予 S3 访问与读取的权限。
API Gateway 配置
配置完成 Lambda 代码后,我们就可以来配置 API Gateway 用于暴露 Lambda方法。
1. 创建一个 API Gateway 接口。注意,这里建议选择 HTTP API,相比较于 Restful API,他是新版本的 API Gateway 配置方式,因为我们会返回 HTTP body,HTTP API 可以自动帮我们完成二进制类型转换,而 Restful API 则需要我们去主动添加对应的文件类型。

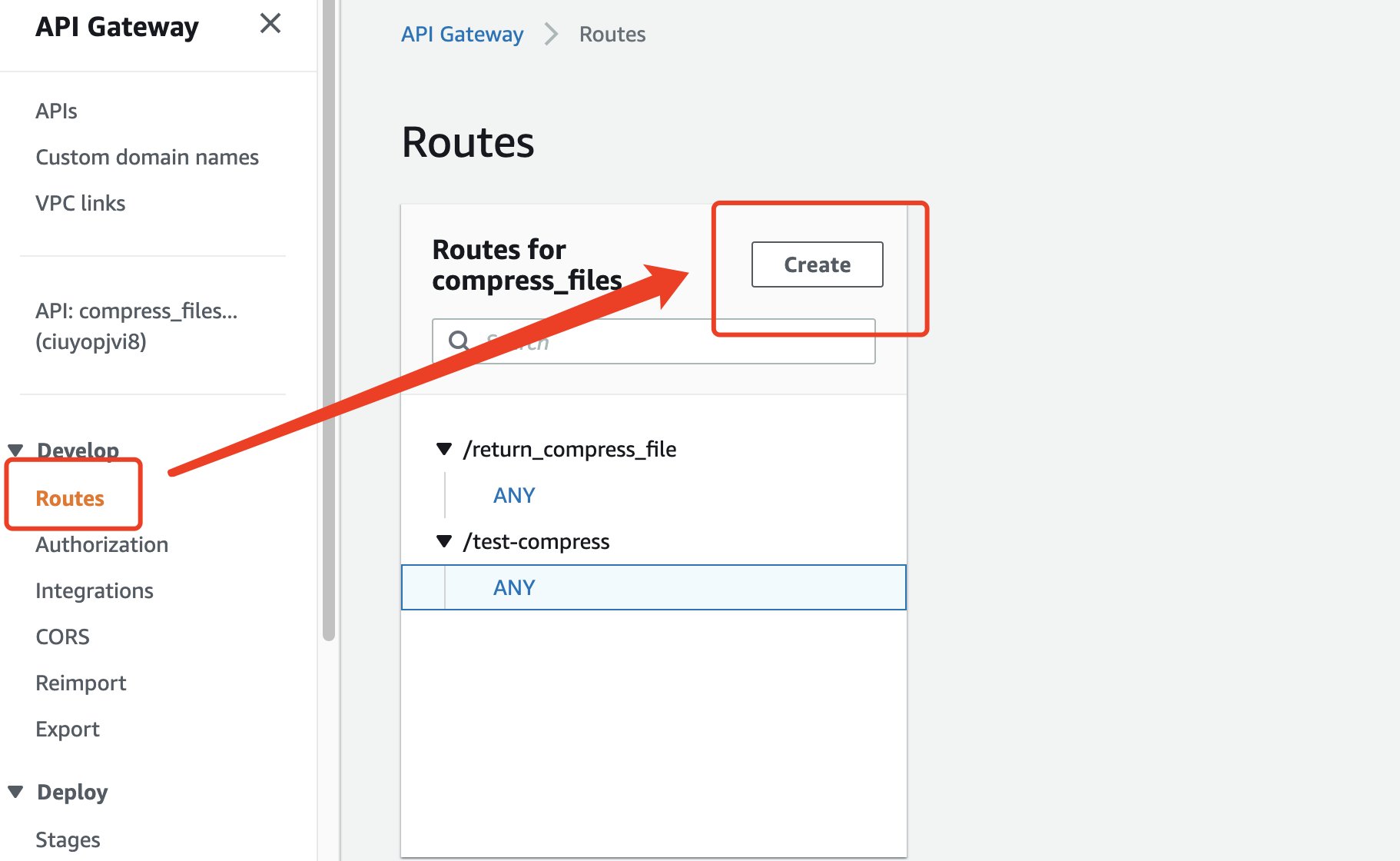
2. 完成 API 创建后,我们就可以创建我们所需的路由:

3. 创建玩对应的路径后,我们就可以为请求路径去添加 Integrations,就是刚才我们创建完成的 Lambda。

4. 目标类型选择 Lambda,然后填入我们的 Lambda Arn,其余默认就可。

测试
完成 API Gateway 创建后,我们就可以在浏览器中测试最终的效果了。
测试的地址为 API Gateway 的 host,加上我们的 path,以及请求参数,以下是示例请求路径和结果:
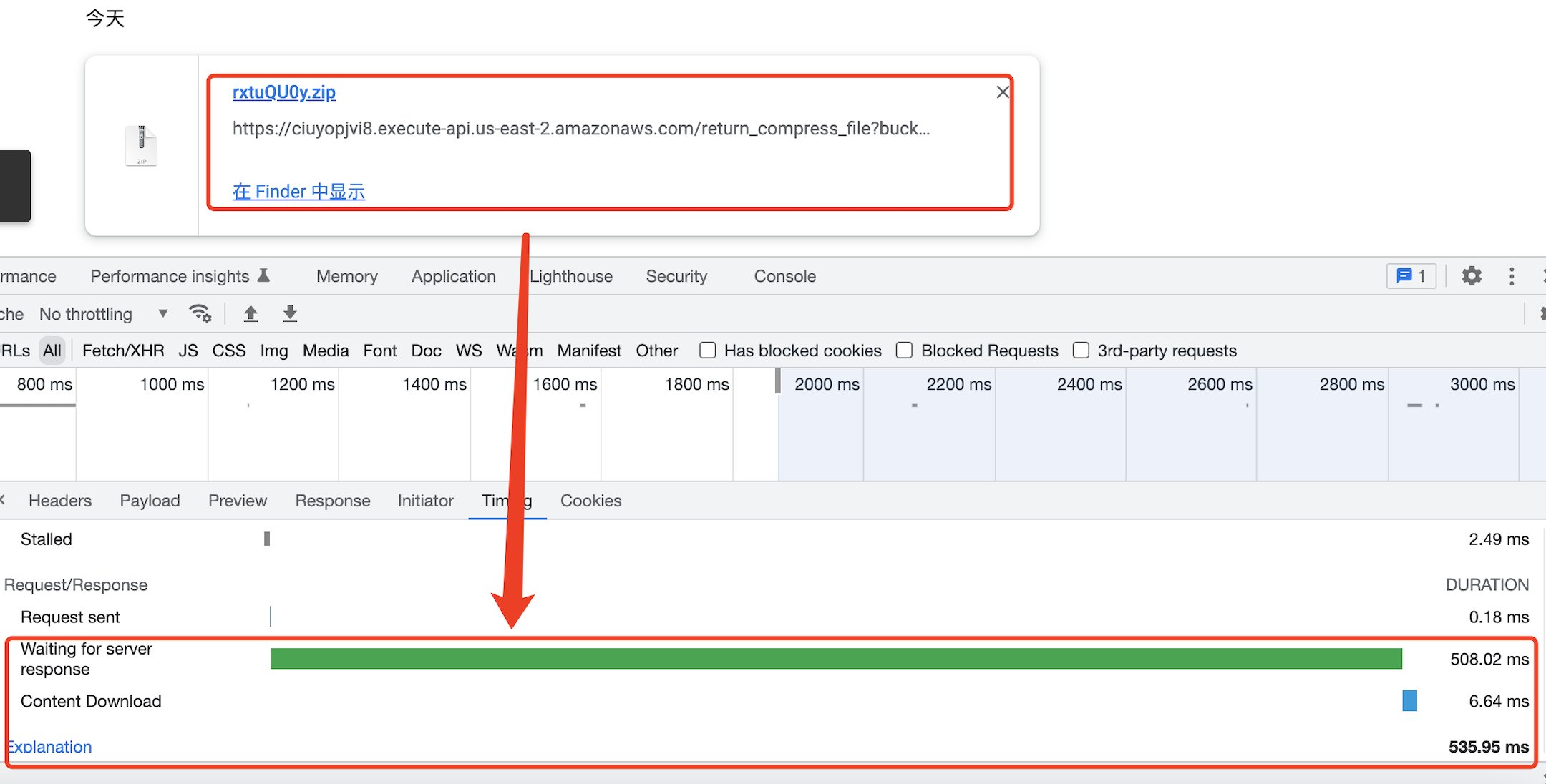
https://ciuyopjvi8.execute-api.us-east-2.amazonaws.com/return_compress_file?bucket=test.snxzheng.com&keys=IoT.png,test/IoT.png

文件成功下载,并且耗时约为 500ms 左右(没有 cdn 缓存,直接请求),作为一次 HTTP 目标为下载的请求,在可接受范围内。
下载的文件内容我们也可以看到,他保持了在 S3 中的目录结构。

为了保证后续的效果,我们也可以在 API Gateway 前面添加一个 Cloudfront,缓存下载结果,提高用户体验。
总结
AWS 中 Lambda 等服务可以为我们很方便的解决很多业务中的小问题,除了 Lambda 以外,其实还有很多类似的润滑剂服务,借助他们,可以让我们的业务更快的实现云原生。
本篇作者






{kind=link}