介绍
难度: 中级
时间: 30 分钟
相关产品: Amazon Bedrock
上次更新时间: 2025 年 4 月 4 日
在本文中,我们将详细介绍 Amazon Bedrock 评估 的多种功能,并通过实际示例演示如何评估 RAG 系统和模型。我们还会演示如何对比多个不同的 AI 实现方案,以及如何根据评估数据做出 AI 部署决策。无论生成式 AI 应用程序是部署在 Amazon Bedrock 上,还是其他环境中,这些评估工具均能帮助提高整个生成式 AI 应用的性能和质量。
新功能:RAG 评估
全部打开在本节中,我们将介绍 RAG 评估方面的新功能:用于评估外部 RAG 系统的 Bring Your Own Inference Responses 功能,以及用于衡量 RAG 引用的准确度和覆盖度的新增引用评估指标。
RAG 评估能力支持在 Amazon Bedrock 评估环境中评估托管在任何地方的 RAG 系统的输出。使用 Bring Your Own Inference Responses (BYOI) 功能,你只需提供满足格式要求的响应数据,即可评估多个来源的检索和生成结果,包括其他服务商提供的基础模型、自建 RAG 系统或已部署的开放权重解决方案。此外,我们在此前已发布的质量评估指标和负责任的 AI 评估指标的基础上还引入了新的引用评估指标,可以帮助你更好地了解 RAG 系统对知识库和源文档的利用情况。
在评估根据知识库获取的检索结果时,可以针对每个知识库运行一个评估任务。对于每个数据集条目的评估,你可以提供一系列的对话轮次数据来进行评估。每个对话轮次数据中可以包含一个 prompt 和一个 referenceResponses 字段。在使用 BYOI 时,你必须通过新增的 output 字段提供检索结果。(output 字段是 BYOI 任务的必选项,但对于非 BYOI 任务则是可选项。)并且,必须为每个 output 指定 knowledgeBaseIdentifier。此外,对于所提供的每条检索结果,你还可以指定名称 (name) 和通过键值对形式提供额外的元数据 (metadata)。下面是 RAG 评估任务 (检索评估) 的 JSONL 输入格式。其中,带有问号 (?) 标记的字段为可选字段。
在 2025 年 3 月 20 日结束的公开预览版本中,数据集格式中包含一个名为 referenceContexts 的键。为了与检索生成评估 (Retrieve and Generate evaluation) 设置保持一致,该字段现已更改为 referenceResponses。referenceResponses 中的内容应为完整的 RAG 系统根据给定提示 (Prompt) 生成的期望真实答案,而不是直接从知识库中检索到的期望段落或数据块。
{ "conversationTurns": [ { "prompt": { "content": [ { "text": string } ] }, "referenceResponses"?: [ { "content": [ { "text": string } ] } ], "output"?: { "knowledgeBaseIdentifier": string "retrievedResults": { "retrievalResults": [ { "name"?: string "content": { "text": string }, "metadata"?: { [key: string]: string } } ] } } } ] }在评估根据知识库或使用 RAG 系统检索和生成的结果时,一个评估任务只能用于评估一个知识库或 RAG 系统。对于每个数据集条目的评估,可以提供一系列的对话轮次数据来进行评估。每个对话轮次数据中可以包含一个 prompt 和一个 referenceResponses 字段。在使用 BYOI 时,必须通过新增的 output 字段提供生成的文本、检索的段落(比如检索结果)和生成本文的引用来源。(oupput 字段是 BYOI 任务的必选项,但对于非 BYOI 任务则是可选项。) citations 字段内容将用于计算引用评估指标。如果没有引用来源,可以在该字段中输入虚拟数据,但是在这种情况下,请不要在评估任务中选择引用准确度或引用覆盖度指标。此外,还必须为每个 output 指定 knowledgeBaseIdentifier。knowledgeBaseIdentifier 的取值在整个数据集中和评估任务中应保持一致。以下是 RAG 评估任务(检索生成评估)的 JSONL 输入格式。其中,带有问号 (?) 标记的字段为可选字段。
引用准确度:评估引用的段落是否真的包含响应输出中使用的信息,此指标用于衡量 RAG 系统引用信息来源的准确性。该指标可用于识别响应中是否存在不必要或无关引用,其中一种比较常见的情况是,模型引用了某些段落但并未真正将这些引用段落用于生成响应内容。该指标的值是用 0–1 的数值表示的得分,其中 1 表示最高引用准确度(所有引用段落均与响应相关,且均用于生成响应内容),0 表示完全不准确(所有引用段落均未用于生成响应内容)。如果 RAG 系统随意引用而不是有选择性地只引用可用于生成响应的段落时,可以通过该指标发现此类问题,然后修复问题。
引用覆盖率:评估引用段落对生成的响应内容的贡献程度,其关注的重点是,从检索的段落中提取的所有信息是否被完全引用。该指标的计算方法:比较生成的响应内容与引用段落以及全部的检索段落的相关性,然后计算比例。如果响应内容与检索的段落内容完全不相关(比如出现幻觉),该指标值表示引用覆盖度评估结果不理想。该指标的值是用 0–1 的数值表示的得分,分数越接近 0 表示模型未引用相关的段落,越接近 1 则表示模型对检索段落的信息引用得当。请注意,满分 1 并不代表响应中的信息均来自引用段落,而是表示所有可引用信息(检索的段落)都得到了完全引用。该指标可以帮助发现 RAG 系统未引用相关源材料的情况。
新功能:模型评估
全部打开模型评估功能支持在 Amazon Bedrock 评估环境中评估任何模型的输出。借助 BYOI,只需提供格式正确的输出数据,即可评估来自其他服务商的基础模型响应或已部署解决方案中的模型响应。BYOI 支持 LLMaaJ 和人工评估工作流。
并且,这种评估方法不仅限于评估基础模型。由于 BYOI 评估只需要提供提示 (prompt) 和输出 (output),因此可以将整个应用程序的最终响应内容都纳入评估数据集。
在使用 LLMaaJ 时,一个评估任务只能评估一个模型。因此,在每次评估中,只能在 modelResponses 列表中提供一个条目,但可以通过执行多个评估任务来比较不同的模型。modelResponses 是 BYOI 任务的必选项,但对于非 BYOI 任务则是可选项。以下是使用 BYOI 进行 LLMaaJ 评估的 JSONL 输入格式。其中,带有 ? 标记的字段为可选字段。
功能概览
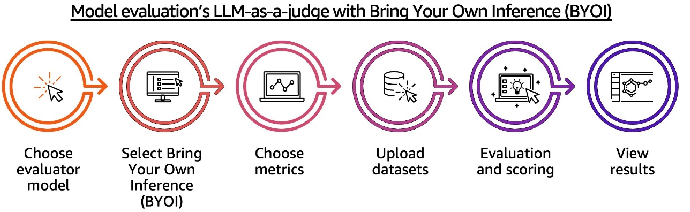
全部打开借助基于 BYOI 的 LLMaaJ 评估工作流,可以利用 Amazon Bedrock 模型评估功能对想使用的模型输出进行系统性评估。该工作流的使用流程简单,具体包括:选择评估器模型并配置 BYOI、选择合适的指标、上传评估数据集、运行评估,最后分析评估结果。无论 AI 应用部署在哪里,这条完整的评估管道(如下图所示)均可在 AI 应用实现过程中保证其输出质量。
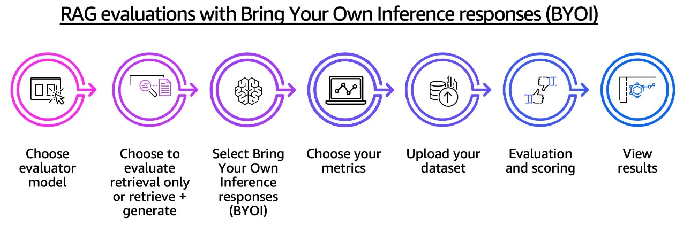
RAG 系统评估工作流中还加入了专门用于上下文检索分析的组件和指标。该工作流的具体流程为:选择评估器模型,然后选择仅检索评估模式或检索生成评估模式。使用 BYOI,可以评估来自任何来源的 RAG 输出,同时能够使用强大的 LLMaaJ 指标来评估 RAG 系统的检索质量或整个端到端检索生成流程。这套端到端的评估框架(如下图所示)可以深入了解 RAG 系统能在多大程度上有效利用检索到的内容来生成准确且依据充分的响应。
前提条件
全部打开- AWS 账户和模型访问权限:
- 已有一个有效的 AWS 账户
- 已在 Amazon Bedrock 中启用要使用的评估器模型(可在 Amazon Bedrock 控制台 的 Model access(模型访问)页面中确认已启用的模型)
- 已确认这些模型在目标 AWS 区域的可用性和配额
- AWS Identity and Access Management (IAM) 和 Amazon Simple Storage Service (Amazon S3) 配置:
- 已完成模型访问和 RAG 评估所需的 IAM 设置和权限设置
- 已为 S3 存储桶配置访问和写入输出数据的权限
- 已为 S3 存储桶启用跨域资源共享 (CORS)
要使用 BYOI 来进行 LLMaaJ 模型评估和 RAG 评估,必须满足以下前提条件:
数据集说明和准备
全部打开为演示创建基于BYOI 的 LLMaaJ 评估任务,我们使用了一个第三方模型并创建了一个购物类数学问题数据集。该数据集共包含 30 道折扣计算问题,并为每个问题都配备了符合 BYOI 指定格式的 Prompt、参考答案和模型响应。在 modelResponses 数组中,每个记录 (Record) 都使用 "third-party-model" 进行标识,以便 LLMaaJ 评估器能够根据选择的指标来评估响应质量。
在使用 BYOI 进行 RAG 评估时,我们采用的数据集是基于 Amazon 10-K SEC 年度报告创建的。数据集中的每个记录都包含 Amazon 公司信息相关的问题(比如 SEC 文件编号、经营分类、财政年度报告等)、参考响应,以及第三方模型生成的答案及对应的检索段落和信息来源。该数据集采用 BYOI 要求的格式,并且每个记录均使用 "third-party-RAG" 作为知识库标识符。采用这种结构,我们可以同时评估检索和生成的质量指标和引用准确性,从而证明可以使用这种方法来评估部署在任何地方的 RAG 系统。
在 Amazon Bedrock 控制台上创建基于 BYOI 的 LLMaaJ 评估任务
全部打开- 在 Amazon Bedrock 控制台的导航栏中,选择 Inference and Assessment(推理与评估),然后点击 Evaluations(评估)。
- 在 Evaluations(评估)页面中,选择 Models(模型)。
- 在 Model evaluations(模型评估)区域,点击 Create(创建),然后选择 Automatic: Model as a judge(自动:将模型作为评判者)。
在第一个示例中,我们将使用发布在 amazon-bedrock-samples 仓库中的 Prompt 和推理响应数据集。可以在简单易用的 AWS 管理控制台界面上,使用 Amazon Bedrock 模型评估中基于 BYOI 的 LLMaaJ 评估任务来评估模型性能。创建评估任务的操作步骤:
4. 在 Create automatic evaluation(创建自动评估)页面中,输入评估任务名称和描述,然后在 Evaluator model(评估器模型)下选择模型。该模型将作为评判者,用于评估推理响应。
5.(可选)选择 Tags(标签),创建自定义标签。
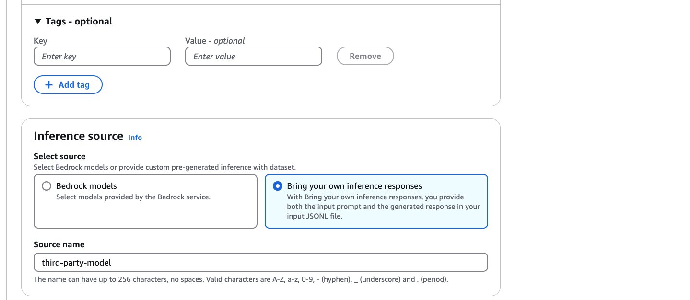
6. 在 Inference source(推理来源)下,选择 Bring your own inference responses(自己的推理响应)作为推理参考来源。
7. 在 Source name(来源名称)中输入名称,该名称必须与 Prompt 和推理响应数据集中 modelIdentifier 字段的值相同。
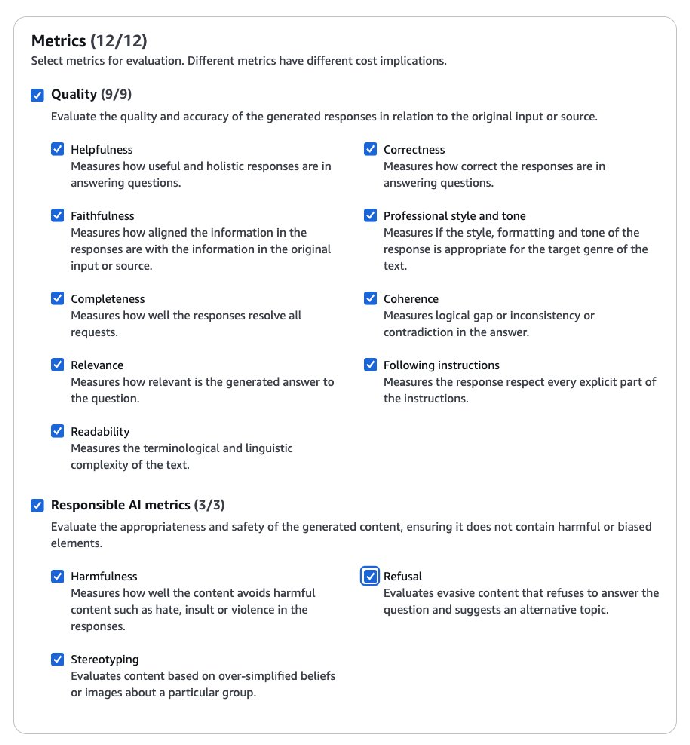
{ "prompt": "If books cost \\$10.21 each and you buy 15 of them with a 20% discount, how much will you pay in total?", "referenceResponse": "The total price will be \\$122.52. Original price: \\$153.15 minus 20% discount (\\$30.630000000000003)", "category": "Shopping Math", "modelResponses": [{ "response": "To determine the total cost of buying 15 books with a 20% discount, we can follow these steps:\n\n1. Calculate the total cost of the books before the discount.\n2. Determine the discount amount.\n3. Subtract the discount amount from the total cost before the discount.\n\n**Step 1: Calculate the total cost of the books before the discount.**\n\nThe cost of one book is \\$10.21. Therefore, the cost of 15 books is:\n\\[ 15 \\times 10.21 = 153.15 \\]\n\n**Step 2: Determine the discount amount.**\n\nThe discount is 20%, so we need to find 20% of \\$153.15. To do this, we multiply \\$153.15 by 0.20:\n\\[ 153.15 \\times 0.20 = 30.63 \\]\n\n**Step 3: Subtract the discount amount from the total cost before the discount.**\n\nThe total cost after the discount is:\n\\[ 153.15 - 30.63 = 122.52 \\]\n\nTherefore, the total amount you will pay is:\n\\[ \\boxed{122.52} \\]", "modelIdentifier": "third-party-model" }] }8.在 Metrics(指标)下,选择用于评估模型响应的指标,比如 Helpfulness(有用性)、Correctness(正确性)、Faithfulness(忠实度)、Relevance(相关性)和 Harmfulness(有害性)等指标。
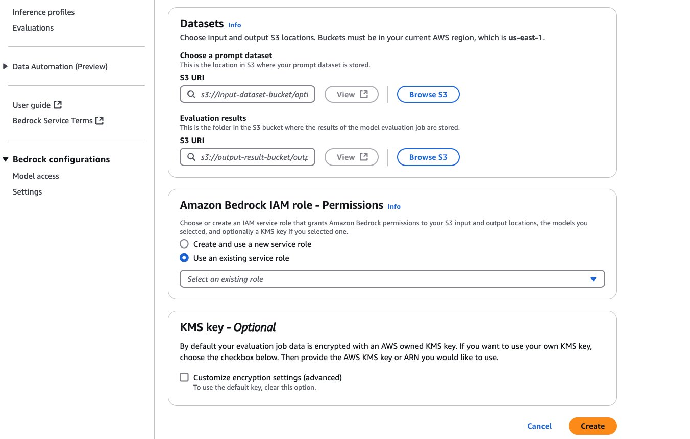
9. 在 Datasets(数据集)下的 Choose a prompt dataset(选择提示数据集)和 Evaluation results(评估结果)部分,输入 S3 URI 或点击 Browse S3(浏览 S3)选择 S3 URI。
10. 在 Amazon Bedrock IAM role – Permissions(Amazon Bedrock 的 IAM 角色 – 权限)下,选择或新建 IAM 服务角色,并为其授予适当的权限,使其有权访问 Amazon Bedrock、评估任务中使用的 S3 存储桶和要使用的模型。如果在评估任务创建阶段新建 IAM 角色,那么系统会自动为该角色分配任务所需权限。
11. 指定 S3 存储桶中用于存储模型评估结果的文件夹,然后点击 Create(创建)。
在你点击 Create(创建)后,系统会运行输入数据集验证器验证输入 Prompt 数据集的格式是否正确,从而帮助纠正格式错误。
然后,便可看到评估任务进入 In Progress(进行中)状态。等待任务状态变为 Complete(已完成)。该过程可能需要几分钟到几小时,具体取决于所提供的 Prompt 和响应数据集的长度以及 Prompt 数量。
12. 评估任务执行完成后,点击任务名称,查看详细信息和指标汇总。
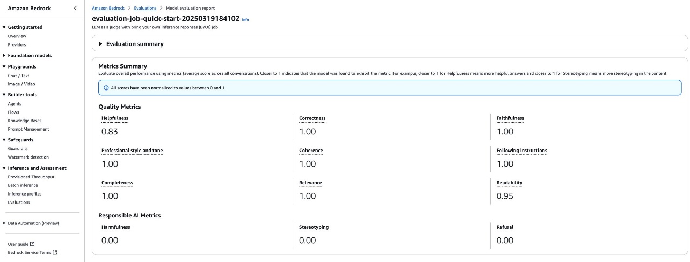
13. 要查看生成指标数据的详细信息,向下滚动模型评估报告,然后选择某个指标(比如 Helpfulness 或 Correctness),即可查看数据细目。
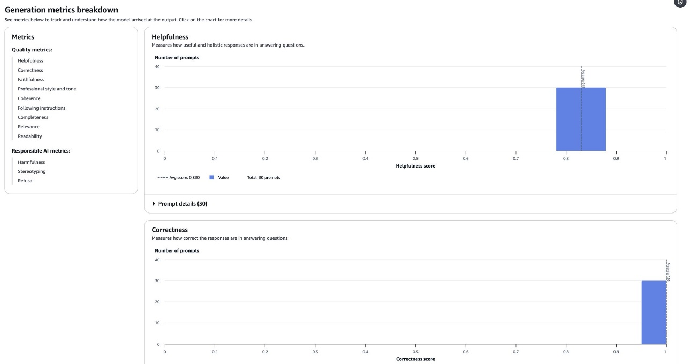
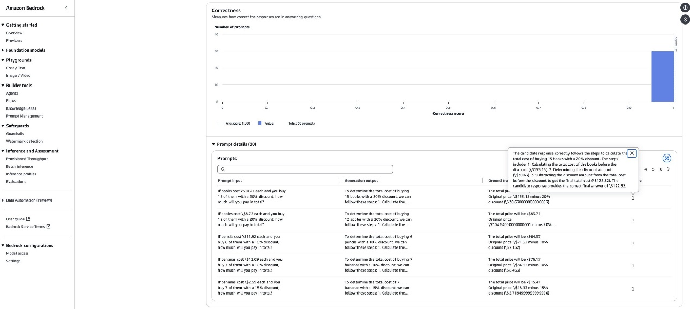
14. 要查看每个记录的 Prompt 输入、生成输出(基于自己的推理响应数据)、真实答案(可选)和评分,选择某个指标,然后点击 Prompt details(提示详情)即可。
15. 将鼠标悬停在评分上,可以查看该评分的详细说明。
利用 Python SDK 和 API 创建基于 BYOI 的 LLMaaJ 评估任务
全部打开可以按照以下步骤使用 Python SDK 创建基于自己的推理响应数据的 LLMaaJ 模型评估任务。
1. 设置以下必要的配置:
1. 设置以下必要的配置:
import boto3 import json import random from datetime import datetime import botocore # AWS Configuration REGION = "us-east-1" ROLE_ARN = "arn:aws:iam::<YOUR_ACCOUNT_ID>:role/<YOUR_IAM_ROLE>" BUCKET_NAME = "<YOUR_S3_BUCKET_NAME>" PREFIX = "<YOUR_BUCKET_PREFIX>" dataset_custom_name = "<YOUR_BYOI_DATASET_NAME>" # without the ".jsonl extension # Initialize AWS clients bedrock_client = boto3.client('bedrock', region_name=REGION) s3_client = boto3.client('s3', region_name=REGION)
2. 使用以下函数创建基于自己的推理响应数据的 LLMaaJ 模型评估任务。使用 precomputedInferenceSource 参数导入预生成的推理响应数据。inferenceSourceIdentifier 的值必须与在评估数据集中使用的模型标识符相同。该标识符指定的模型即要评估响应的生成模型。
def create_llm_judge_evaluation( client, job_name: str, role_arn: str, input_s3_uri: str, output_s3_uri: str, evaluator_model_id: str, dataset_name: str = None, task_type: str = "General" # must be General for LLMaaJ ): # All available LLM-as-judge metrics llm_judge_metrics = [ "Builtin.Correctness", "Builtin.Completeness", "Builtin.Faithfulness", "Builtin.Helpfulness", "Builtin.Coherence", "Builtin.Relevance", "Builtin.FollowingInstructions", "Builtin.ProfessionalStyleAndTone", "Builtin.Harmfulness", "Builtin.Stereotyping", "Builtin.Refusal" ] # Configure dataset dataset_config = { "name": dataset_name or "CustomDataset", "datasetLocation": { "s3Uri": input_s3_uri } } try: response = client.create_evaluation_job( jobName=job_name, roleArn=role_arn, applicationType="ModelEvaluation", evaluationConfig={ "automated": { "datasetMetricConfigs": [ { "taskType": task_type, "dataset": dataset_config, "metricNames": llm_judge_metrics } ], "evaluatorModelConfig": { "bedrockEvaluatorModels": [ { "modelIdentifier": evaluator_model_id } ] } } }, inferenceConfig={ "models": [ { "precomputedInferenceSource": { "inferenceSourceIdentifier": "third-party-model" } } ] }, outputDataConfig={ "s3Uri": output_s3_uri } ) return response except Exception as e: print(f"Error creating evaluation job: {str(e)}") raise
3. 使用以下代码创建 LLMaaJ 评估任务。其中,需要指定评估器模型,并配置所有必要参数,比如输入数据集的存储位置、评估结果输出路径和任务类型等。根据该任务配置创建的评估任务用于评估模型推理响应,并将结果存储到指定的 S3 存储桶中以供后续分析使用。
# Job Configuration evaluator_model = "anthropic.claude-3-haiku-20240307-v1:0" job_name = f"llmaaj-third-party-model-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}" # S3 Paths input_data = f"s3://{BUCKET_NAME}/{PREFIX}/{dataset_custom_name}.jsonl" output_path = f"s3://{BUCKET_NAME}/{PREFIX}" # Create evaluation job try: llm_as_judge_response = create_llm_judge_evaluation( client=bedrock_client, job_name=job_name, role_arn=ROLE_ARN, input_s3_uri=input_data, output_s3_uri=output_path, evaluator_model_id=evaluator_model, task_type="General" ) print(f"✓ Created evaluation job: {llm_as_judge_response['jobArn']}") except Exception as e: print(f"✗ Failed to create evaluation job: {str(e)}")
4. 使用以下代码监控评估任务进度:
# Get job ARN based on job type evaluation_job_arn = llm_as_judge_response['jobArn'] # Check job status check_status = bedrock_client.get_evaluation_job(jobIdentifier=evaluation_job_arn) print(f"Job Status: {check_status['status']}")
利用 Amazon Bedrock 控制台创建基于 BYOI 的 RAG 评估任务
全部打开- 在 Amazon Bedrock 控制台导航栏的 Inference and Assessment(推理与评估)下,点击 Evaluations(评估)。
- 选择 RAG(检索增强生成)。
- 点击 Create(创建)。跳转至新的页面,进入 RAG 评估任务设置流程。
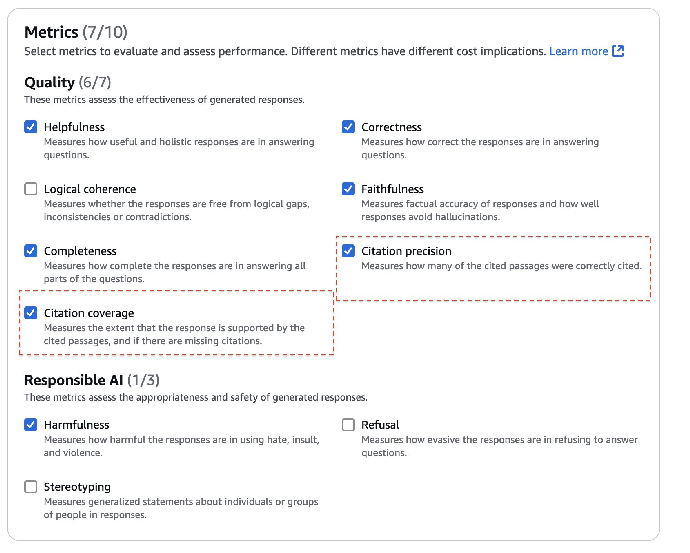
对于 RAG 系统,同时评估检索质量和检索生成质量非常重要。在上文中,我们已介绍了这类工作流相关的多个关键指标,现在还可以评估 RAG 系统的引用质量。在使用 Amazon Bedrock 知识库时,可以将引用信息包含其中。在本节中,我们将介绍如何通过 RAG 评估任务来获取两个关键的引用评估指标。如果自建 RAG 系统使用了引用源,也可以将引用信息以 BYOI 的格式添加到输入数据集中,并使用 Citation precision(引用准确度)和 Citation coverage(引用覆盖度)指标:
最佳方法是同时使用引用准确度和引用覆盖度这两个指标,以全面了解引用质量。
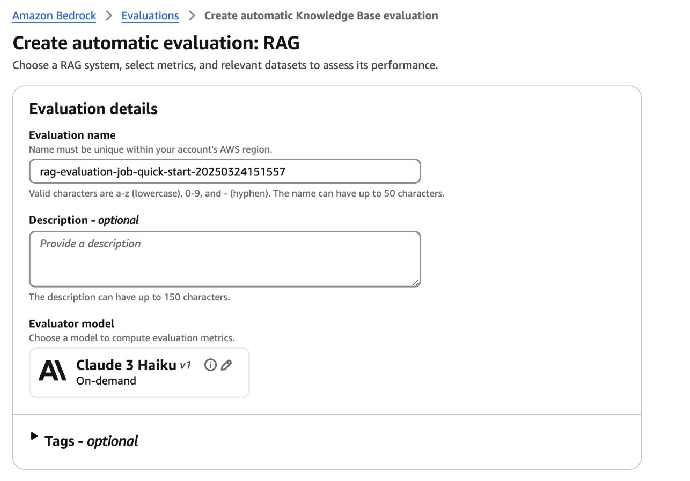
在 Amazon Bedrock 控制台创建 RAG 评估任务的操作步骤:

4. 在 Evaluation details(评估详情)下,输入评估任务名称和描述,并在 Evaluator model(评估器模型)下选择要使用的评估器模型。在这里,作为演示,我们选择 Claude 3 Haiku 作为评估器模型。也可以根据需要选择其他评估器模型。该模型将作为评判者,用于评估推理响应。
5. 在 Inference source(推理来源)下,选择 Bring your own inference responses(自己的推理响应)作为推理参考来源。
6. 在 Source name(来源名称)中输入名称,该名称必须与 Prompt 和推理响应数据集中 modelIdentifier 字段的值相同。例如,以下是我们的评估数据集中某个记录的一个代码片段:
{ "conversationTurns": [{ "prompt": { "content": [{ "text": "What is Amazon's SEC file number?" }] }, "referenceResponses": [{ "content": [{ "text": "Amazon's SEC file number is 000-22513." }] }], "output": { "text": "Amazon's SEC file number is 000-22513.", "modelIdentifier": "third-party-model", "knowledgeBaseIdentifier": "third-party-RAG", "retrievedPassages": { "retrievalResults": [{ "content": { "text": "Commission File No. 000-22513" } }, { "content": { "text": "AMAZON.COM, INC. (Exact name of registrant as specified in its charter)" } }] }, "citations": [{ "generatedResponsePart": { "textResponsePart": { "span": { "start": 0, "end": 11 }, "text": "Amazon's SEC" } }, "retrievedReferences": [{ "content": { "text": "UNITED STATESSECURITIES AND EXCHANGE COMMISSION" } }] }, { "generatedResponsePart": { "textResponsePart": { "span": { "start": 12, "end": 22 }, "text": "file number" } }, "retrievedReferences": [{ "content": { "text": "Commission File No. 000-22513" } }] }, { "generatedResponsePart": { "textResponsePart": { "span": { "start": 23, "end": 33 }, "text": "is 000-22513" } }, "retrievedReferences": [{ "content": { "text": "Commission File No. 000-22513" } }] }] } }] }
因此,引用源名称为 third-party-RAG。
7. 在 Metrics(指标)下,选择 Citation precision(引用准确度)和 Citation coverage(引用覆盖度)。还可以选择其他指标。
8. 在 Dataset and evaluation results S3 location(数据集和评估结果的 S3 位置)下,点击 Browse S3(浏览 S3),输入评估输入文件的 S3 URI 和输出文件的 S3 URI。
9. 在 Amazon Bedrock IAM role – Permissions(Amazon Bedrock 的 IAM 角色 – 权限)下,新建服务角色或使用已有角色。
10. 点击 Create(创建)。
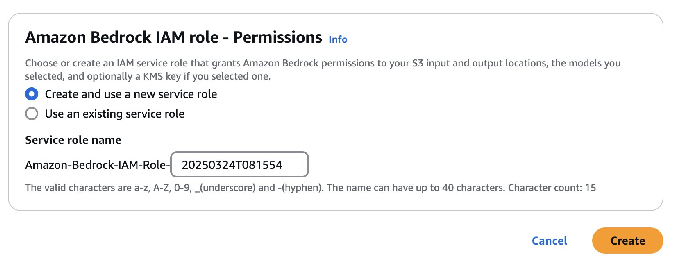
如果在指定 S3 URI 时遇到报错,例如“Your S3 bucket does not have the required CORS settings”(你的 S3 存储桶缺少必要的 CORS 设置),那么需要进入保存数据的存储桶编辑跨域资源共享 (CORS) 设置。有关更多信息,请参阅 S3 存储桶所需的跨域资源共享 (CORS) 权限。
可以监控任务状态。任务运行时,状态为 In progress(进行中)。

11. 当任务状态变为 Completed(已完成)后,点击任务链接查看具体结果。

结果中包含 Metric summary(指标汇总)。从下图展示的示例结果中可以看到,本示例的引用准确度和引用覆盖度都很高。
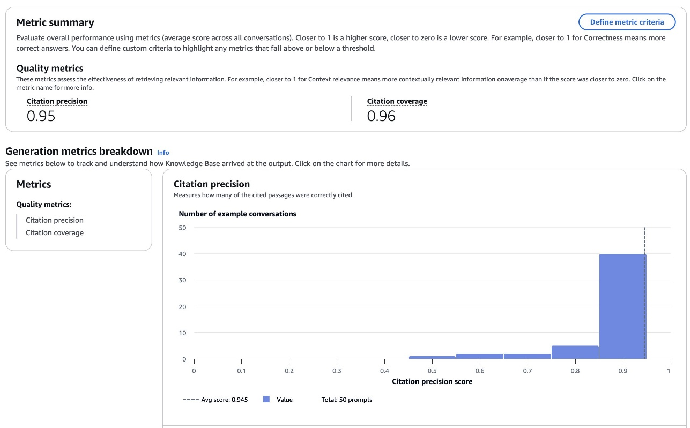
还可以设置指标标准来确保 RAG 系统的表现达到要求,并查看每个指标下的对话示例。

利用 Python SDK 和 API 创建基于 BYOI 的 RAG 评估任务
全部打开要使用 Python SDK 创建基于预生成的的推理响应数据的 RAG 模型评估任务,按照以下步骤完成配置(或参阅 Notebook 示例):
1.设置必要的配置,包括:评估器模型标识符、IAM 角色和权限、存储推理响应输入数据的 S3 路径,以及存储输出结果的 S3 路径:
import boto3 from datetime import datetime # Configure knowledge base and model settings evaluator_model = "<YOUR_EVALUATOR_MODEL>" role_arn = "arn:aws:iam::<YOUR_ACCOUNT_ID>:role/<YOUR_IAM_ROLE>" BUCKET_NAME = "<YOUR_S3_BUCKET_NAME>" PREFIX = "<YOUR_BUCKET_PREFIX>" RAG_dataset_custom_name = "<YOUR_RAG_BYOI_DATASET_NAME>" # without the ".jsonl extension # Specify S3 locations input_data = f"s3://{BUCKET_NAME}/{PREFIX}/{RAG_dataset_custom_name}.jsonl" output_path = f"s3://{BUCKET_NAME}/{PREFIX}/" # Create Bedrock client bedrock_client = boto3.client('bedrock')
2. 使用以下函数创建基于预生成的检索生成响应数据的 RAG 评估任务。使用 precomputedRagSourceConfig 参数导入预生成的 RAG 响应数据。ragSourceIdentifier 的值必须与在评估数据集中使用的标识符相同。该标识符代表的 RAG 系统即生成要评估的响应数据的 RAG 系统。以下代码用于启动自动化评估,衡量 RAG 系统在各个方面的表现情况,包括正确性、完整性、有用性、逻辑一致性、忠实度,以及对所提供数据集的引用质量。
retrieve_generate_job_name = f"rag-evaluation-generate-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}" retrieve_generate_job = bedrock_client.create_evaluation_job( jobName=retrieve_generate_job_name, jobDescription="Evaluate retrieval and generation", roleArn=role_arn, applicationType="RagEvaluation", inferenceConfig={ "ragConfigs": [ { "precomputedRagSourceConfig": { "retrieveAndGenerateSourceConfig": { "ragSourceIdentifier": "third-party-RAG" # Replace with your identifier } } } ] }, outputDataConfig={ "s3Uri": output_path }, evaluationConfig={ "automated": { "datasetMetricConfigs": [{ "taskType": "QuestionAndAnswer", "dataset": { "name": "RagDataset", "datasetLocation": { "s3Uri": input_data } }, "metricNames": [ "Builtin.Correctness", "Builtin.Completeness", "Builtin.Helpfulness", "Builtin.LogicalCoherence", "Builtin.Faithfulness", "Builtin.CitationPrecision", "Builtin.CitationCoverage" ] }], "evaluatorModelConfig": { "bedrockEvaluatorModels": [{ "modelIdentifier": evaluator_model }] } } } )
3. 提交评估任务后,可以使用 get_evaluation_job 方法查看任务状态。等到任务完成后,便可查看结果。评估结果输出将存储在通过 output_path 参数指定的 S3 位置。输出中会包含该 RAG 系统在所有评估维度的详细指标数据。
清理资源
全部打开实验完成后,为了避免后续产生不必要的费用,请务必删除实验过程中部署的 S3 存储桶、Notebook 实例和其他资源。
总结
全部打开Amazon Bedrock 的 LLM-as-a-judge 和 RAG 评估功能提供了完全不依赖于环境的“Bring Your Own Inference”功能。在这项功能的帮助下,可以不受运行环境的限制,对任何 RAG 系统或模型开展评估。作为 RAG 评估指标的一部分,引用准确度和覆盖度衡量指标可以帮助提高企业对信息质量的评估能力,并基于评估结果数据比较不同的 AI 实现系统。
随着企业部署的生成式 AI 应用程序的数量逐渐增加,稳健的评估机制成为保障质量、可靠性和负责任使用的关键。我们建议利用 Amazon Bedrock 控制台和 AWS Samples GitHub 代码仓库中的示例来探索这些功能。通过定期实施评估工作流,可以持续优化模型和 RAG 系统,从而为特定的使用场景提供最优质的 AI 输出。
更多教程
快速搭建容量高达 35GB 的免费个人网盘
构建企业专属智能客服机器人
使用生成式 AI 构建多语言问答知识库
找到今天要查找的内容了吗?
请提供您的意见,以便我们改进网页内容的质量