- AWS
- 入门资源中心
使用 Dify 开源版本集成 Amazon Bedrock 开启生成式 AI 之旅
本教程介绍了多个通过 Dify 实现的简易 AI 使用场景,以及如何部署 Dify 开源版本,并集成 Amazon Bedrock 中的 Llama 模型实现这些功能。
关于本教程
难度: 100 - 初级
时间: 20 分钟
所需费用: 所需费用为 Amazon EC2 运行费用(约 0.16 USD/小时),及 Bedrock 按需收费所产生的费用(依据不同语言模型费用不同,请参考 Amazon Bedrock 定价)
上次更新时间: 2024 年 8 月 19 日
相关产品: Amazon EC2, Amazon Bedrock
Dify 是一款开源的大语言模型 (LLM) 应用开发平台
它融合了后端即服务 (Backend as Service) 和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。
Dify 内置了构建 LLM 应用所需的关键技术栈,包括对多种模型的支持、直观的 Prompt 编排界面、高质量的 RAG 引擎、稳健的 Agent 框架、灵活的流程编排,并同时提供了一套易用的界面和 API。这为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上。
技术架构
部分使用场景展示
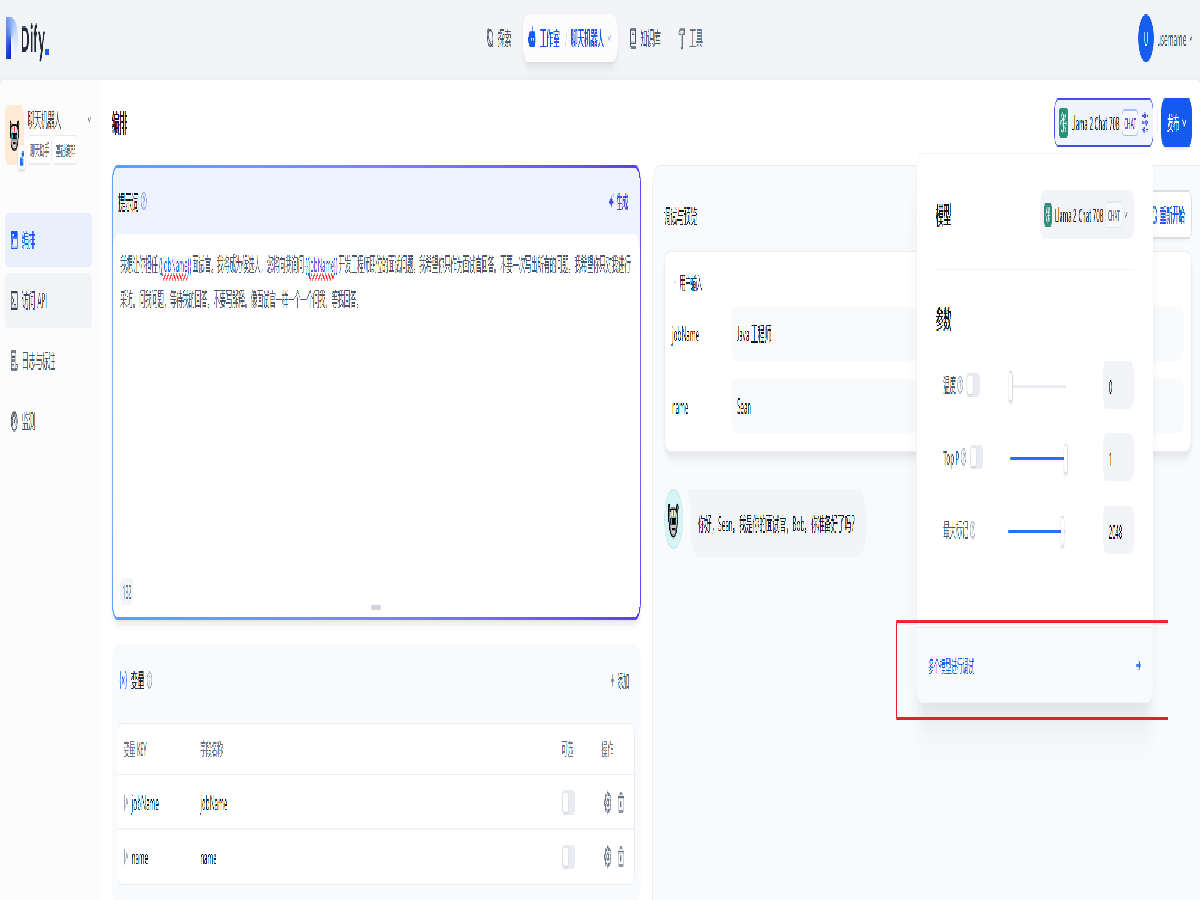
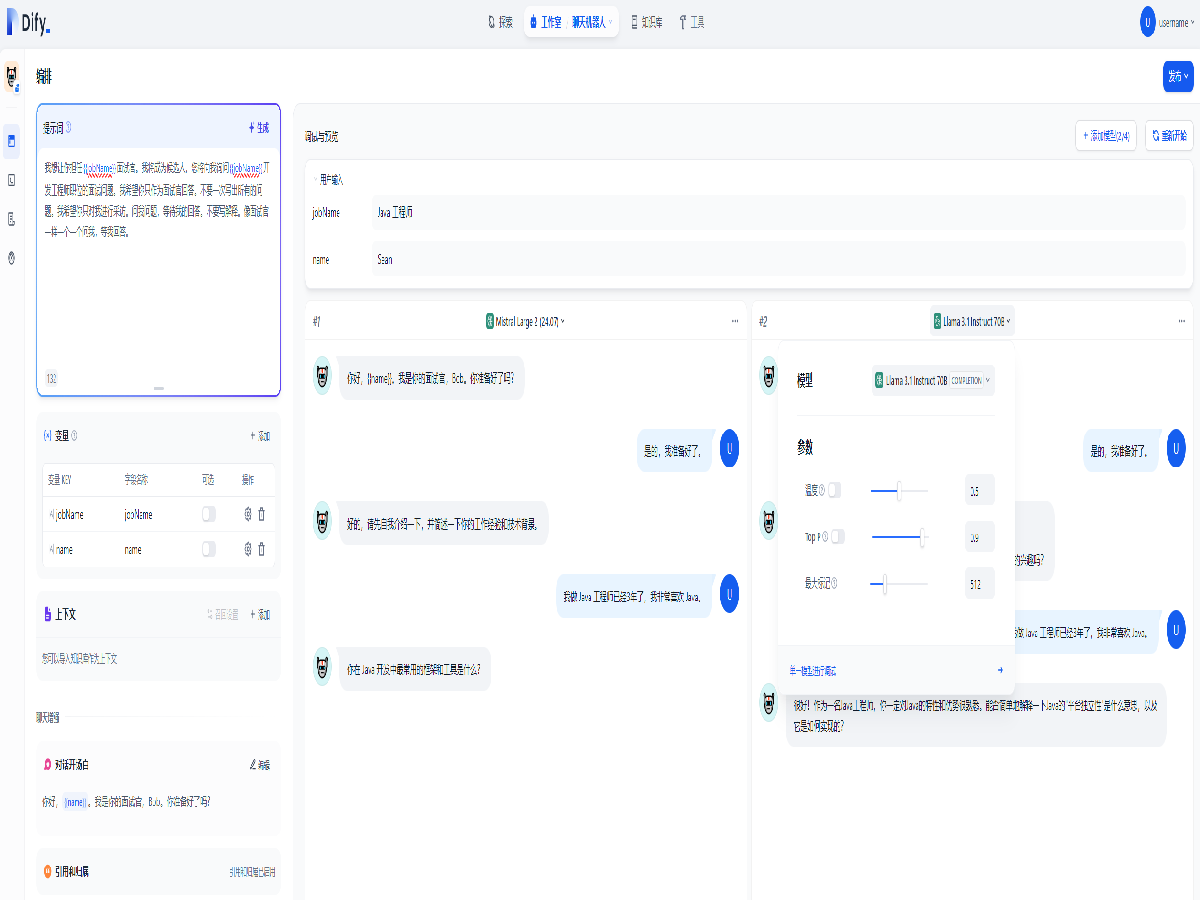
全部打开通过 Dify 部署一个用于模拟面试的对话型应用,进行模拟面试,还可以切换模型,开启模型对比,以及微调模型参数,以便模拟不同的面试过程。
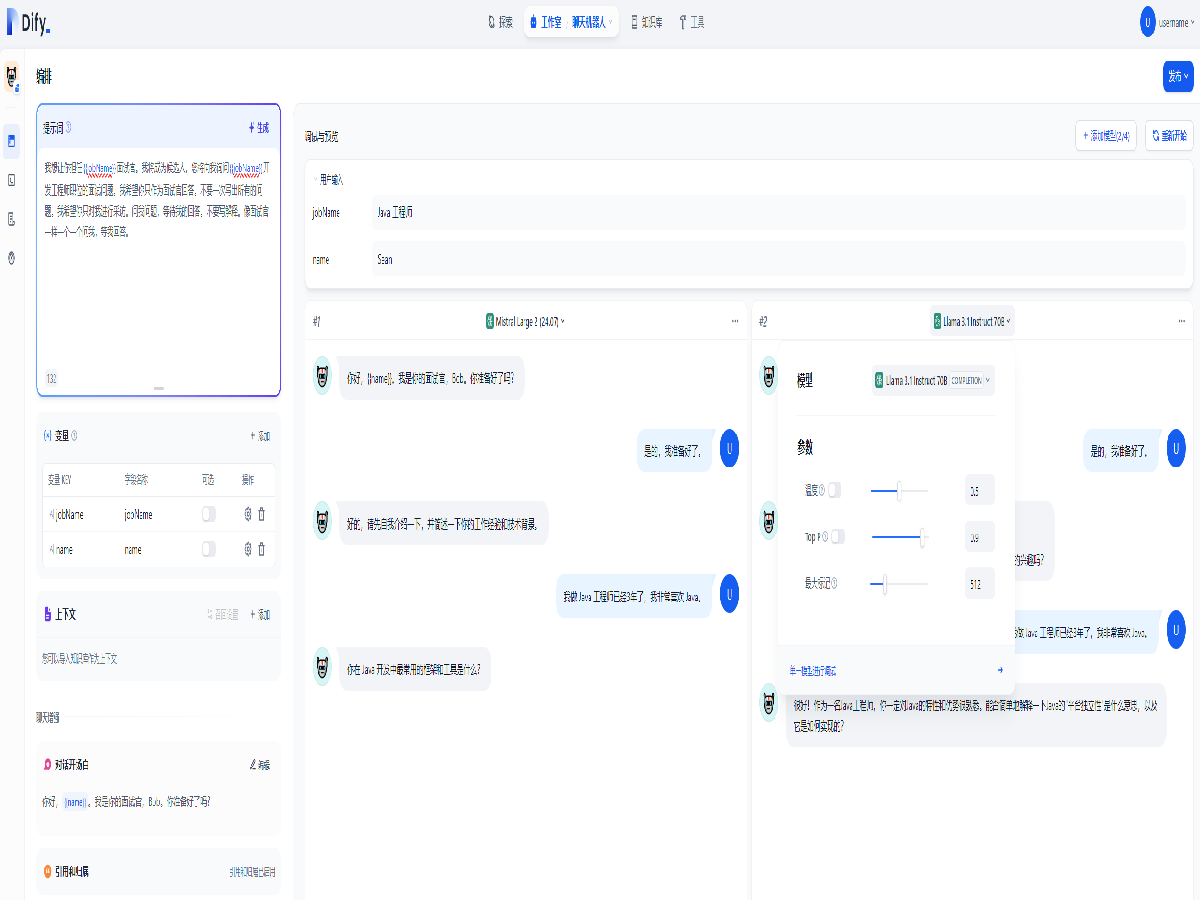
利用大语言模型的推理能力,能够自主对复杂的任务进行处理。我们构建了一个可以查阅雅虎股票信息和新闻频道内容的智能助手应用,并向它提问。智能助手会展示自己的思考过程,以及对问题的解答。
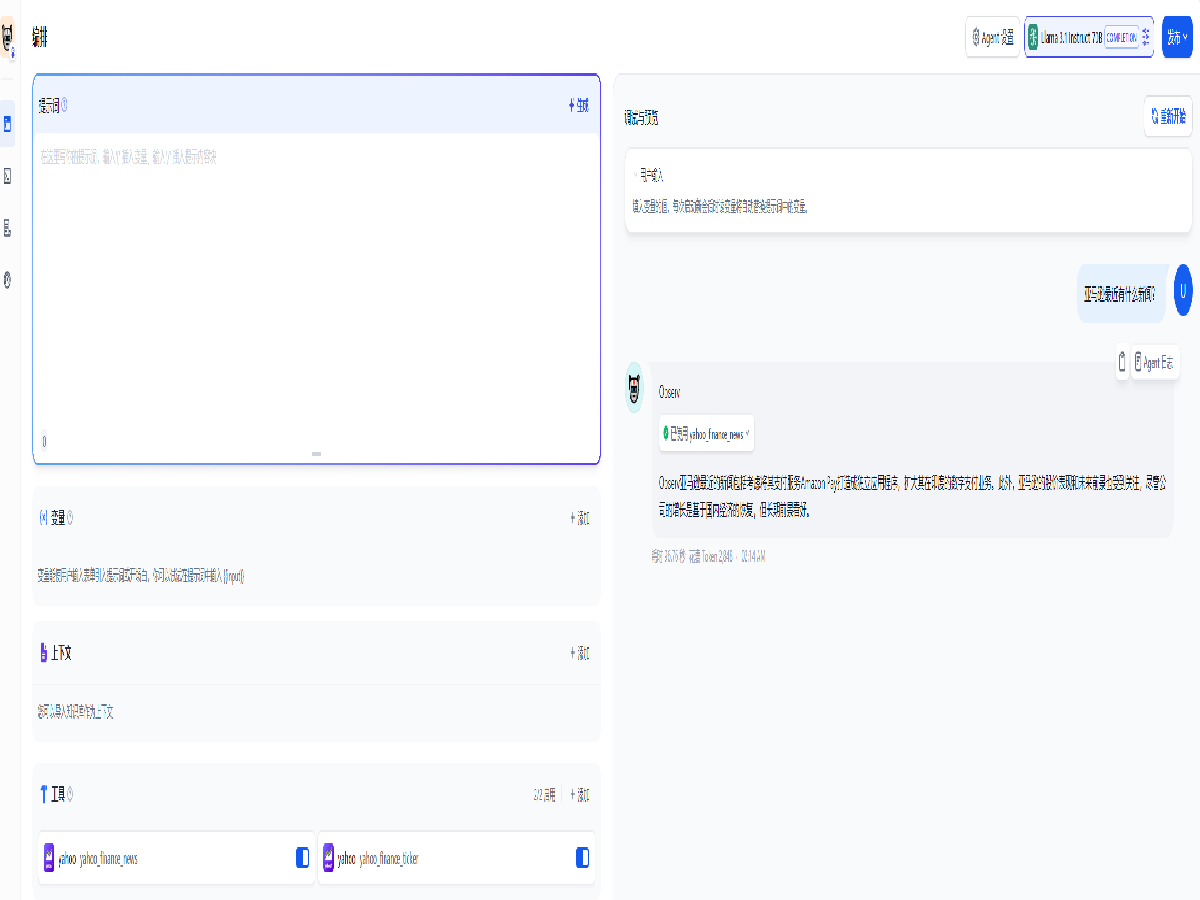
Dify 还可以利用大语言模型进行复杂的翻译,教程中展示了简单的单语种翻译场景,利用多个不同的变量,还可以进行更复杂的翻译需求。
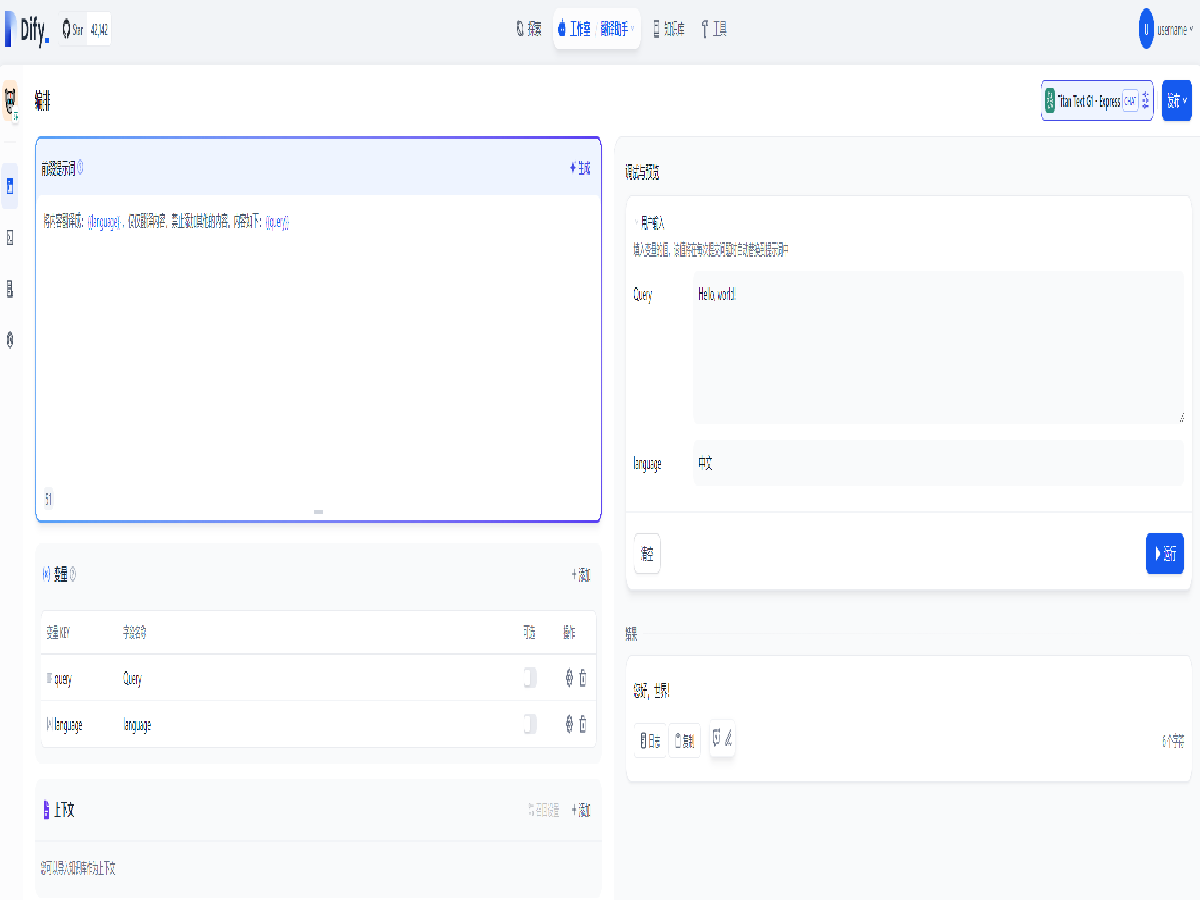
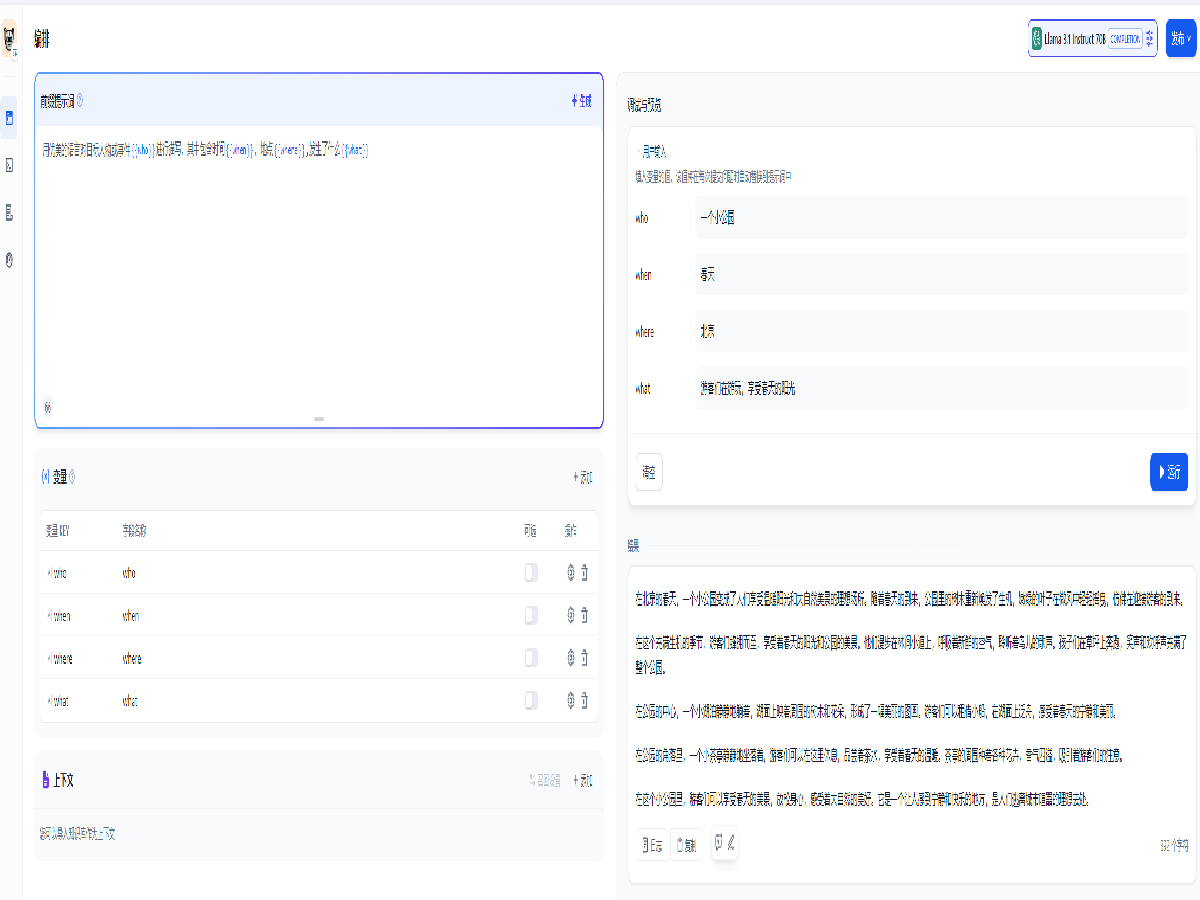
Dify 还可以利用大语言模型进行文字创作,利用多个变量和上下文,可以实现多场景的快速创作,添加提示词如下,并确认自动添加变量:
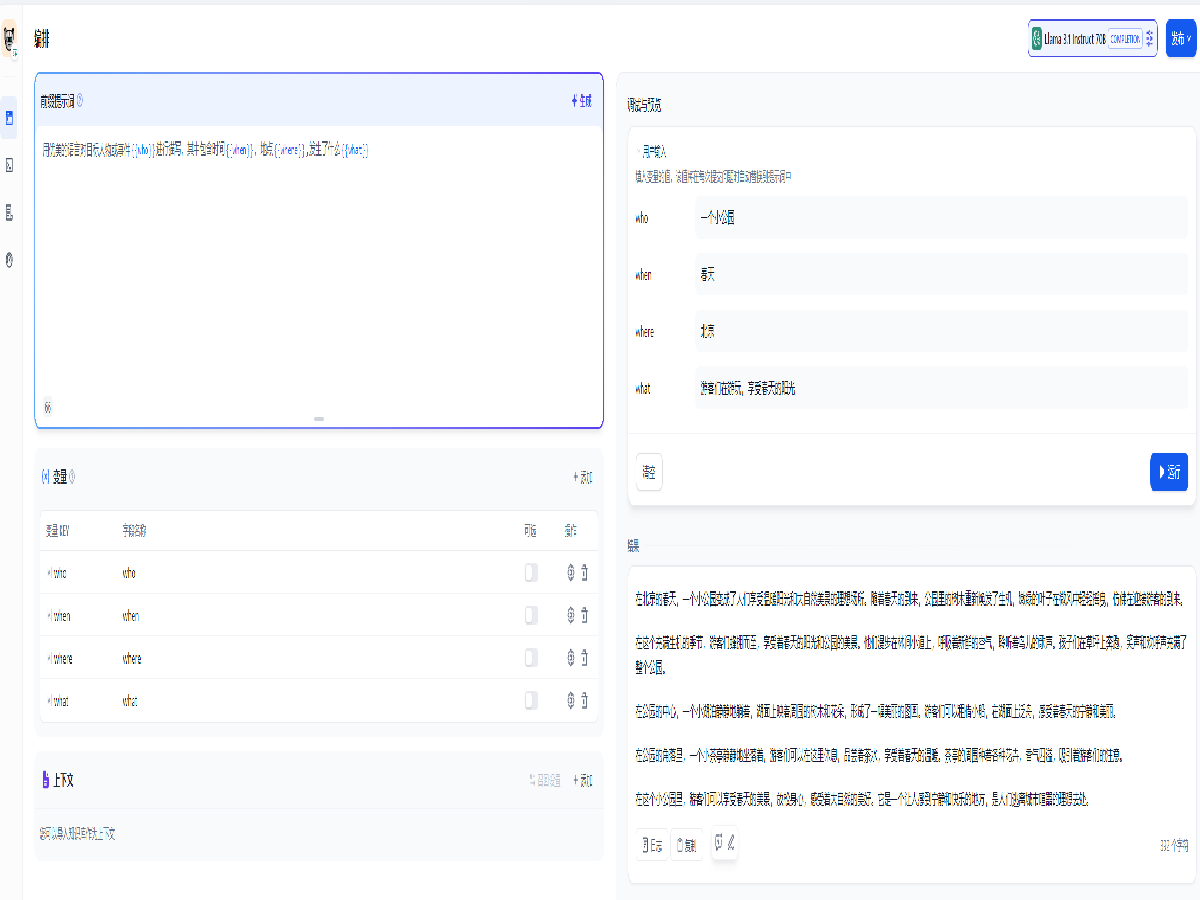
用优美的语言对目标人物或事件{{who}}进行描写,其中包含时间{{when}},地点{{where}},发生了什么{{what}}
然后在右侧输入变量的值,即可生成文本。
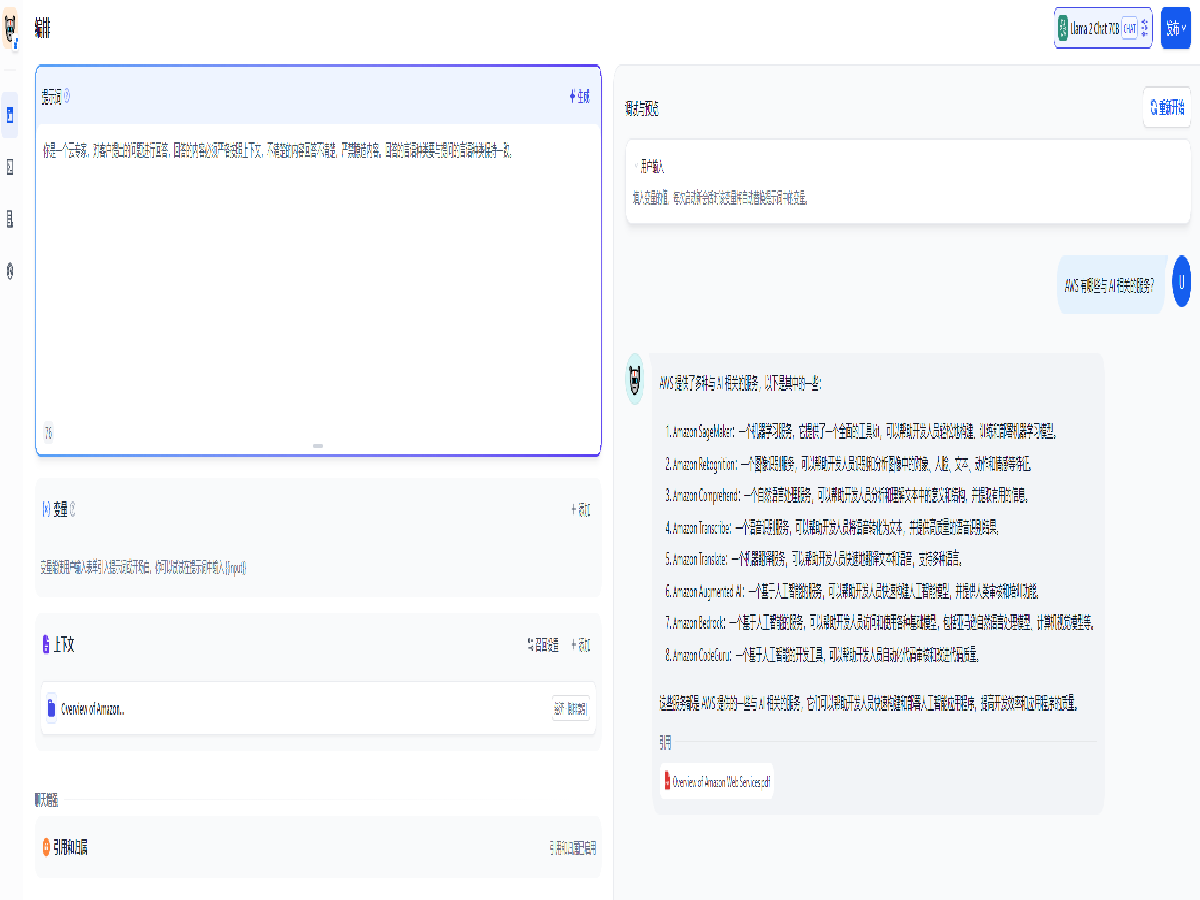
Dify 还可以使用本地上传的方式引入知识库,以摆脱大语言模型的数据时效性和 Token 长度限制,我们创建了一个聊天应用并在上下文中添加知识库,可以看到模型在知识库里面查找了内容后回答了我们提出的问题。
除此之外,您还可以通过部署工作流等功能实现更加复杂,定制化的 AI 需求。
环境准备
全部打开Dify 开源版本提供 Docker Compose 部署或本地部署,本教程将使用 Docker Compose 方式进行部署。因此我们需准备一个 EC2 实例,同时在 Amazon Bedrock 中开启所需模型的访问权限。
注意:如果您打算使用第三方模型,可跳过此步骤至第二步:启动 Amazon EC2 实例
参考此教程中第一步 - 设置请求访问模型中的步骤,开通所需的 Llama 模型的权限。注意:务必同时开启对 Amazon Titan 全部模型的访问,因为 Dify 在验证模型使用权限时会验证对 amazon.titan-text-express-v1 的访问权限。
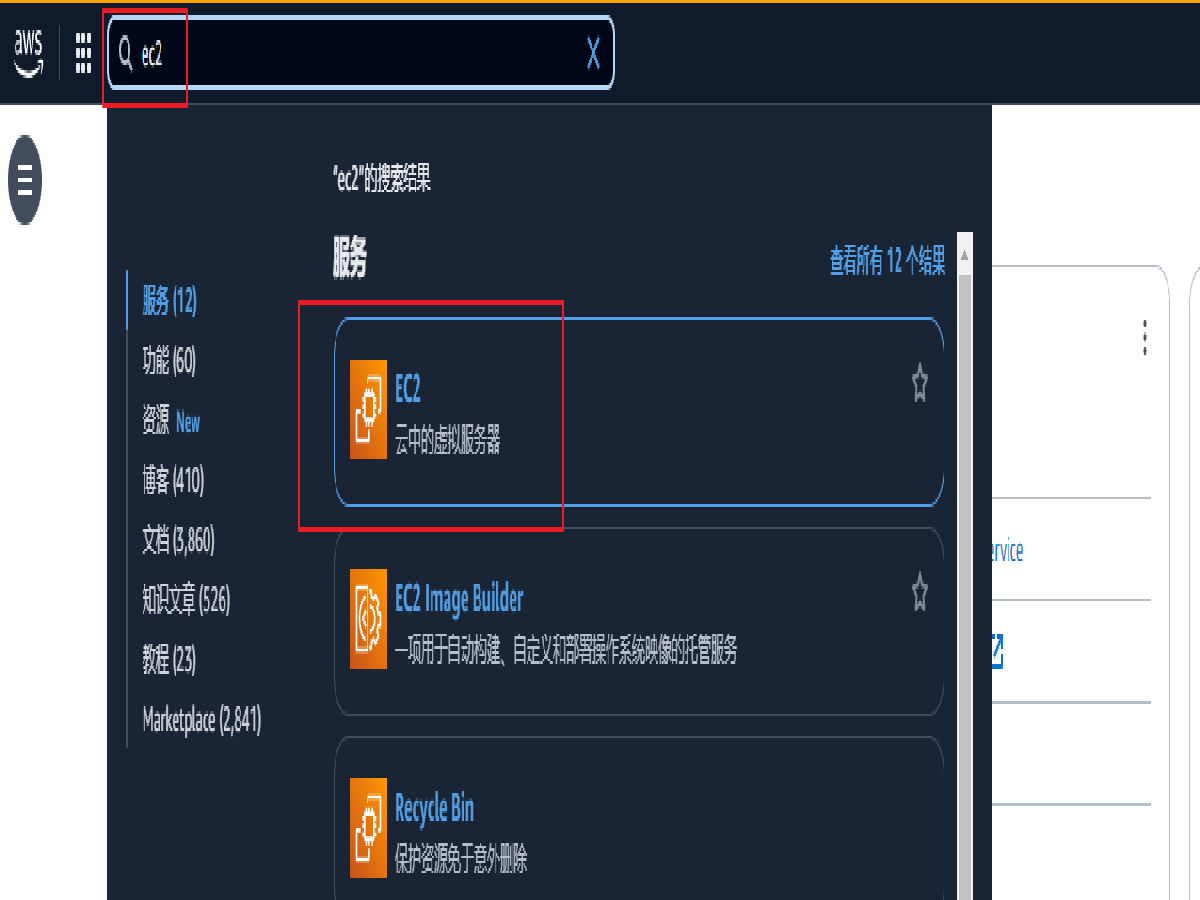
登录进入 AWS 控制台,在上方搜索框输入 EC2,然后点击搜索结果中的 EC2 进入 Amazon EC2 控制台。
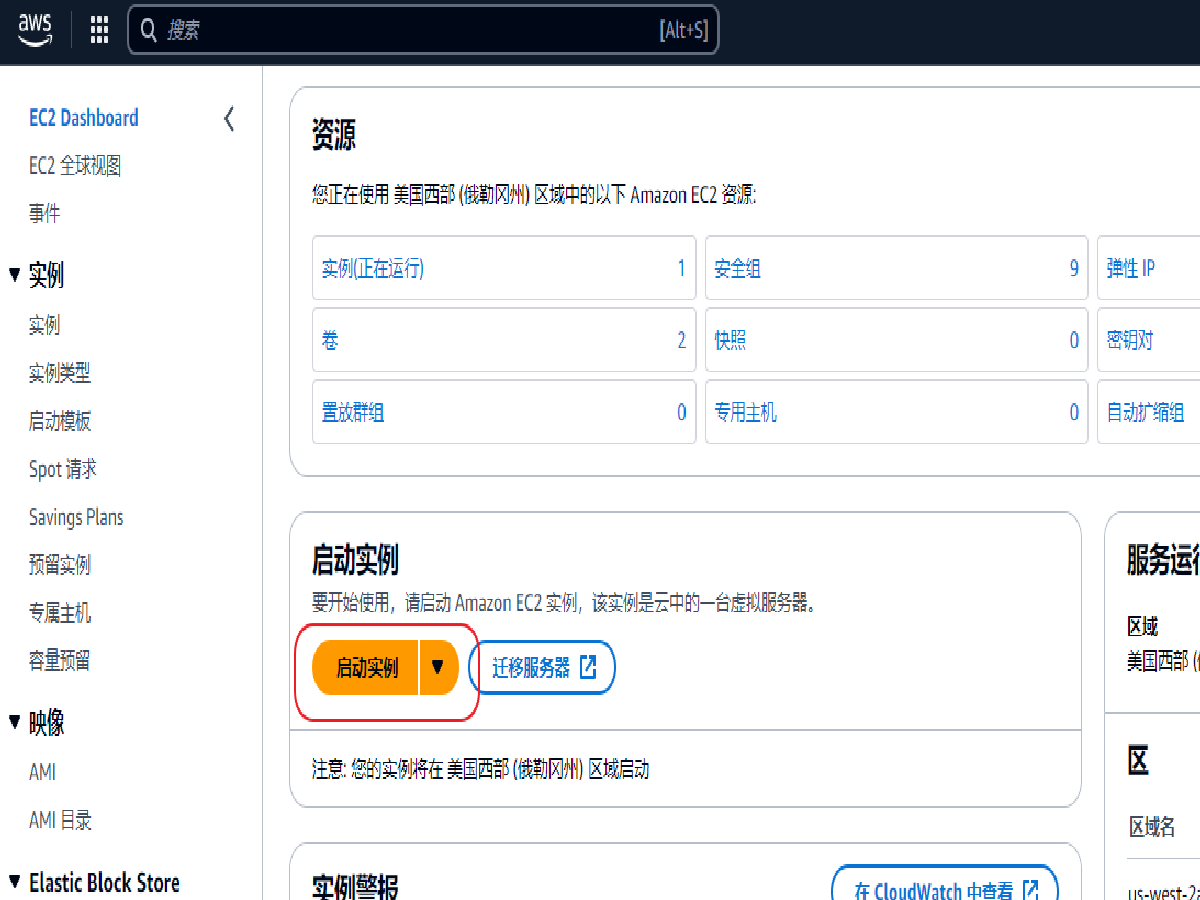
点击 启动实例 按钮,进入启动实例页面。
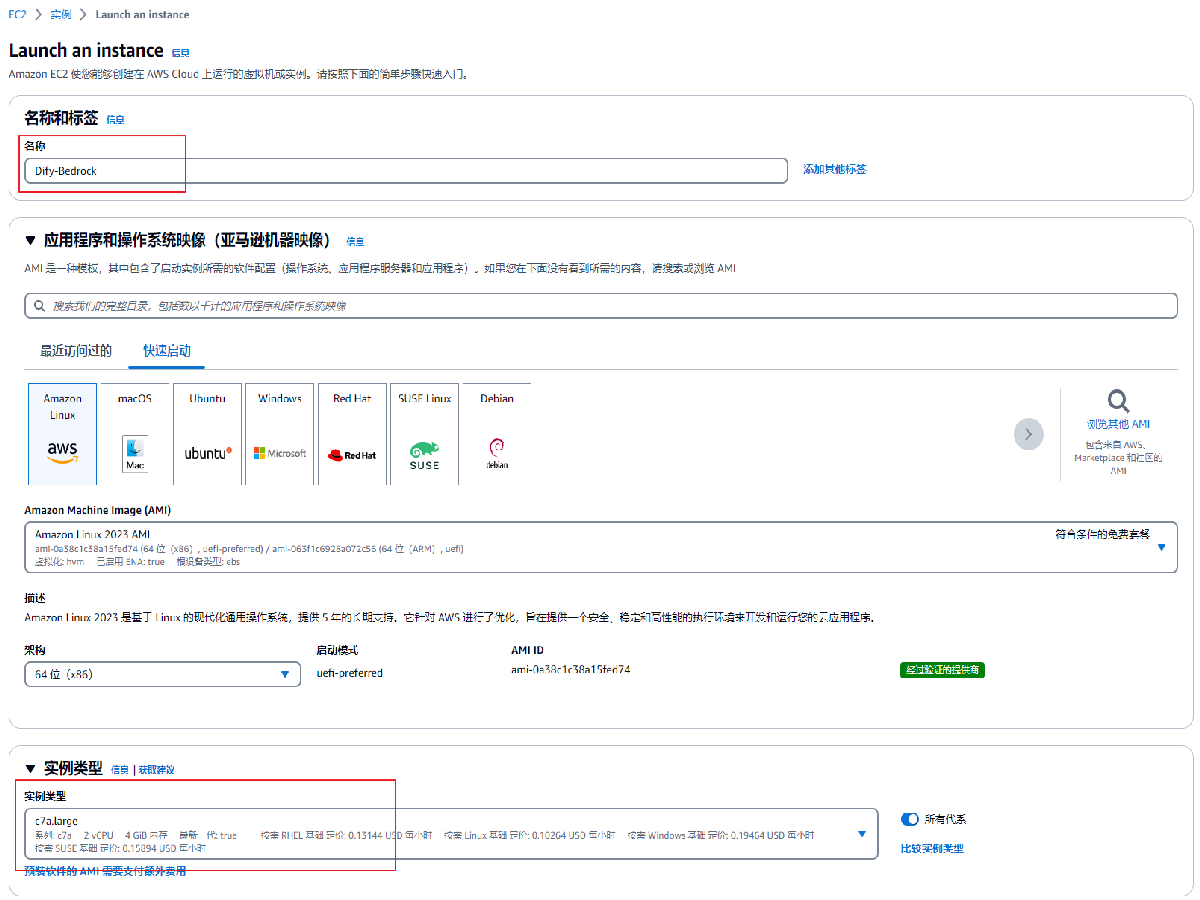
在启动实例页面中,依照下述设置配置 EC2 实例。
名称: 输入此实例的名称,示意图中为“Dify-Bedrock”
应用程序和操作系统映像:选择默认的 Amazon Linux,AMI 选择默认的 Amazon Linux 2023 AMI,架构选择默认的 64位(x86)
实例类型:选择 c7a.large
密钥对:选择 在没有密钥对的情况下继续(不推荐),注意:如果您打算在教程完成后长期使用 Dify,请点击右侧的 创建新密钥对 创建密钥对以便使用 SSH 链接到 EC2 实例。具体流程请参考此文档。
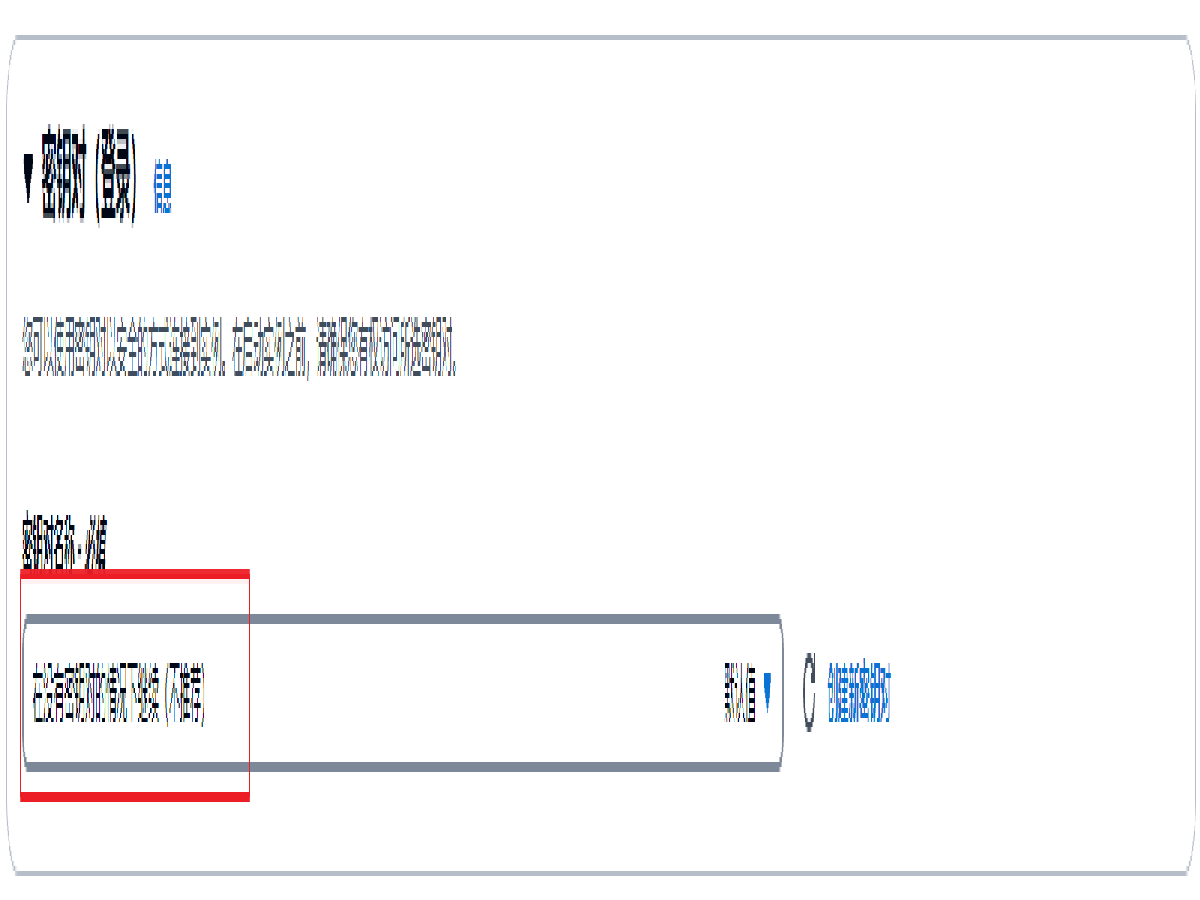
网络设置:默认选择 创建安全组,默认勾选 允许来自以下对象的 SSH 流量,来源为 任何位置 0.0.0.0/0,勾选 允许来自互联网的 HTTP 流量
配置存储与高级详细信息无需更改,保持默认选项即可。
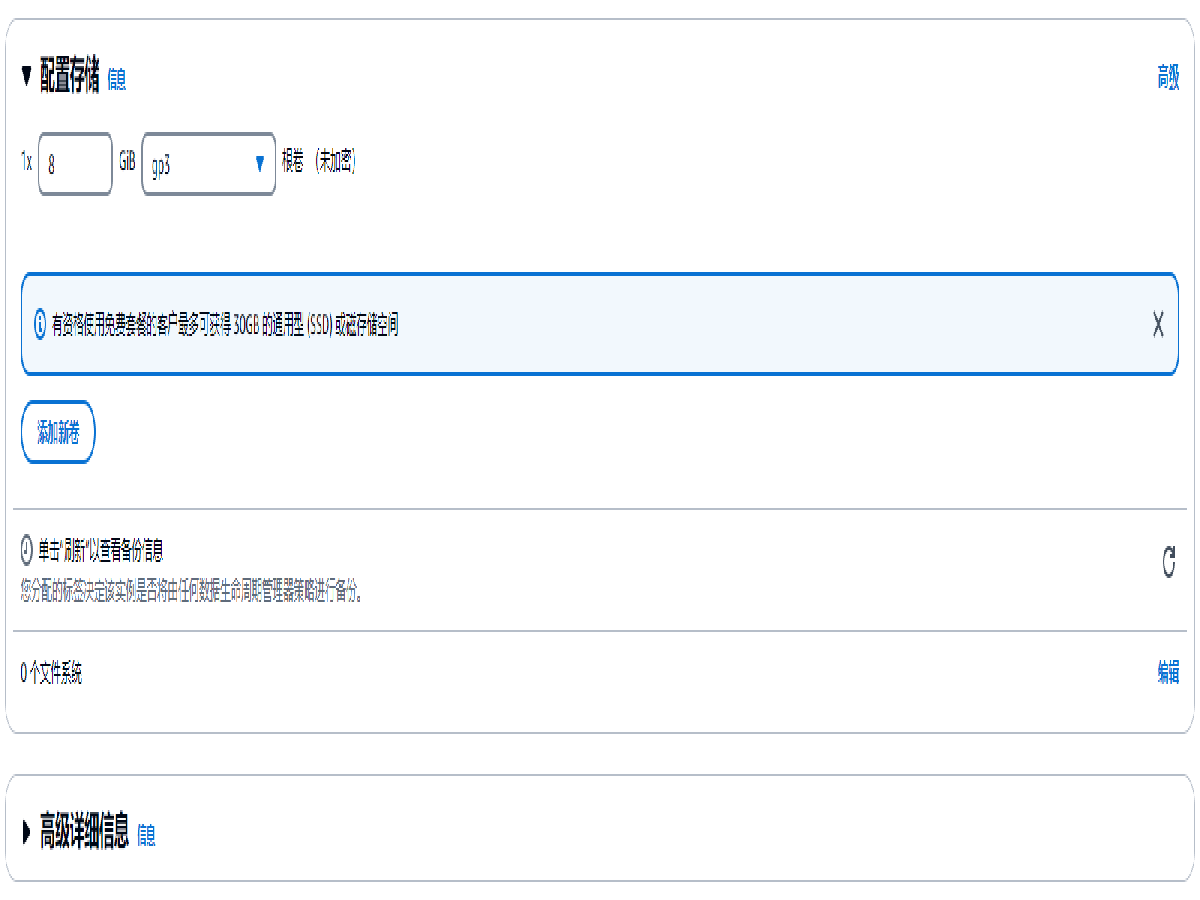
点击摘要中的 启动实例 按钮,启动实例
实例启动成功后会在页面中显示消息提醒,点击链接到实例按钮即可连接到实例进行下一步部署。
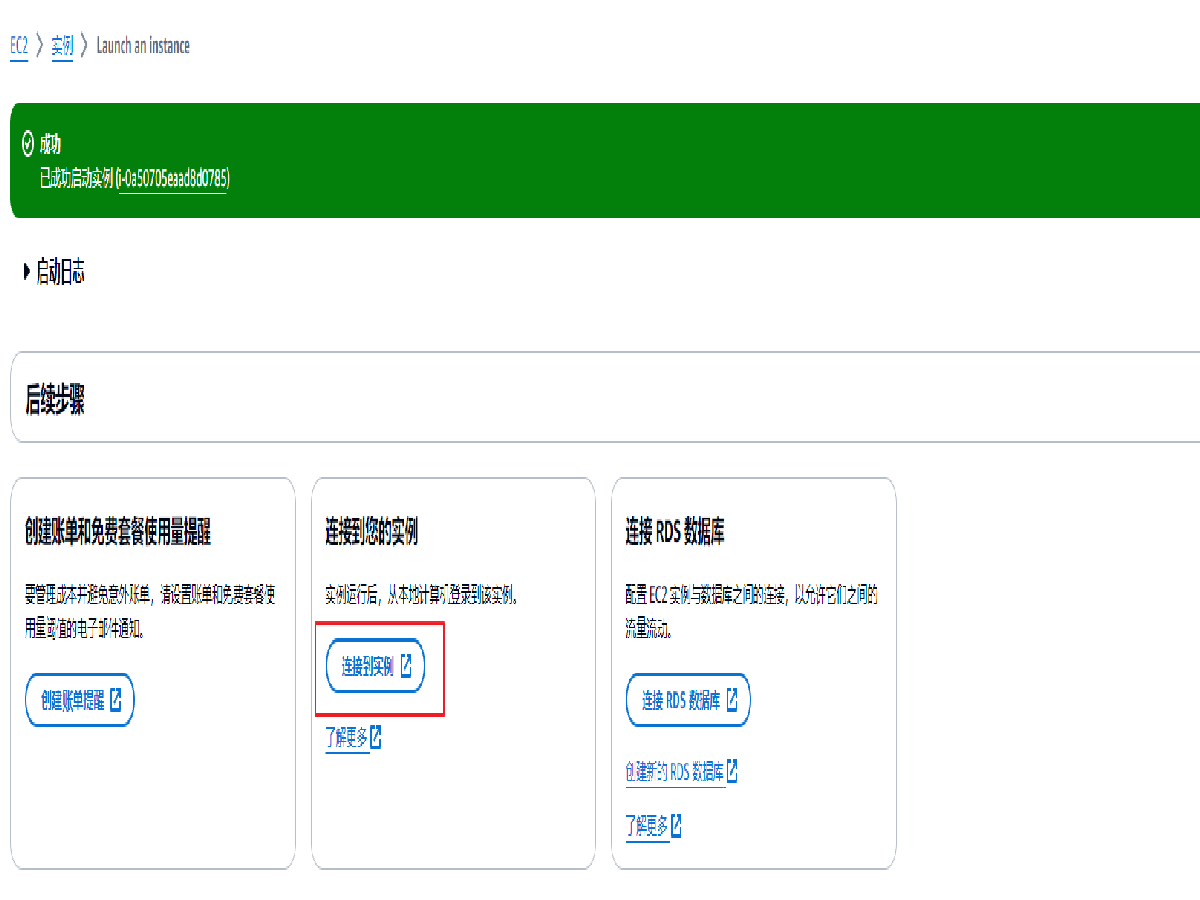
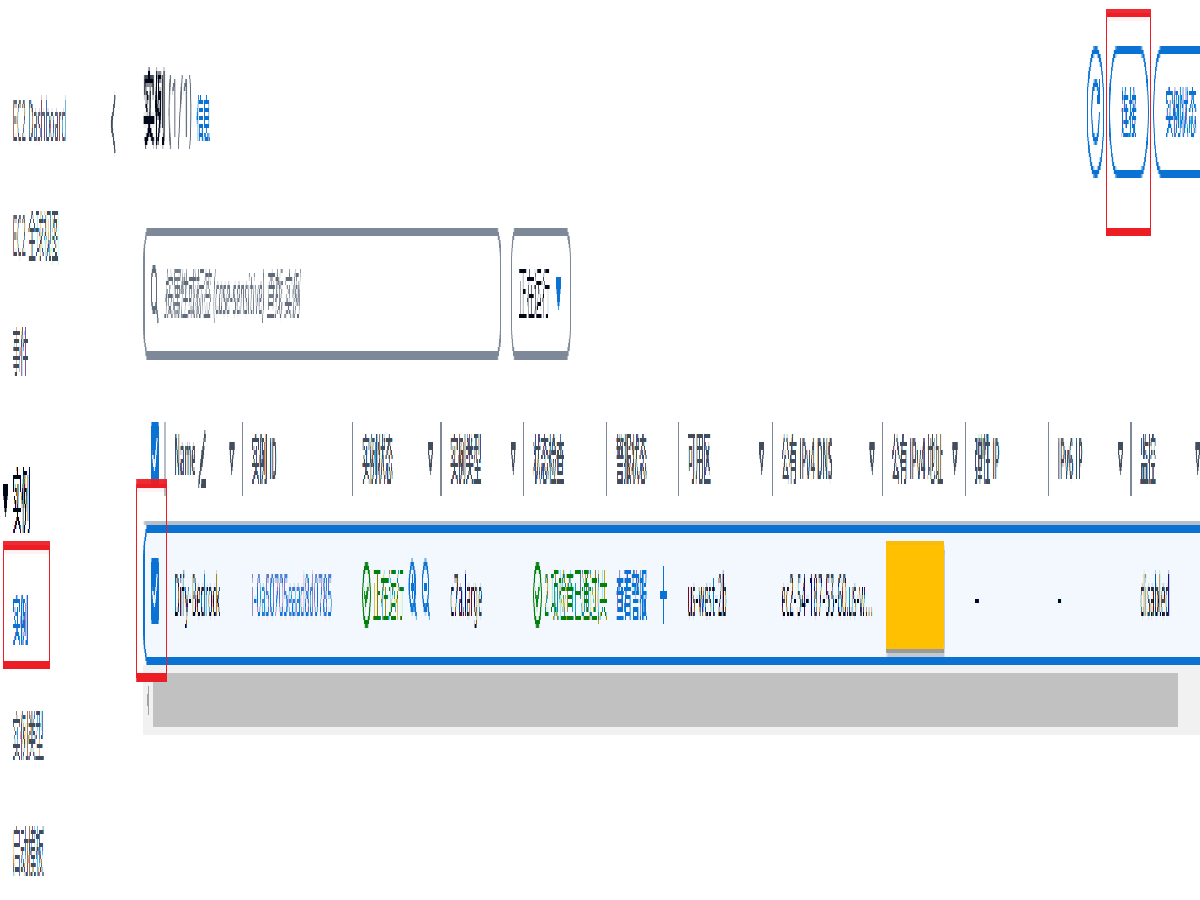
也可以在 EC2 控制台,选择实例进行连接。注意:此处的公有 IPv4 地址为稍后使用的登录地址。
部署 Dify
全部打开通过 SSH 连接 EC2 实例后,安装 Docker 环境。
sudo yum install -y docker
sudo curl -L https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
sudo systemctl start docker
sudo systemctl enable docker然后检查是否成功安装。
docker-compose version ##输出结果为
Docker Compose version v2.29.1sudo yum install -y git
git clone https://github.com/langgenius/dify.git
cd dify/docker
sudo docker-compose up -d几分钟后,可以看到类似的输出。
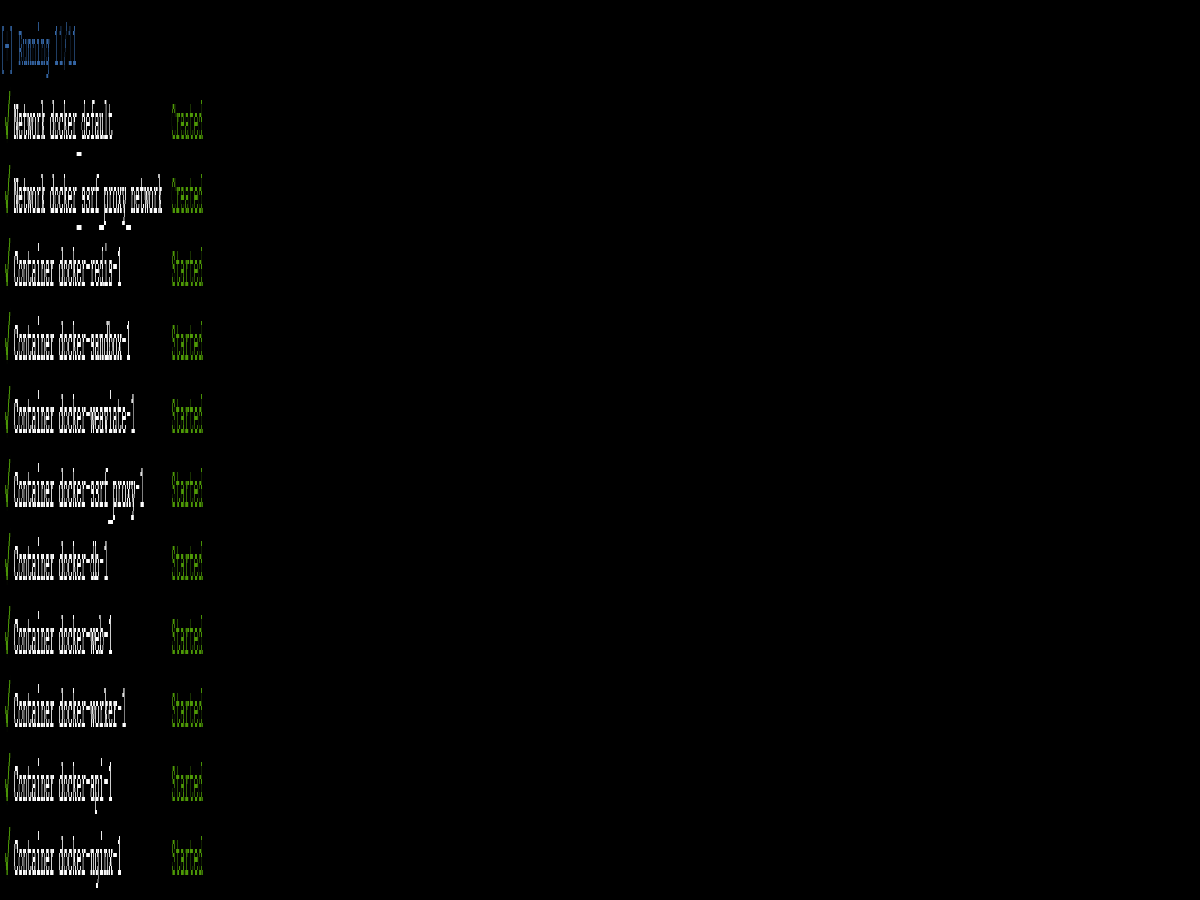
查看进程信息
sudo docker ps可以看到类似的输出。
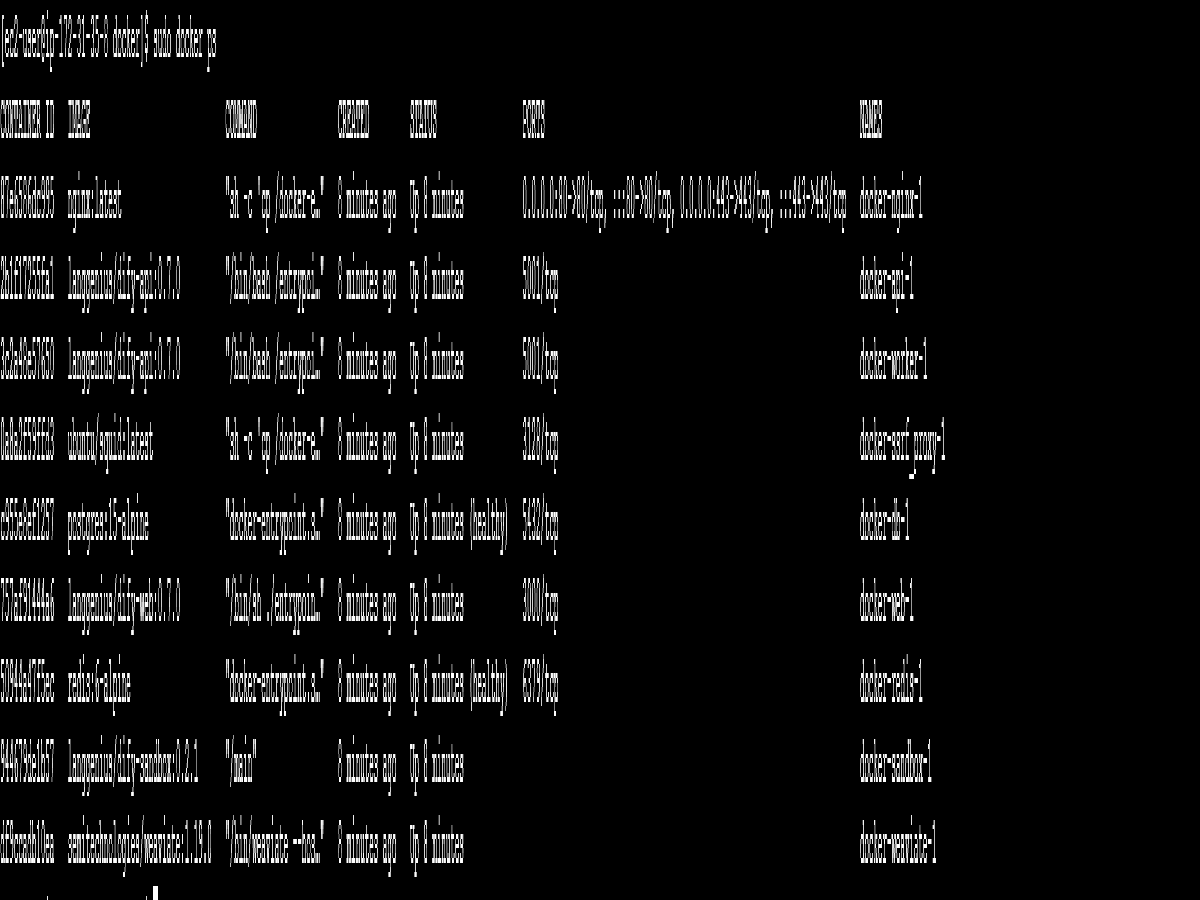
此时,Dify 开源版本已经部署完毕。
Dify 基本设置
全部打开使用浏览器访问 http://{公有IPv4地址},即可看到 Dify 设置界面
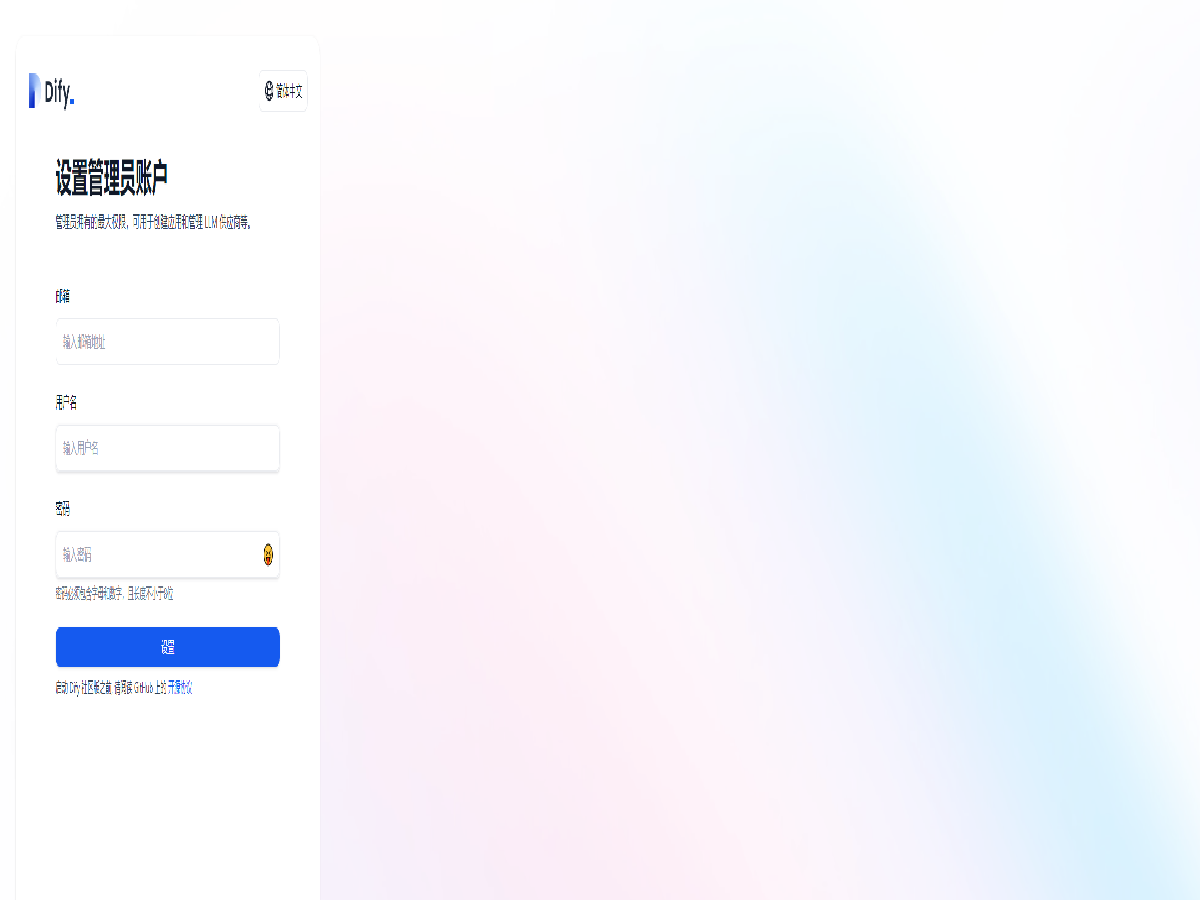
设置好管理员账号的邮箱,用户名和密码后,在登录界面输入邮箱及密码即可进入 Dify 默认界面。
- Access Key / Secret Access Key 的获取过程请参考此教程。
- 验证模型可用性需用到 Amazon Titan 模型,请务必保证已获取所有 Amazon Titan 的模型的访问权限。
点击右上角的用户名,并选择设置。
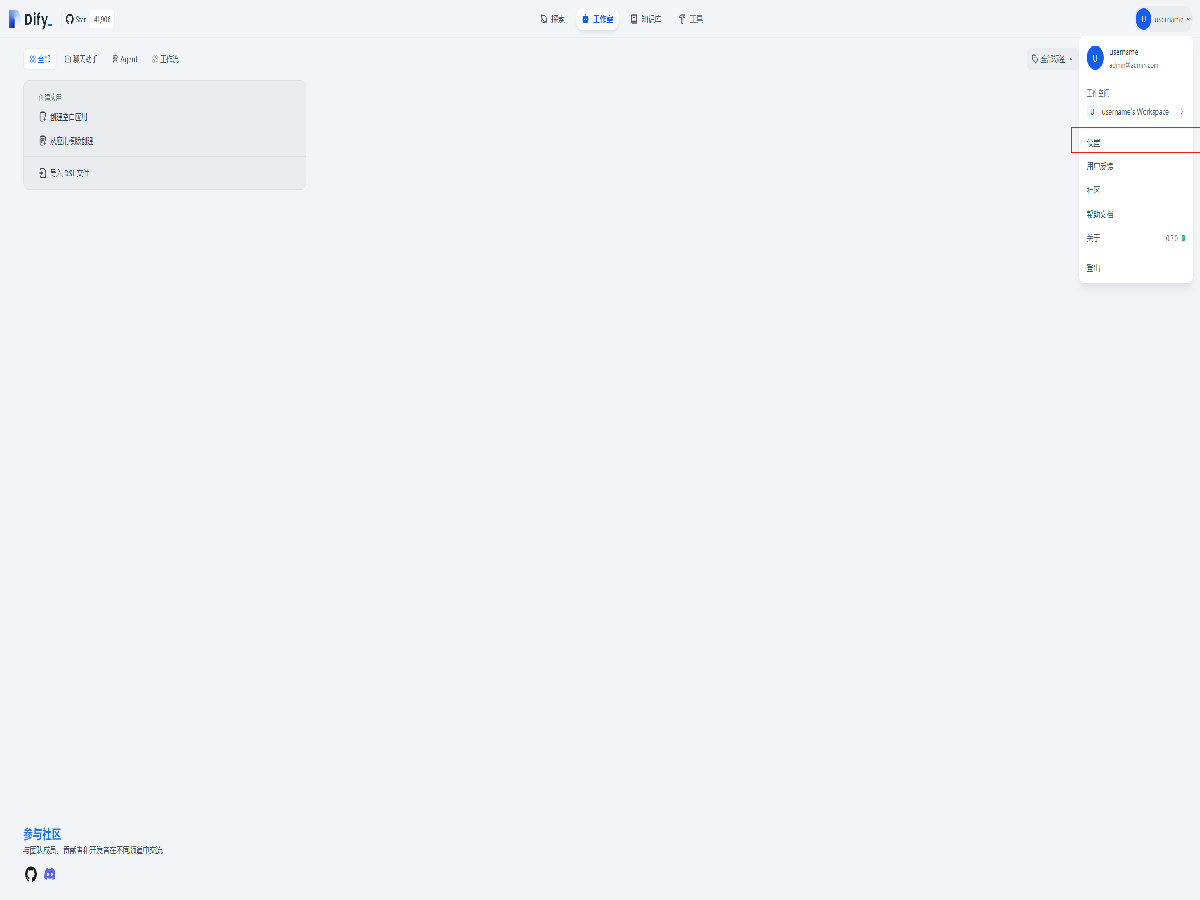
在左侧栏目中找到 模型供应商,并选择 Bedrock。
如果您使用第三方模型,请选择相应的模型并输入所需的 API及其他信息,然后可跳转至构建应用部分
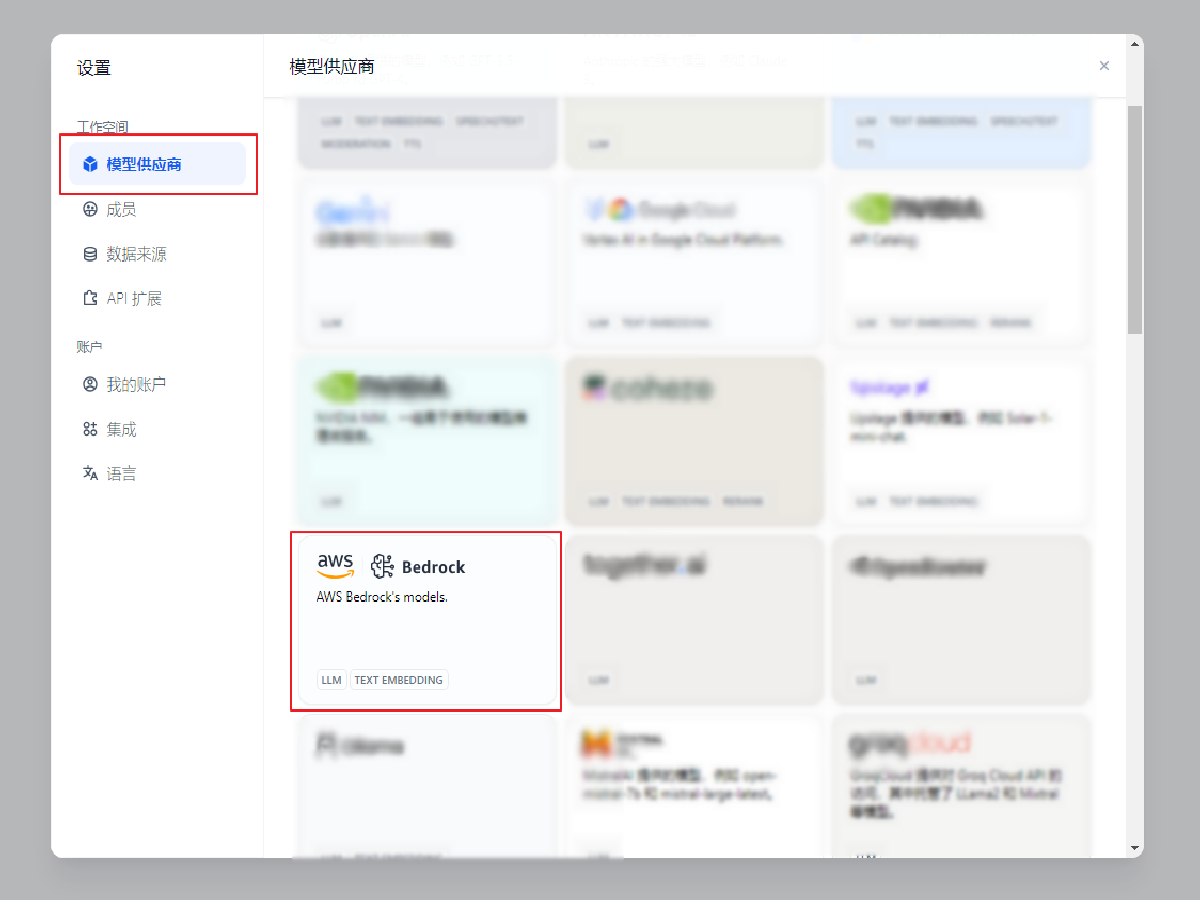
输入 Access Key / Secret Access Key,选择相应的 AWS Region,在可用模型名称中输入 amazon.titan-text-express-v1,点击保存,若返回模型选择页面则保存成功。
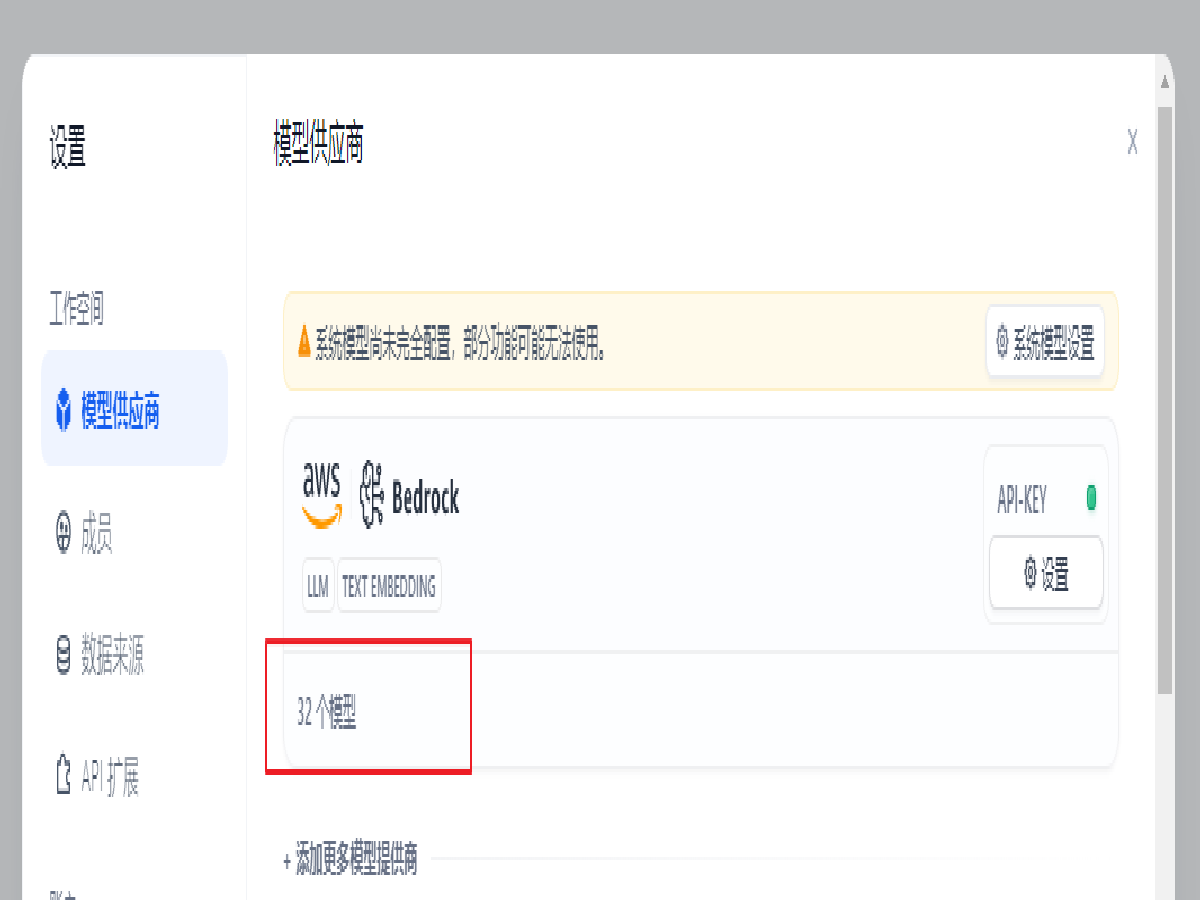
验证模型权限,点击 Bedrock 下方的 32 个模型(数量依据实际情况会有变化),即可展开全部以获取访问权限的模型列表。
点击右上角的 系统模型设置,选择默认系统推理模型为 Llama 2 Chat 70B, Embedding 模型为 amazon.titan-embed-text-v2:0
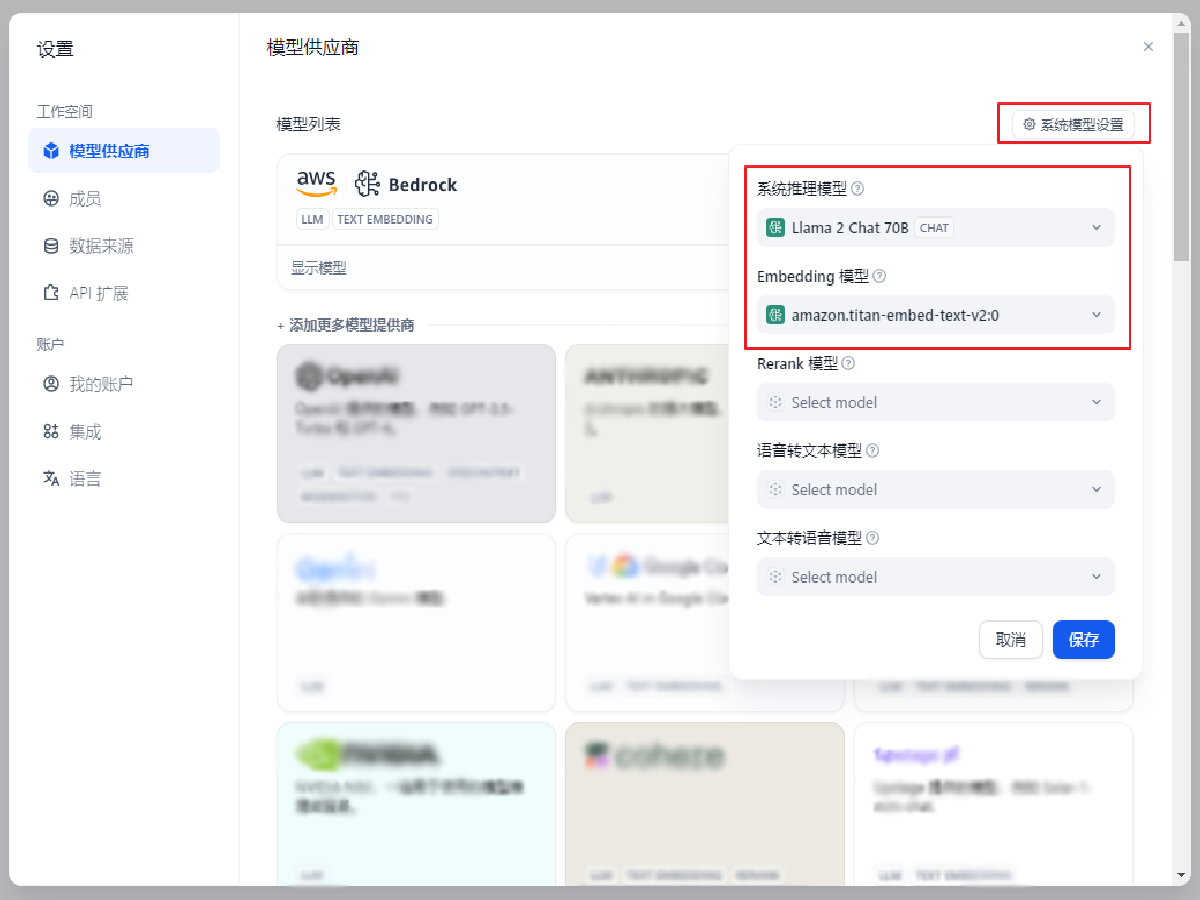
保存后,点击右上关闭按钮。至此,Dify 基础设置已完成,即可开始使用。
构建应用
全部打开点击创建空白应用创建一个新应用。
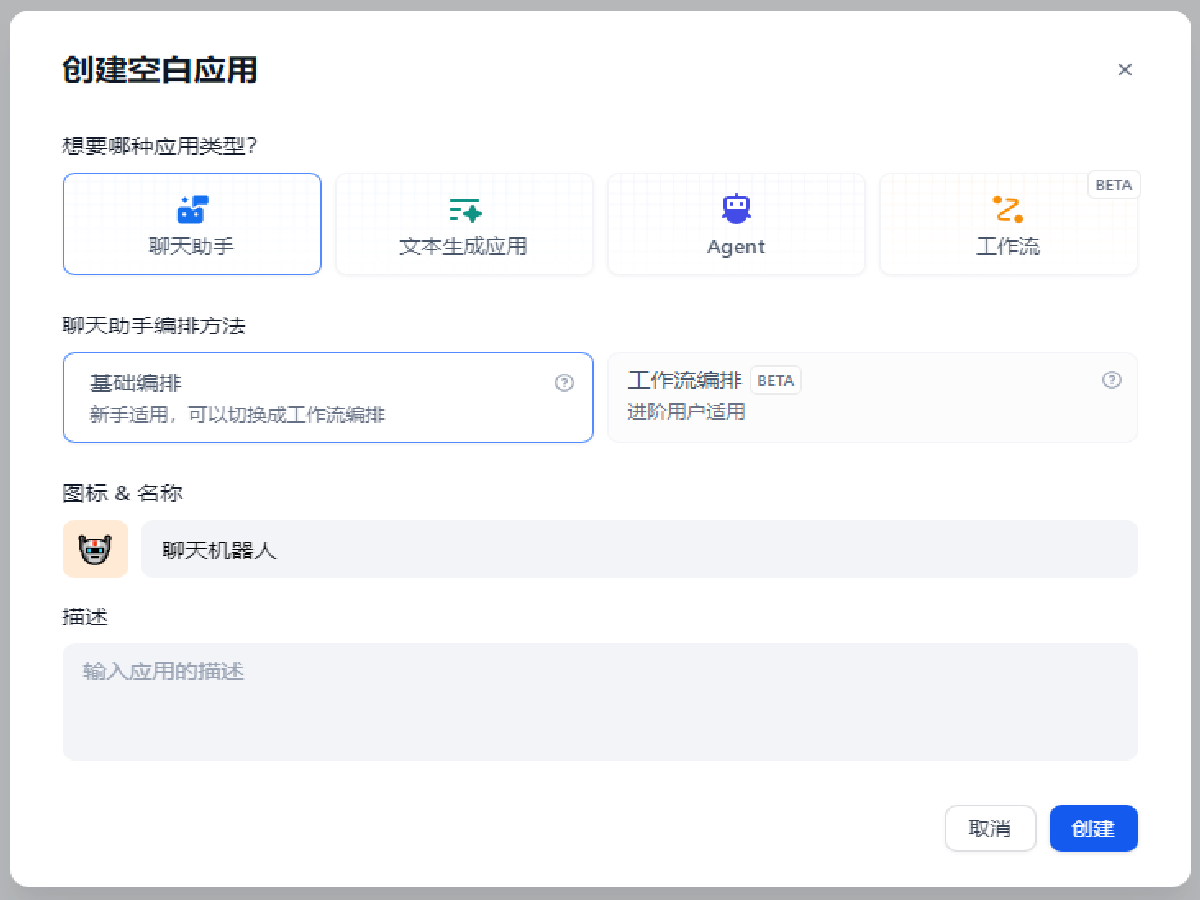
选择聊天助手,基础编排,并为此应用起名,图中应用名称为聊天机器人,点击创建
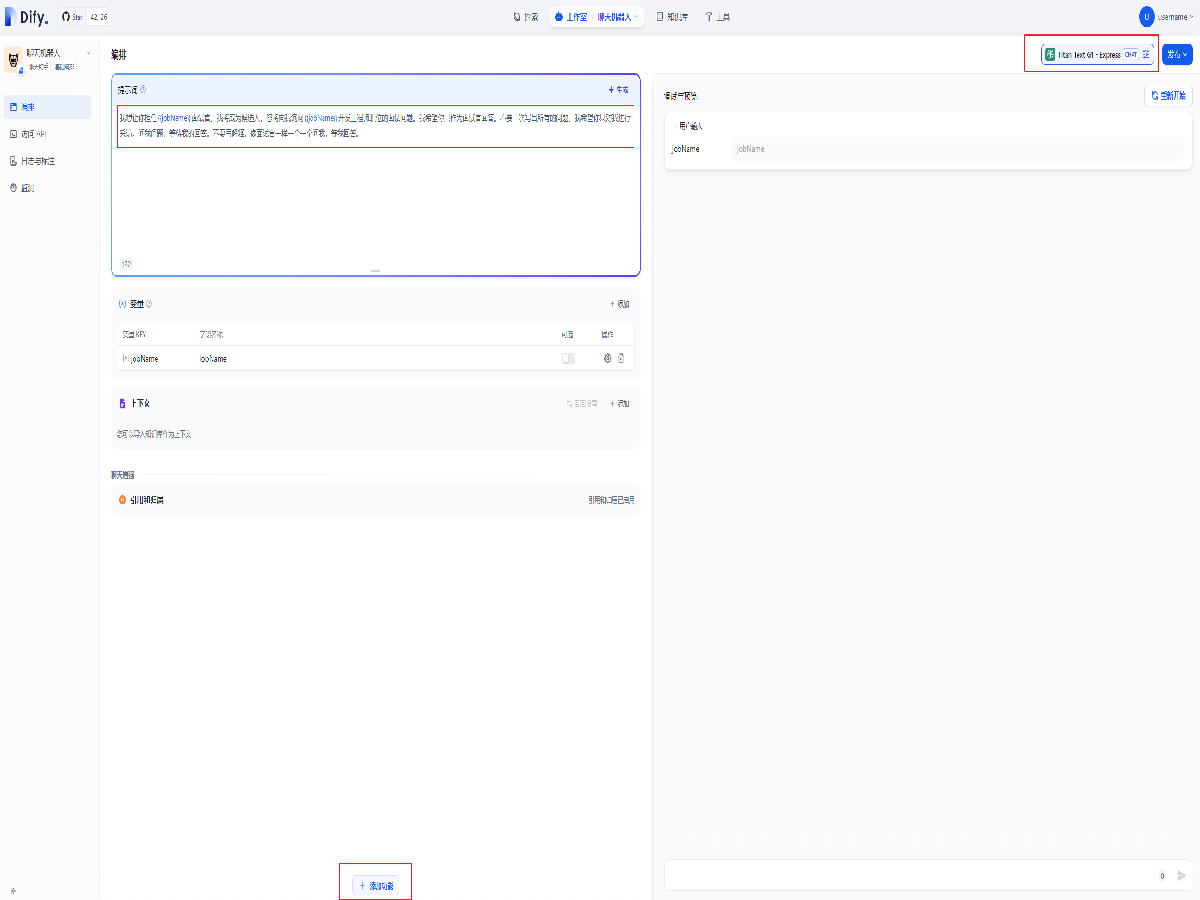
在编排页面中,添加提示词如下,并确认添加变量 jobName
我想让你担任{{jobName}}面试官。我将成为候选人,您将向我询问{{jobName}}开发工程师职位的面试问题。我希望你只作为面试官回答。不要一次写出所有的问题。我希望你只对我进行采访。问我问题,等待我的回答。不要写解释。像面试官一样一个一个问我,等我回答。
点击左下的 + 添加功能 ,打开对话开场白设置,
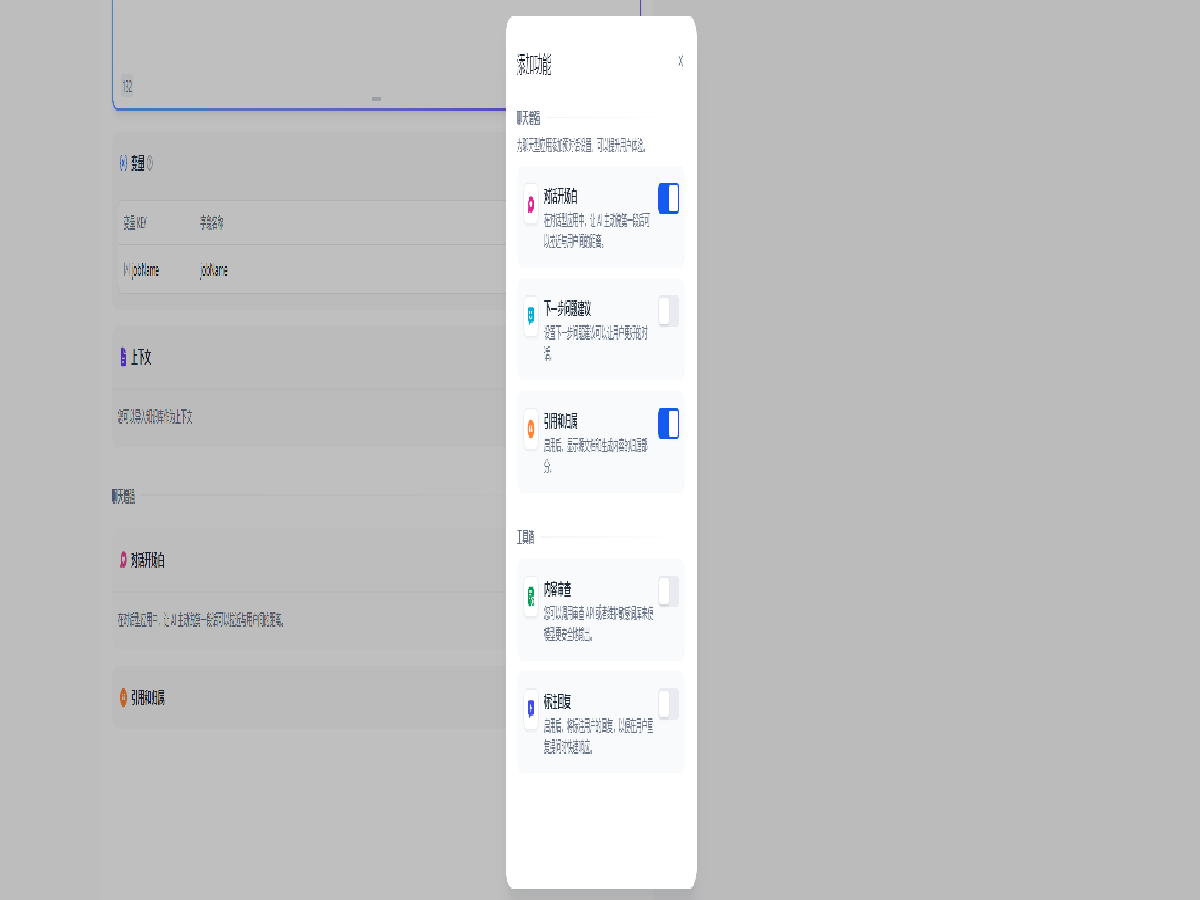
添加开场白如下,并自动添加变量 name
你好,{{name}}。我是你的面试官,Bob。你准备好了吗?
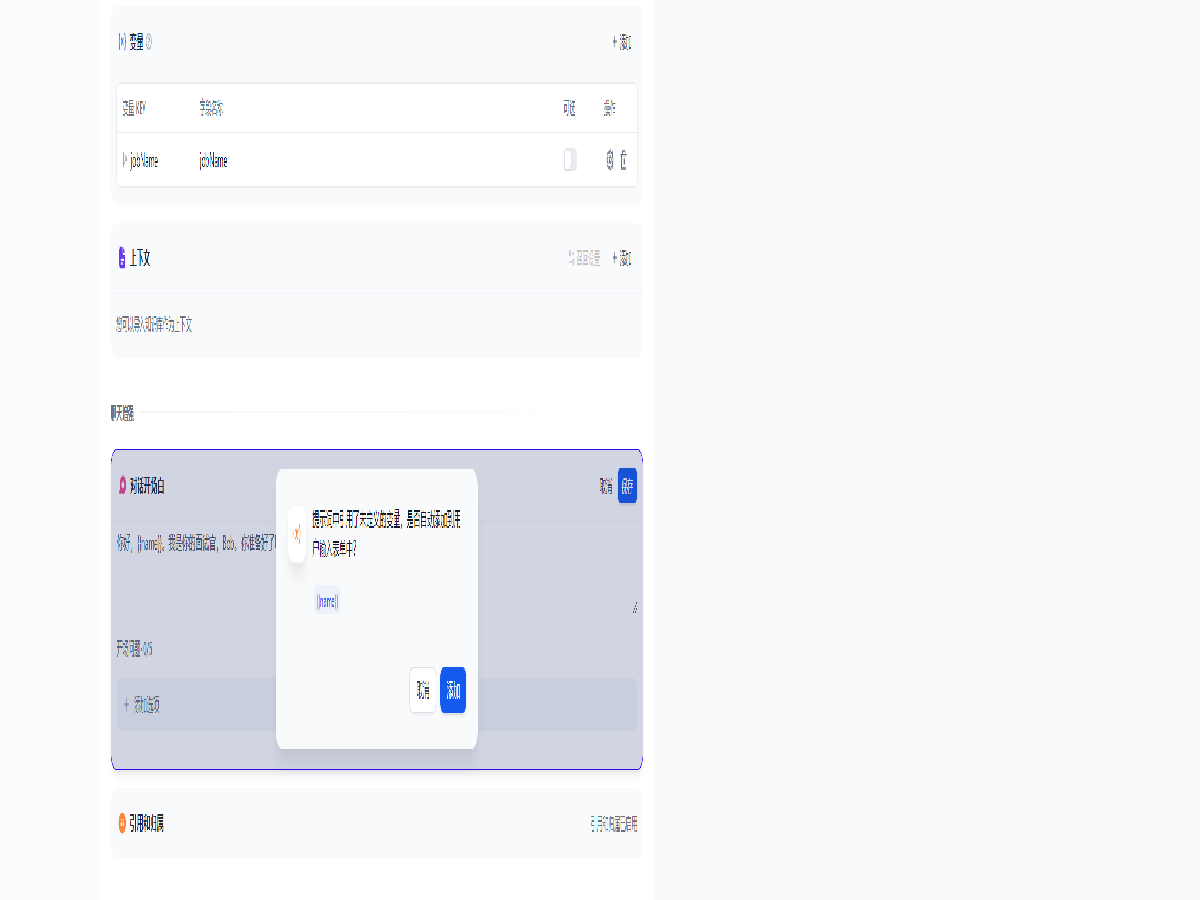
然后便可以开始聊天了,还可以点击右上的模型名称切换不同模型,开启模型对比,以及微调模型参数。
利用大语言模型的推理能力,能够自主对复杂的人类任务进行目标规划、任务拆解、工具调用、过程迭代,并在没有人类干预的情况下完成任务。
点击创建空白应用创建一个新应用。
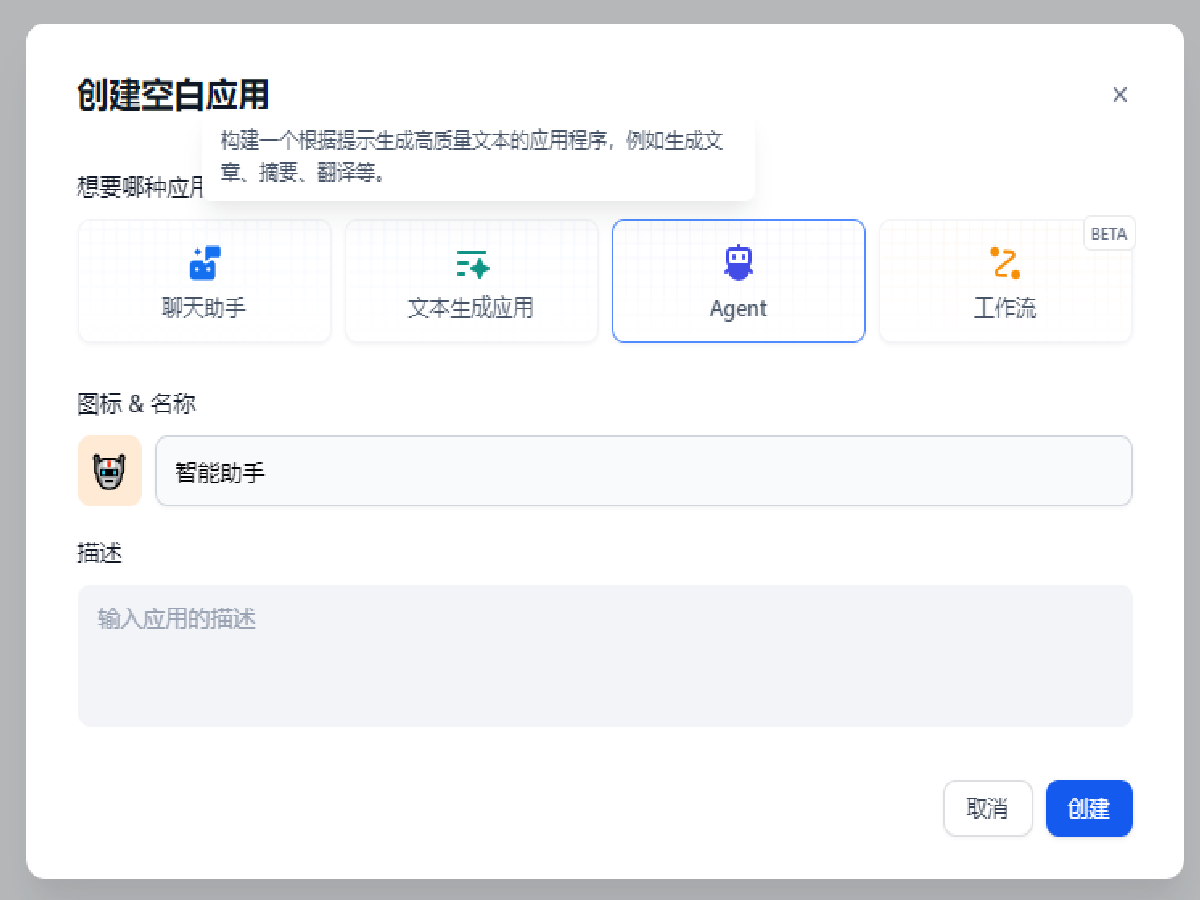
选择 Agent,并为其命名,图中应用名称为智能助手,点击创建。
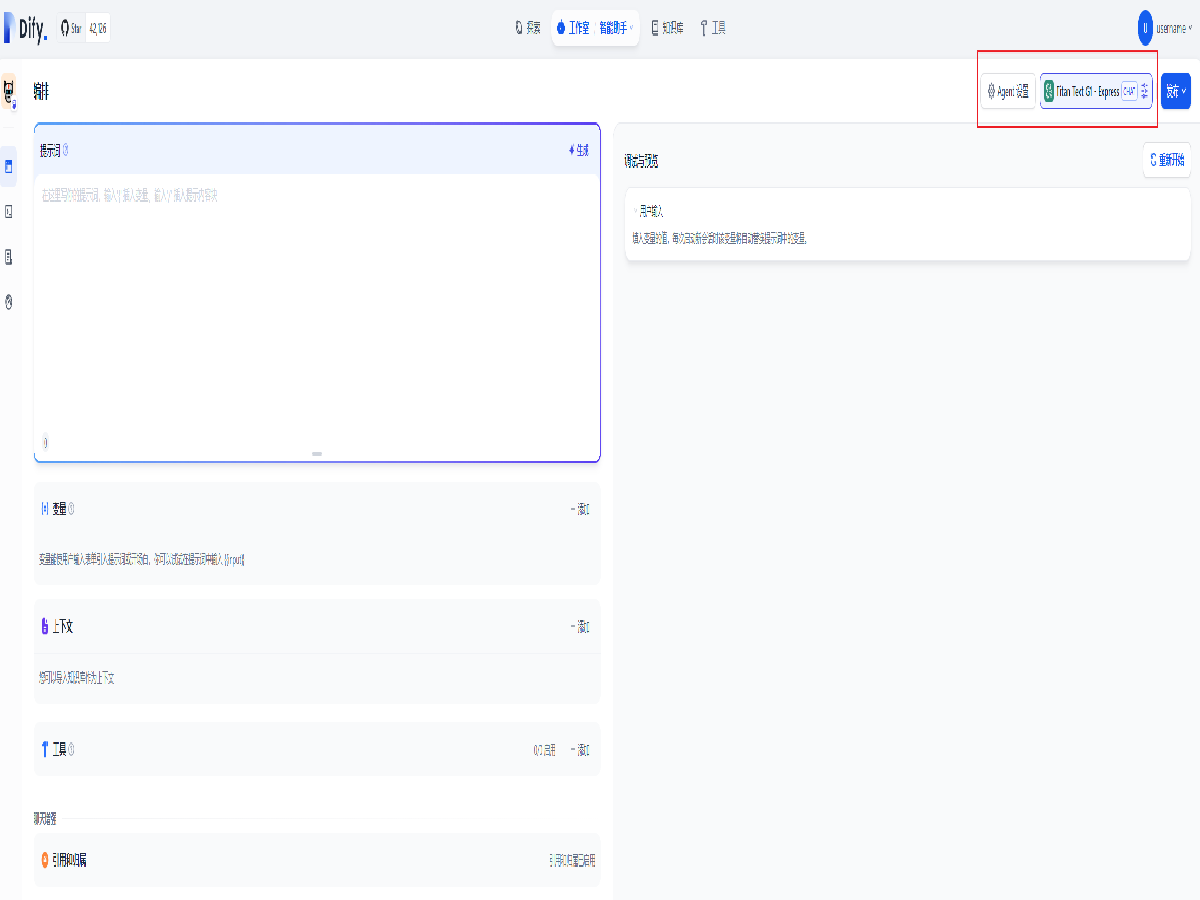
同样,可以点击右上角的模型名称来更换模型并微调参数。
点击工具栏目中的添加,选择新闻 和 股票信息。
点击创建空白应用创建一个新应用。
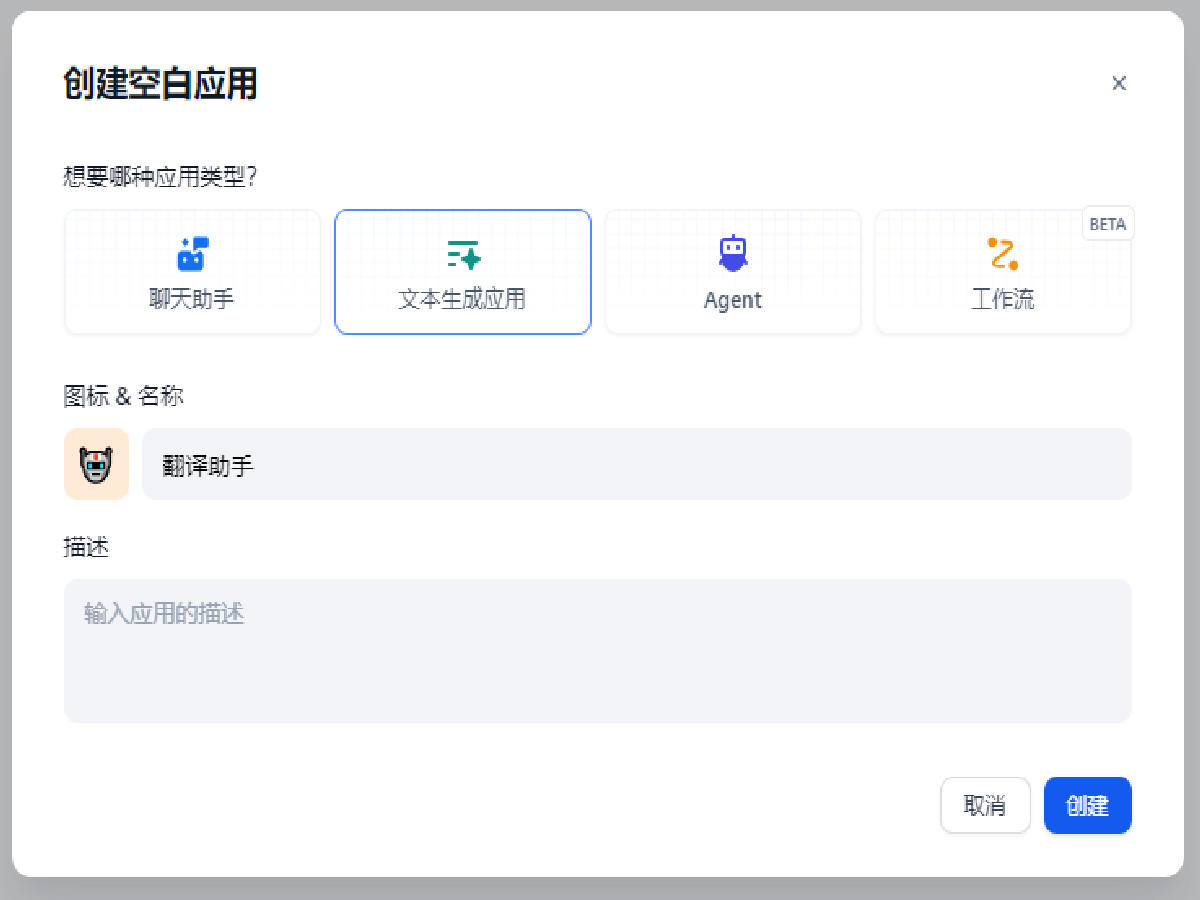
选择文本生成应用,将其命名为翻译助手。
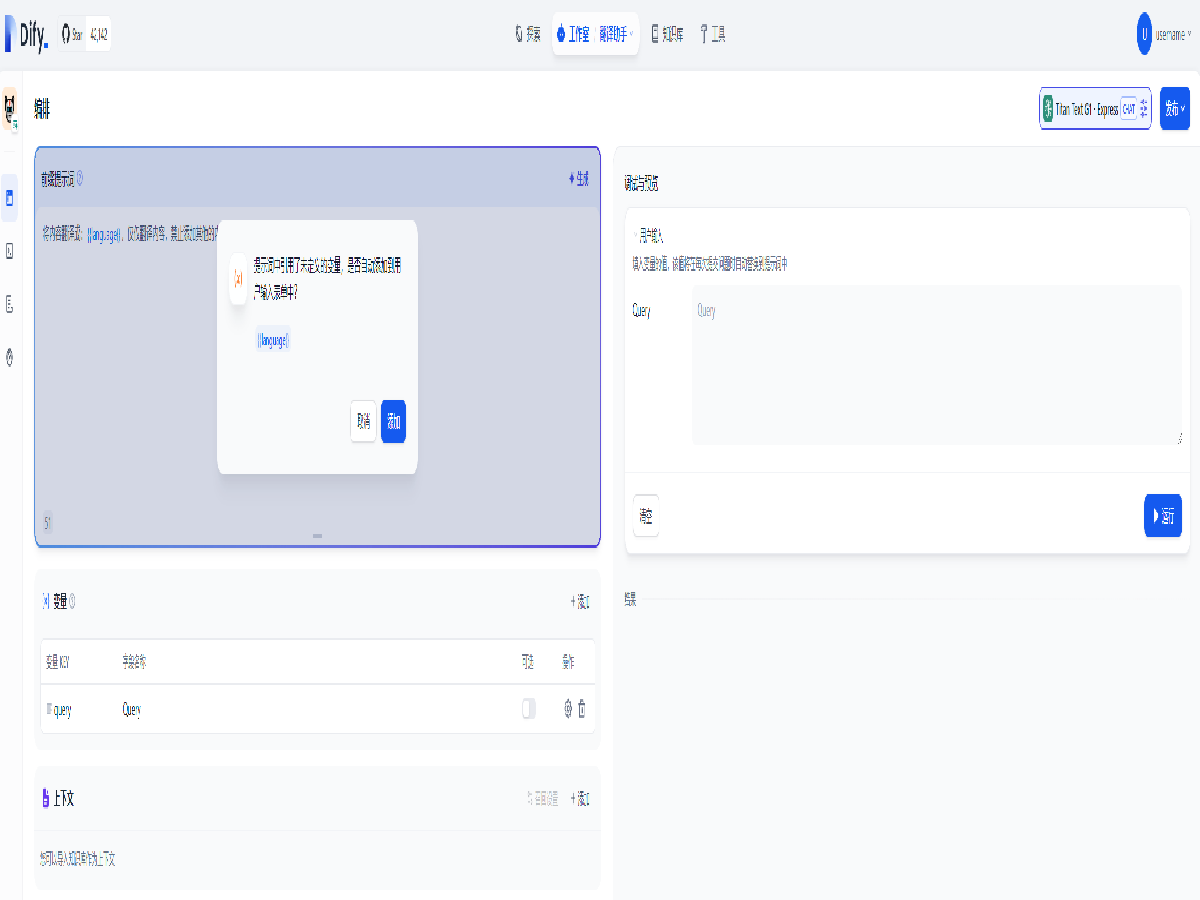
添加提示词如下,并确认自动添加变量
将内容翻译成:{{language}},仅仅翻译内容,禁止添加其他的内容。内容如下:{{query}}
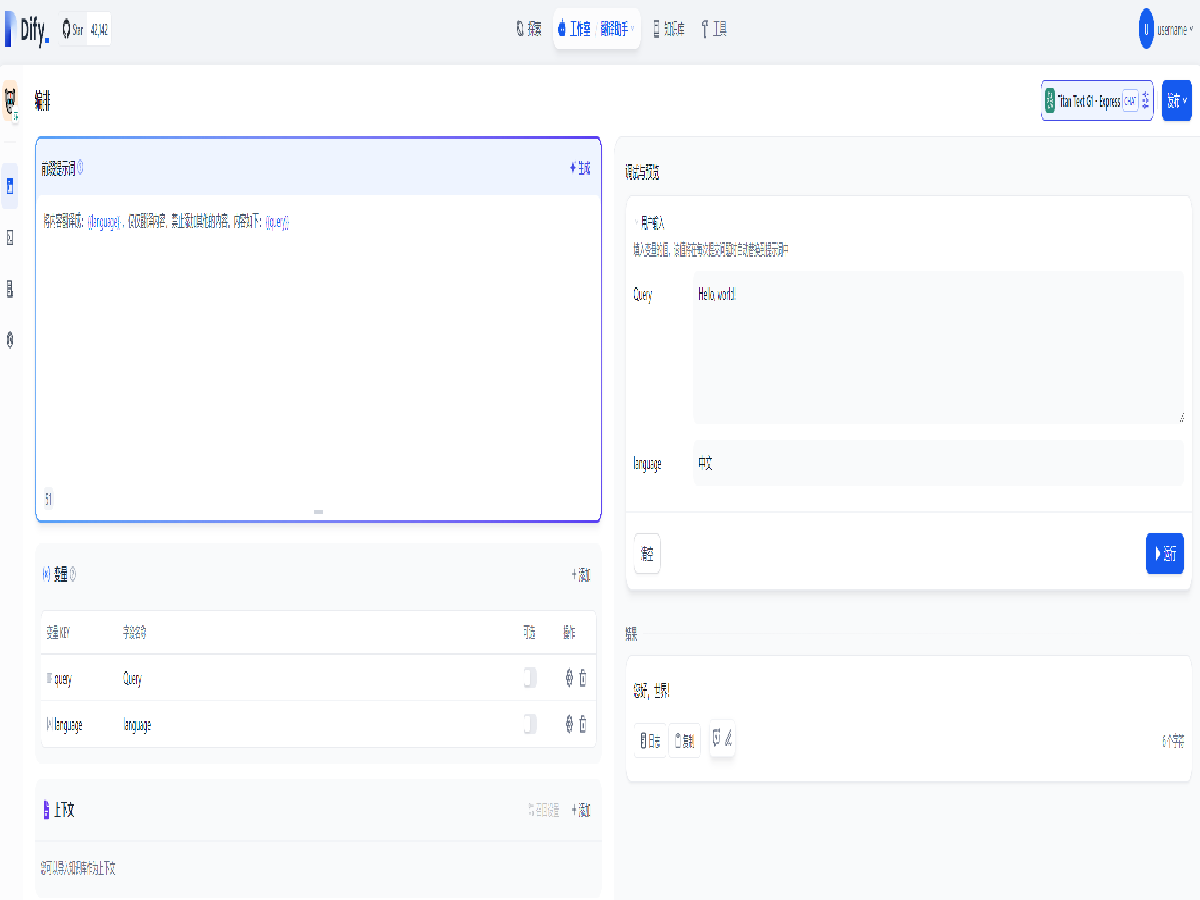
输入文字及目标语言,即可开始翻译。
点击创建空白应用创建一个新应用。将其命名为写作助手。
添加提示词如下,并确认自动添加变量
用优美的语言对目标人物或事件{{who}}进行描写,其中包含时间{{when}},地点{{where}},发生了什么{{what}}
然后在右侧输入变量的值,即可生成文本。
- 长文本内容(TXT、Markdown、DOCX、HTML、JSONL 甚至是 PDF 文件)
- 结构化数据(CSV、Excel 等)
LLM 训练使用的数据集是有一定的时效性的,并且对每次请求的上下文有长度限制。例如 ChatGPT-3.5 是基于 2021 年的语料进行训练的,且有每次约 4K Token 的限制。这意味着开发者如果想让 AI 应用基于最新的、私有的上下文对话,必须使用类似嵌入(Embedding)之类的技术。
Dify 的数据集功能可以使开发者(甚至非技术人员)以简单的方式管理数据集,并自动集成至 AI 应用中。只需准备文本内容做完向量化进行存储,目前支持的文档类型如下所示:
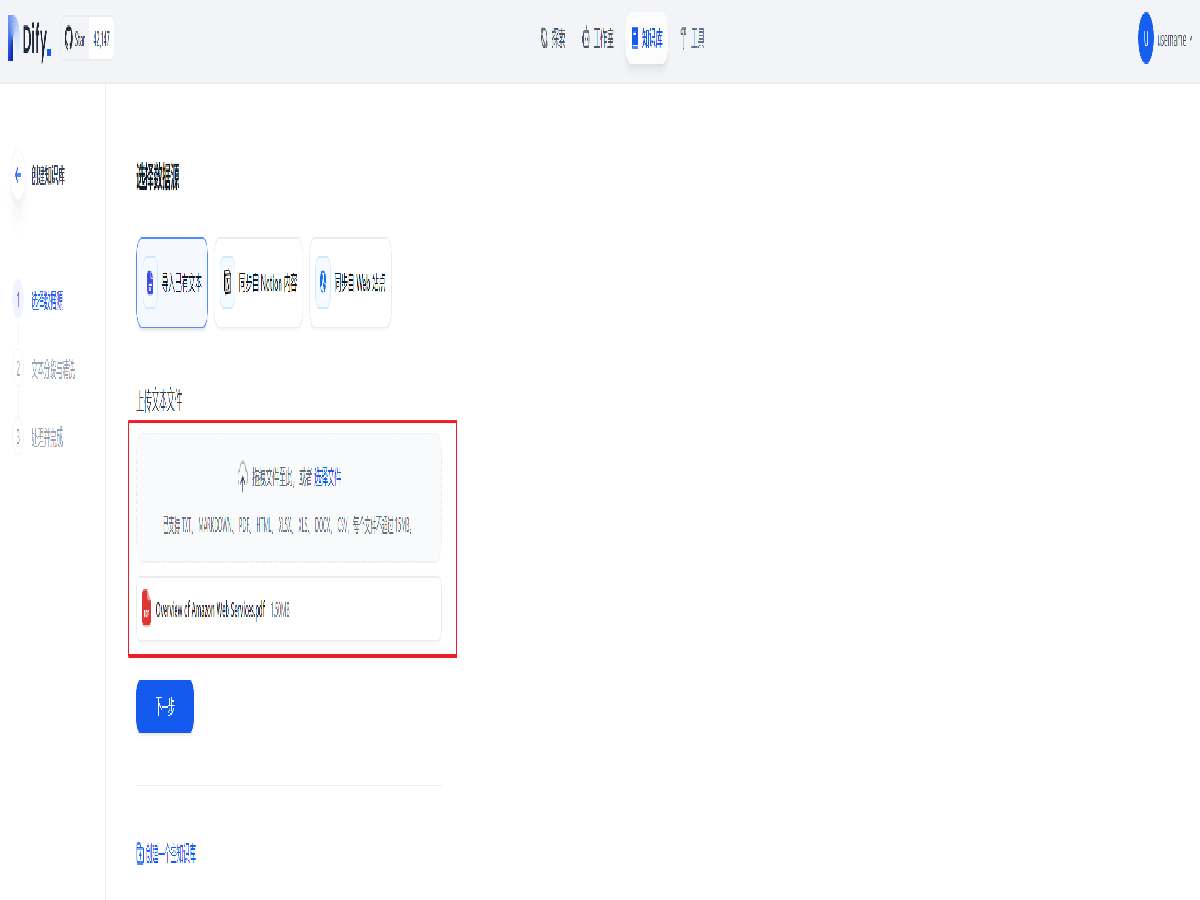
本文我们采用本地上传的方式引入知识库。
点击界面上方的 知识库 标签,并创建知识库。
选择导入已有文本,选择本地文件并上传,点击下一步。
选择向量化模型后进行向量化处理
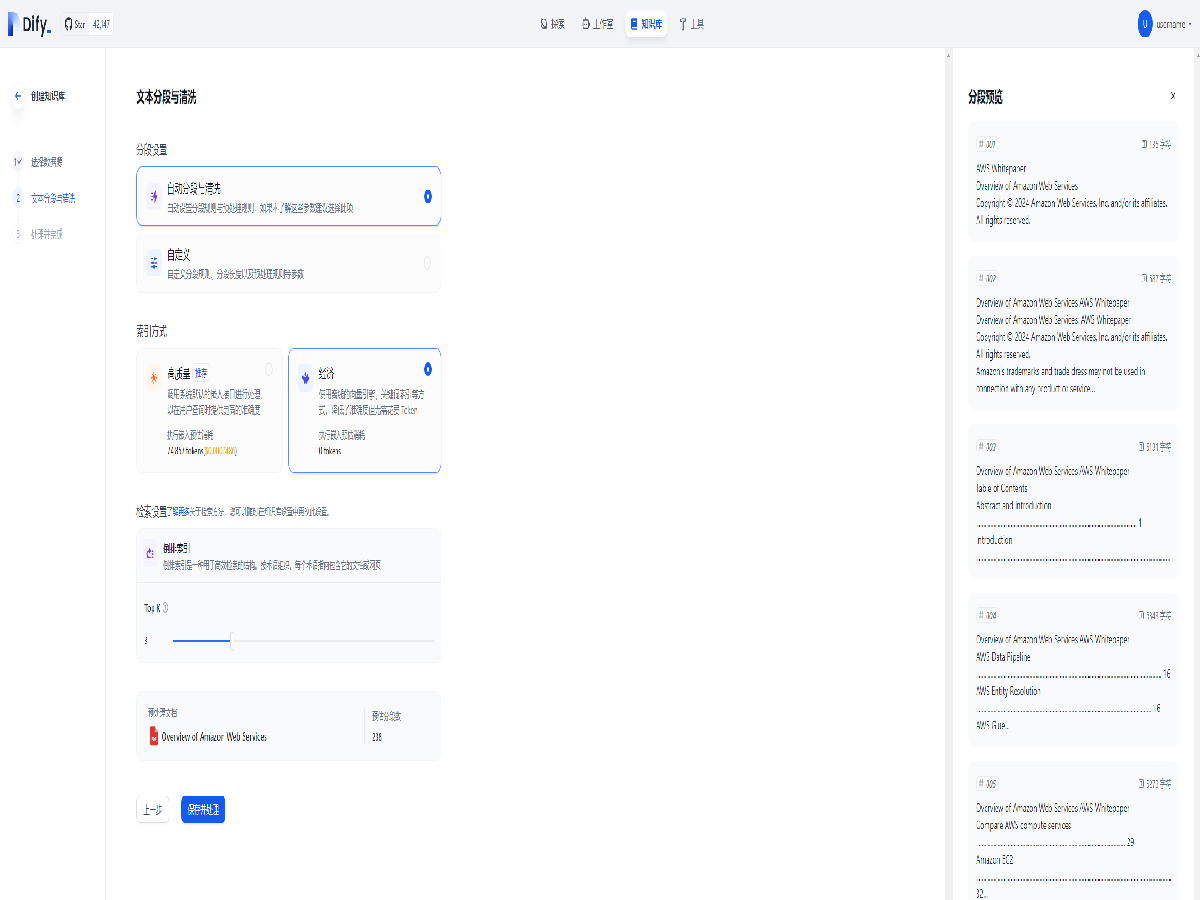
等待一会,向量化处理完成。
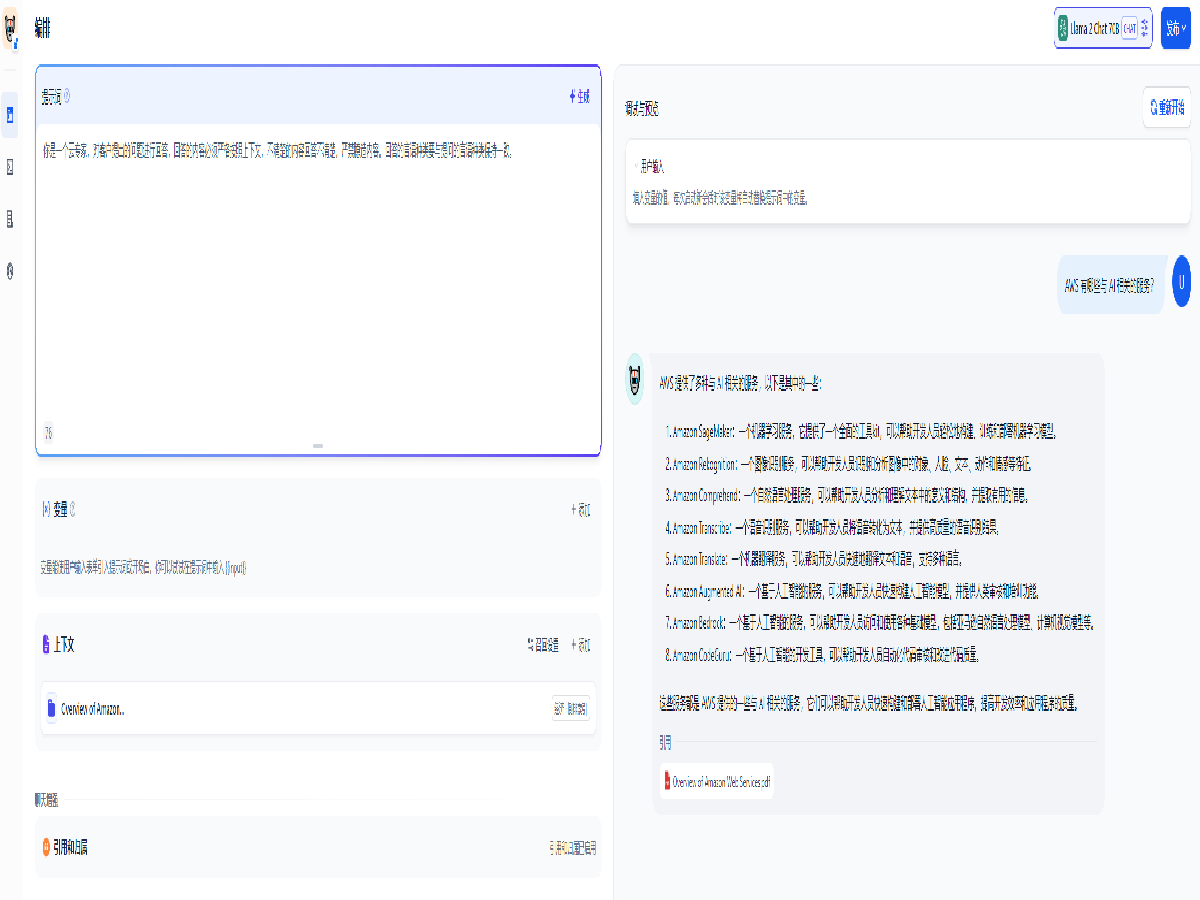
创建一个聊天应用并在上下文中添加刚刚创建的知识库。添加提示词并提出问题,可以看到模型在知识库里面查找了内容后回答了我们提出的问题。
发布与监控
全部打开点击左侧的仪表盘图标即可打开发布与监控面板。
面板上方可以看到可分享给用户的链接,包括 iframe 嵌入等方式。
面板下方则为此应用的使用报告。
清理
全部打开进入 EC2 控制台,停用或删除 EC2 实例(教程中默认名为 Dify-Bedrock)
进入 IAM 控制台,删除用户,删除策略。
总结
找到今天要查找的内容了吗?
请提供您的意见,以便我们改进网页内容的质量