AWS Trainium
Trainium — dibuat khusus untuk AI beperforma tinggi dan hemat biaya dalam skala besar
Mengapa memilih Trainium?
AWS Trainium adalah rangkaian akselerator AI, Trainium1, Trainium2, dan Trainium3, yang dibuat khusus dan dirancang untuk memberikan performa yang dapat diskalakan dan efisiensi biaya untuk pelatihan dan inferensi di berbagai beban kerja AI generatif.
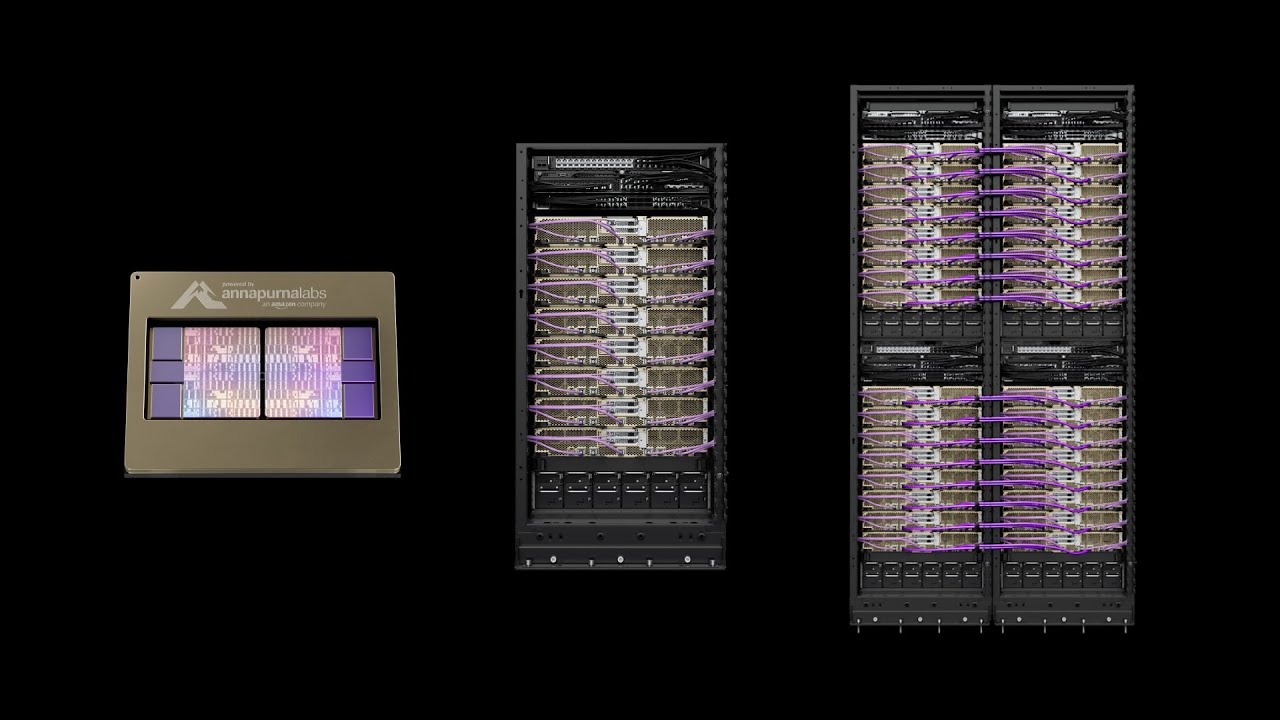
Jajaran Produk AWS Trainium
Trainium1
Chip AWS Trainium generasi pertama mendukung instans Trn1 Amazon Elastic Compute Cloud (Amazon EC2), yang memiliki biaya pelatihan hingga 50% lebih rendah daripada instans Amazon EC2 yang sebanding. Banyak pelanggan, termasuk Ricoh, Karakuri, SplashMusic, dan Arcee AI, menyadari manfaat performa dan biaya instans Trn1.
Trainium2
Chip AWS Trainium2 memberikan performa hingga 4x lipat dari Trainium generasi pertama. Instans Trn2 Amazon EC2 dan UltraServers Trn2 berbasis Trainium2 dibuat khusus untuk AI generatif dan menawarkan rasio harga-performa 30-40% lebih baik daripada instans P5e dan P5en EC2 berbasis GPU. Instans Trn2 menghadirkan hingga 16 chip Trainium2, dan UltraServers Trn2 menghadirkan hingga 64 chip Trainium2 yang terhubung dengan NeuronLink, interkoneksi antar-chip milik kami. Anda dapat menggunakan instans dan UltraServers Trn2 untuk melatih dan men-deploy model dengan syarat ketat termasuk model bahasa besar (LLM), model multi-modal, dan transformator difusi untuk membangun serangkaian aplikasi AI generatif generasi berikutnya yang beragam.
Trainium3
Chip AI 3nm pertama AWS dibuat khusus untuk memberikan ekonomi token terbaik untuk aplikasi agentik, penalaran, dan pembuatan video generasi berikutnya. Chip AWS Trainium3 memberikan performa komputasi 2x lebih tinggi hingga 2,52 petaflops (PFLOP) komputasi FP8, meningkatkan kapasitas memori 1,5x lipat dan bandwidth 1,7x lipat dari Trainium2 hingga 144 GB memori HBM3e, dan bandwidth memori 4,9 TB/s. Trn3 UltraServers, didukung oleh Trainium3, memberikan performa hingga 4,4x lebih tinggi, bandwidth memori 3,9x lebih tinggi, dan efisiensi energi 4x lebih baik dibandingkan UltraServer Trn2. Trainium3 dirancang untuk beban kerja padat dan paralel ahli dengan tipe data lanjutan (MXFP8 dan MXFP4) dan keseimbangan memory-to-compute yang ditingkatkan untuk tugas waktu nyata, multimodal, dan penalaran.
Dibuat untuk Developer
UltraServers berbasis Trainium3 baru dibuat untuk peneliti AI dan didukung oleh AWS Neuron SDK, untuk membuka performa terobosan.
Dengan integrasi PyTorch native, developer dapat melatih dan melakukan deployment tanpa mengubah satu baris kode. Untuk rekayasawan performa AI, kami telah mengaktifkan akses yang lebih dalam ke Trainium3 sehingga developer dapat menyempurnakan performa, menyesuaikan kernel, dan mendorong model Anda lebih jauh lagi. Karena inovasi berkembang pada keterbukaan, kami berkomitmen untuk terlibat dengan developer melalui alat dan sumber daya sumber terbuka.
Untuk mempelajari lebih lanjut, kunjungi Amazon EC2 Trn3 UltraServers, dan jelajahi AWS Neuron SDK.
Manfaat
Trn3 UltraServers menghadirkan inovasi terbaru dalam teknologi UltraServer yang ditingkatkan, dengan NeuronSwitch-v1 untuk kolektif all-to-all yang lebih cepat di hingga 144 chip Trainium3. Trn3 UltraServer menyediakan HBM3e hingga 20,7 TB, bandwidth memori 706 Tb/s, dan 362 MXFP8 PFLOP, memberikan performa hingga 4,4x lebih tinggi dan efisiensi energi 4x lebih baik daripada UltraServers Trn2. Trn3 memberikan performa tertinggi dengan biaya terendah untuk pelatihan dan inferensi dengan model MoE dan tipe penalaran parameter 1T+ terbaru, dan mendorong throughput yang jauh lebih tinggi untuk layanan GPT-OSS dalam skala besar dibandingkan dengan instans berbasis Trainium2.
UltraServers Trn2 tetap menjadi pilihan beperforma tinggi dan hemat biaya untuk pelatihan AI generatif dan inferensi model hingga parameter 1T. Instans Trn2 menghadirkan hingga 16 chip Trainium2, dan UltraServers Trn2 menghadirkan hingga 64 chip Trainium2 yang terhubung dengan NeuronLink, interkoneksi antar-chip eksklusif.
Instans Trn1 menghadirkan hingga 16 chip Trainium dan memberikan hingga 3 FP8 PFLOP, 512 GB HBM dengan bandwidth memori 9,8 TB/s, dan jaringan EFA hingga 1,6 Tbps.
AWS Neuron SDK membantu Anda mengeluarkan performa penuh instans Trn3, Trn2, dan Trn1 sehingga Anda dapat fokus pada pembuatan dan deployment model, serta mempercepat waktu masuk pasar. AWS Neuron terintegrasi secara native dengan PyTorch Jax dan pustaka penting, seperti Hugging Face, vLLM, PyTorch Lightning, dan banyak lagi. Ini mengoptimalkan model secara langsung untuk pelatihan dan inferensi terdistribusi, sekaligus memberikan wawasan mendalam untuk pembuatan profil dan debugging. AWS Neuron terintegrasi dengan layanan, seperti Amazon SageMaker, Amazon SageMaker Hyerpod, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), AWS ParallelCluster, dan AWS Batch, serta layanan pihak ketiga, seperti Ray (Anyscale), Domino Data Lab, dan Datadog.
Untuk memberikan performa tinggi sekaligus memenuhi tujuan akurasi, AWS Trainium mendukung berbagai tipe data
presisi campuran, seperti BF16, FP16, FP8, MXFP8, dan MXFP4. Untuk mendukung laju inovasi yang cepat dalam AI generatif,
Trainium2 dan Trainium3 memberikan pengoptimalan perangkat keras untuk 4x ketersebaran (16:4), penskalaan mikro, pembulatan
stokastik, dan mesin kolektif khusus.
Neuron memungkinkan developer untuk mengoptimalkan beban kerja menggunakan Antarmuka Kernel Neuron (NKI) untuk pengembangan kernel. NKI mengekspos Trainium ISA lengkap, memungkinkan kontrol penuh atas pemrograman tingkat instruksi, alokasi memori, dan penjadwalan eksekusi. Selagi membangun kernel Anda, developer dapat menggunakan Pustaka Kernel Neuron, yang bersumber terbuka, dan siap untuk menerapkan kernel yang dioptimalkan. Terakhir, Neuron Explore menyediakan visibilitas tumpukan penuh, menghubungkan kode developer ke mesin di perangkat keras.
Pelanggan
Pelanggan, seperti Anthropic, Decart, poolside, Databricks, Ricoh, Karakuri, SplashMusic, dan lainnya, menyadari manfaat performa dan biaya dari instans dan UltraServers Trn1, Trn2, dan Trn3.
Pengguna awal Trn3 mencapai tingkat efisiensi dan skalabilitas baru untuk model AI generatif skala besar generasi berikutnya.

Taklukkan performa, biaya, dan skala AI

AWS Trainium2 untuk performa AI terobosan

Kisah pelanggan chip AI AWS

