Blog AWS Indonesia
Optimalisasi Biaya untuk Kubernetes di AWS
Tulisan ini disumbangkan oleh AWS Container Hero, Casey Lee, Direktur Teknik di Liatrio
Kombinasi Amazon Elastic Kubernetes Service (EKS) sebagai control plane Kubernetes yang terkelola dan Amazon EC2 sebagai Kubernetes nodes yang elastis merupakan lingkungan yang ideal untuk menjalankan beban kerja kontainer (containerized workload). Hal ini bukan hanya memungkinkan Anda sebagai pembangun (builders) dengan cepat membuat kluster Kubernetes, tapi juga memungkinkan pembangun untuk menskalakan klusternya sesuai penggunaan demi memenuhi kebutuhan pengguna mereka. Akan tetapi, kita harus memastikan agar pilar optimisasi biaya dari AWS Well-Architected Framework dapat terealisasikan.
Ada banyak komponen yang terlibat pada jumlah biaya saat menjalankan kluster Kubernetes. Komponen biaya dari EKS control plane adalah yang termudah untuk dipahami, dengan biaya tetap $0,20 per jam. Selanjutnya, kita memiliki komponen instans EC2 yang berfungsi sebagai node di kluster Kubernetes. Ada beberapa aspek biaya dari EC2 instance diantaranya blok penyimpanan (EBS) dan transfer data yang akan kita abaikan pada penjelasan artikel ini karena biaya ini sangat tergantung pada karakteristik beban kerja. Alih-alih, kita akan membahas lebih dalam tentang aspek biaya EC2 yang umumnya paling besar, yaitu waktu hidup instans (Instance Hours) dan harga per instans (Instance Price).
Biaya EC2 = Waktu Penggunaan Instans * Harga per Instans
Dalam kluster Kubernetes, instance hours berbanding lurus dengan jumlah pod di kluster dan sumber daya yang dialokasikan untuk pod tersebut.
Waktu Hidup Instans = Waktu Hidup Pod * Penggunaan Sumber Daya oleh Pod
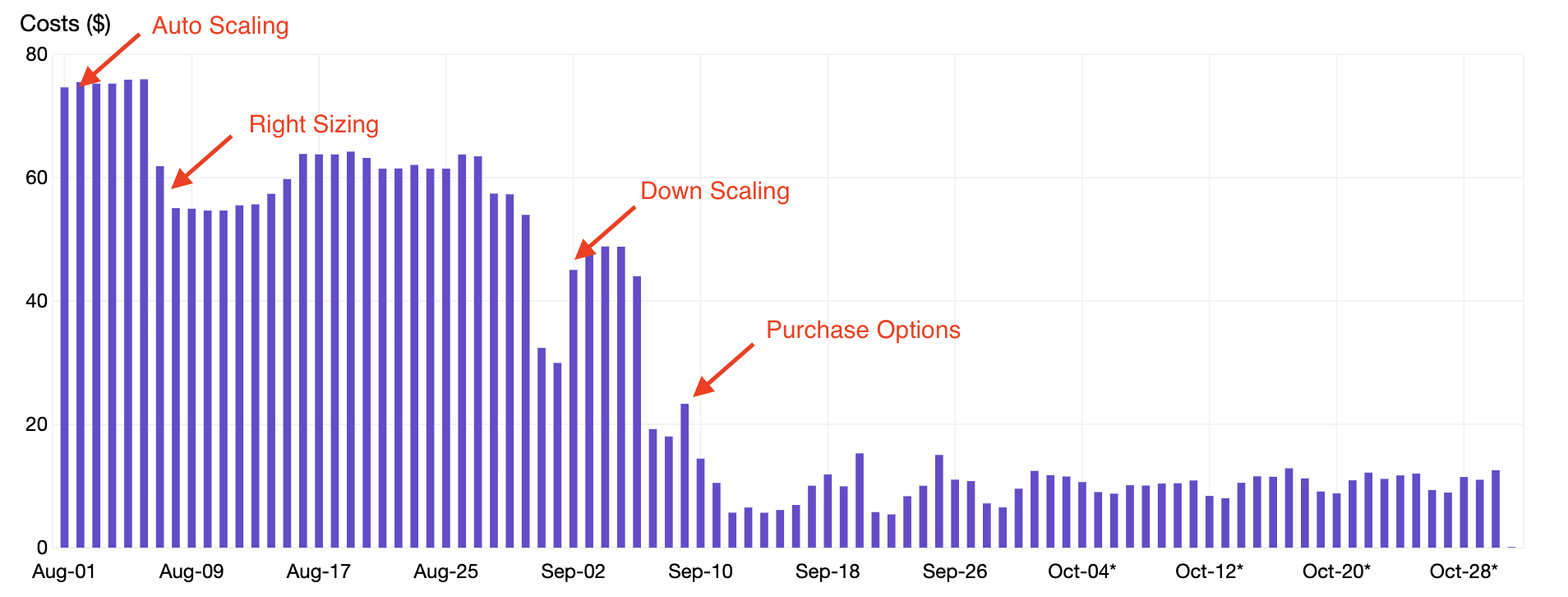
Dalam tulisan ini, kita akan meninjau empat teknik yang telah coba diterapkan pada sebuah contoh kluster agar mencapai penghematan lebih dari 80% pada penggunaan EC2:
- Penskalaan Otomatis (Auto Scaling) – Mengoptimalkan waktu hidup instans (instance hours) dengan menyelaraskan jumlah node dalam klaster dengan besarnya permintaan.
- Penentuan Ukuran yang Benar (Right Sizing) – Mengoptimalkan sumber daya pod dengan mengalokasikan sumber daya CPU dan memori yang sesuai untuk pod.
- Penurunan Penskalaan (Down Scaling) – Mengoptimalkan waktu hidup pod (pod hours) dengan mematikan (terminating) pod yang tidak perlu saat malam hari dan akhir pekan.
- Opsi Pembelian – Mengoptimalkan harga instans dengan mengganti On-Demand Instance menjadi Spot Instance.
Penskalaan Otomatis (Auto Scaling)
Pilar optimasi biaya dari AWS Well-Architected Framework mencakup bagian tentang Kesesuaian Pasokan dan Permintaan
(Matching Supply and Demand), yang merekomendasikan hal-hal berikut:
“… hal ini (kesesuaian pasokan dan permintaan) dicapai menggunakan Auto Scaling, yang membantu Anda untuk meningkatkan EC2 instance Anda dan kapasitas Spot Fleet yang secara otomatis dapat naik atau turun sesuai dengan kondisi yang Anda tetapkan“
Jadi prasyarat untuk optimasi biaya pada kluster Kubernetes adalah dengan memastikan Anda menjalankan Cluster Autoscaler. Alat ini melakukan dua fungsi kritis dalam klaster. Pertama, ia akan memonitor klaster saat ada pod yang tidak dapat berjalan yang disebabkan oleh sumber daya yang tidak mencukupi. Saat hal tersebut terjadi, Cluster Autoscaler akan memperbarui Amazon EC2 AutoScaling Group untuk meningkatkan jumlah node yang diinginkan, sehingga menghasilkan node tambahan di klaster tersebut. Selain itu, Cluster Autoscaler juga akan mendeteksi jika suatu node kurang dimanfaatkan dan menjadwal ulang (dengan kata lain memindahkan) pod ke node lain. Cluster Autoscaler kemudian akan mengurangi desired count pada Auto Scaling Group untuk mengurangi (scale in) jumlah node.
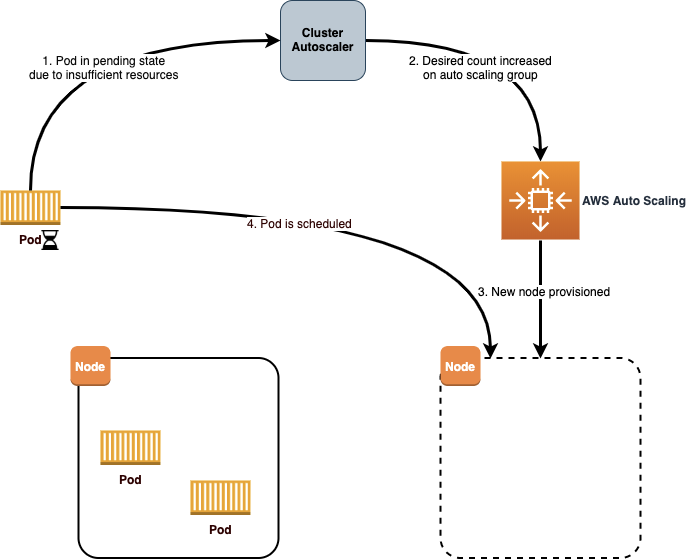
Panduan Pengguna Amazon EKS memiliki bagian yang cukup bagus yang menjelaskan mengenai konfigurasi Cluster Autoscaler. Ada beberapa hal yang perlu diperhatikan saat mengonfigurasi Cluster Autoscaler:
IAM Roles untuk Service Account – Cluster Autoscaler akan memerlukan akses untuk memperbarui kapasitas yang diinginkan (desired capacity) dalam Auto Scaling Group. Pendekatan yang disarankan adalah membuat sebuah IAM role baru dengan kebijakan yang diperlukan dan sebuah trust policy yang membatasi akses ke service account yang digunakan oleh Cluster Autoscaler. Kemudian, nama role harus diberikan sebagai anotasi pada service account:
Auto Scaling Group per AZ – Ketika Cluster Autoscaler bertambah (scale out), pada dasarnya itu yang terjadi adalah perubahan jumlah yang diinginkan (desired count) pada Auto Scaling Group, sedangkan tanggung jawab untuk meluncurkan instans EC2 baru dilimpahkan ke layanan AWS Auto Scaling. Jika Auto Scaling group dikonfigurasikan untuk menggunakan beberapa Availability Zone (AZ), maka instans baru akan dijalankan di salah satu AZ tersebut.
Untuk penggunaan yang menggunakan persistent volumes, Anda perlu membuat Auto Scaling Group terpisah untuk setiap Availability Zone yang akan Anda gunakan. Dengan cara ini, ketika Cluster Autoscaler mendeteksi kebutuhan untuk scale out dalam menanggapi pod yang diberikan, maka ia dapat menargetkan Availability Zone yang benar untuk scale out berdasarkan pada persistent volume claims yang sudah ada di Availability Zone yang diberikan.
Saat menggunakan beberapa Auto Scaling Group, pastikan untuk menggunakan argumen berikut dalam spesifikasi pod untuk Cluster Autoscaler:
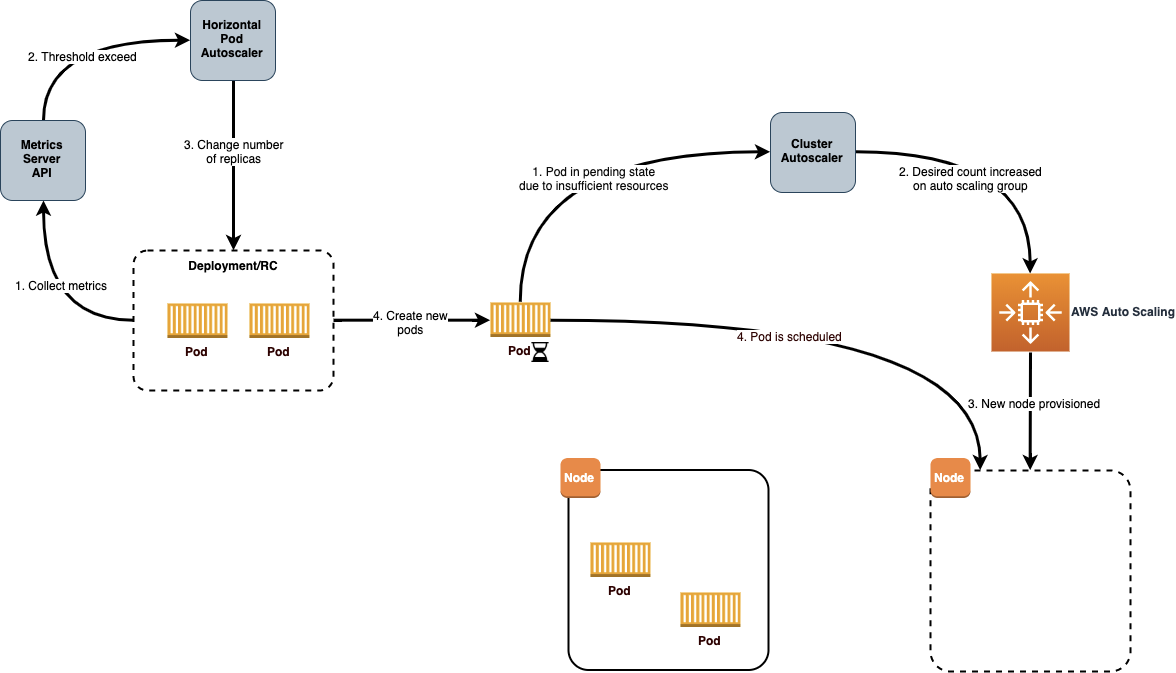
--balance-similar-node-groups = trueSaat Cluster Autoscaler sudah berjalan pada kluster Anda, Anda dapat memiliki keyakinan bahwa waktu hidup instans (instance hours) akan sangat selaras dengan permintaan dari pod di dalam klaster. Selanjutnya Anda dapat menggunakan Horizontal Pod Autoscaler (HPA) untuk menskalakan ke luar atau ke dalam (scale out or scale in) dari jumlah pod untuk suatu penyebaran berdasarkan metrik khusus agar pod dapat mengoptimalkan waktu hidup pod (pod hours) sehingga lebih lanjut tentu akan mengoptimalkan juga waktu hidup instans.

HPA controller sudah ada di Kubernetes, jadi semua yang diperlukan untuk mengonfigurasi HPA adalah dengan memastikan Kubernetes metrics server digunakan di kluster Anda dan kemudian menentukan HPA resource untuk deployment Anda. Sebagai contoh, HPA resource berikut ini dikonfigurasikan untuk memantau pemanfaatan CPU untuk penyebaran bernama nginx-ingress-controller. HPA kemudian akan menskalakan keluar atau dalam dari jumlah pod antara 1 dan 5 supaya target pemanfaatan CPU rata-rata dari semua pod adalah 80%:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: nginx-ingress-controller
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-ingress-controller
minReplicas: 1
maxReplicas: 5
targetCPUUtilizationPercentage: 80Kombinasi dari Cluster Autoscaler dan Horizontal Pod Autoscaler adalah cara yang efektif untuk menjaga total waktu hidup instans (instance hours) sedekat mungkin dengan besarnya pemanfaatan aktual dari beban kerja yang berjalan di klaster.
Penentuan ukuran yang benar (Right sizing)
Kembali ke pilar optimisasi biaya dari AWS Well-Architected Framework, kita menemukan bagian tentang Cost-Effective Resources, yang menjelaskan tentang Right Sizing sebagai berikut:
“… gunakanlah sumber daya yang memiliki biaya terendah yang masih memenuhi spesifikasi teknis dari beban kerja tertentu“
Pada Kubernetes, penentuan ukuran yang benar dilakukan dengan mengatur sumber daya komputasi, CPU, dan memori yang dialokasikan untuk container di suatu pod. Setiap kontainer di pod memiliki nilai permintaan (requests) dan batasan (limits) jumlah CPU dan memori yang akan digunakan.
Perlu kehati-hatian untuk mencoba dan menentukan requests yang sangat selaras dengan pemanfaatan sumber daya yang sebenarnya. Jika nilainya terlalu rendah, maka kontainer mungkin mengalami pelambatan (throttling) mendapatkan sumber daya dan berdampak pada kinerja. Namun, jika nilainya terlalu tinggi, maka terjadi pemborosan, karena sumber daya yang tidak digunakan itu tetap dipertahankan keberadaannya walaupun hanya untuk satu kontainer. Ketika pemanfaatan aktual lebih rendah dari nilai yang diminta, perbedaannya disebut slack cost. Alat seperti kube-resource-report berguna untuk memvisualisasikan slack cost dan menentukan nilai requests yang benar untuk kontainer dalam pod.
Petunjuk instalasi menunjukkan cara menginstal melalui helm chart yang sudah disediakan:
$ helm upgrade --install kube-resource-report chart/kube-resource-report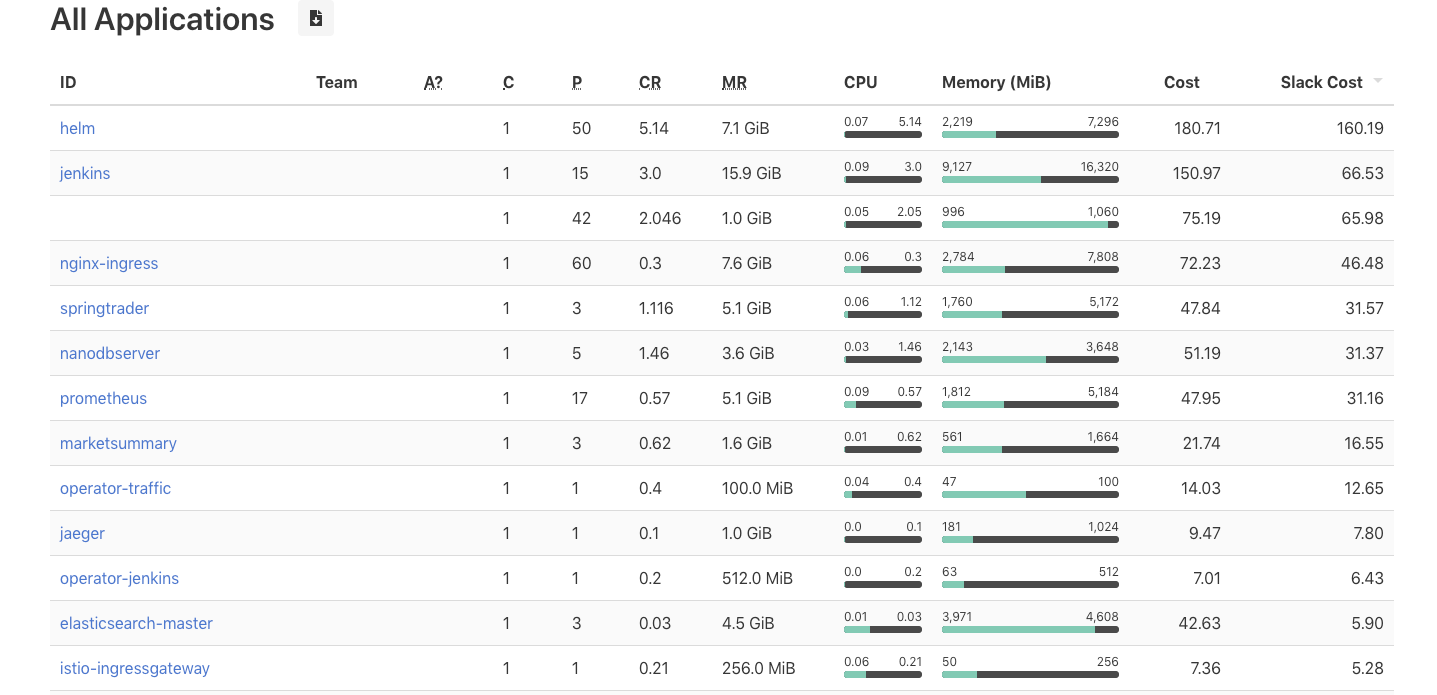
Seperti yang terlihat pada gambar tangkapan layar di atas, aplikasi seperti Jenkins dapat berukuran tepat agar menurunkan requests CPU dan memori sehingga berpotensi menghemat slack cost hingga $66,53 per bulan. Dengan menjalani proses penentuan ukuran Pod Resources yang tepat untuk semua aplikasi di klaster Kubernetes, kita dapat memperoleh penghematan 20% seperti yang ditunjukkan pada bagan di bawah ini.
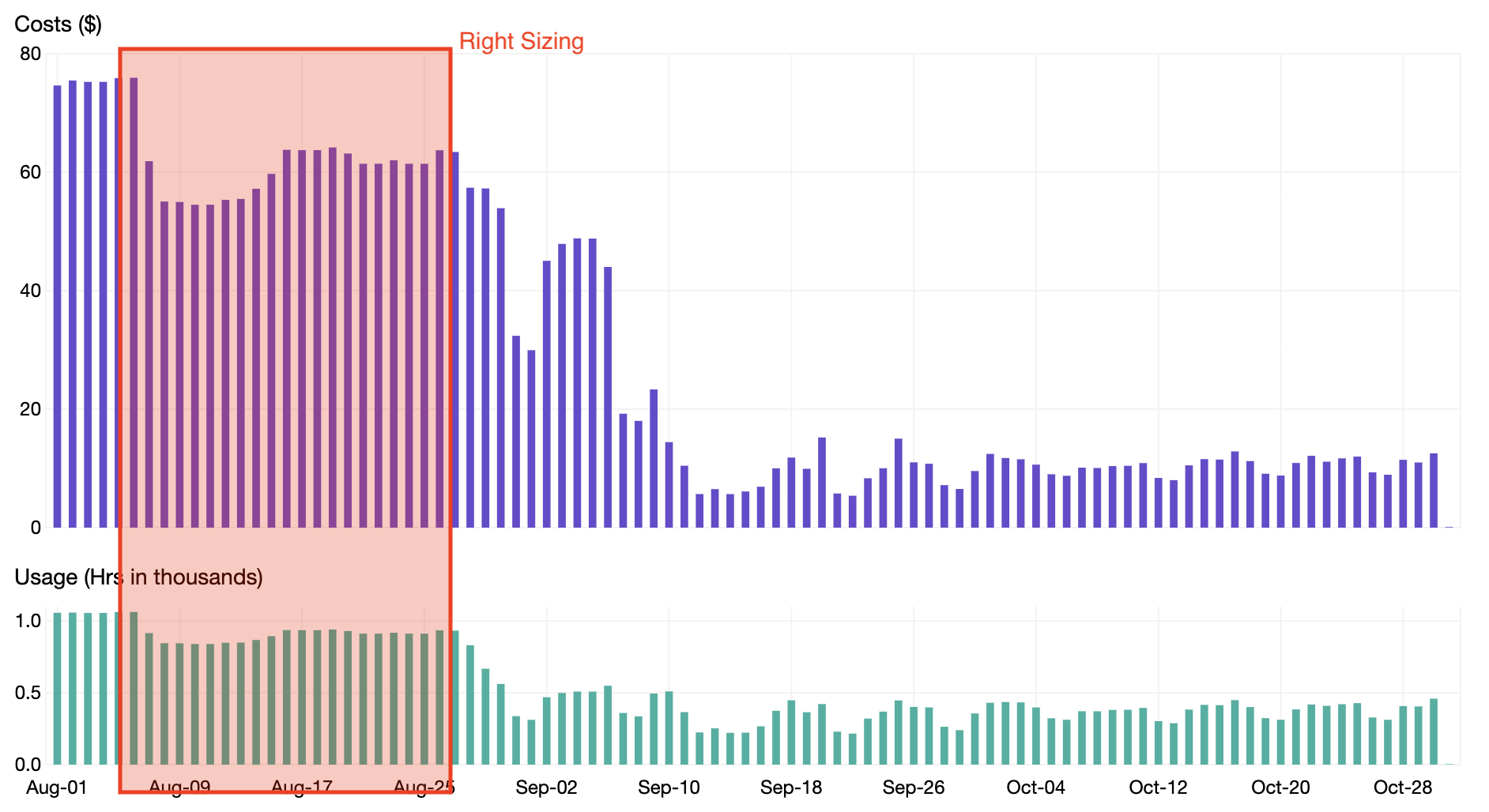
Penurunan penskalaan (Down scaling)
Selain penskalaan otomatis berdasarkan permintaan, bagian Matching Supply and Demand pada pilar optimasi biaya di AWS Well-Architected Framework merekomendasikan hal berikut:
“Sistem dapat dijadwalkan untuk diskalakan keluar atau kedalam (scale out and in) pada waktu yang kita ditentukan, misalnua pada awal jam kerja, sehingga memastikan bahwa sumber daya tersedia saat pengguna datang.“
Untuk contoh klaster yang kita gunakan, ada banyak penerapan (deployment) yang hanya perlu tersedia pada saat jam kerja saja. Alat bernama kube-downscaler dapat digunakan agar klaster dapat melakukan penskalaan keluar atau kedalam pada jam/waktu tertentu. Kube-downscaler dapat dikonfigurasi dengan default uptime melalui variabel lingkungan (environment variabel) seperti berikut:
DEFAULT_UPTIME = Mon-Fri 05:00-19:00 America/Los_AngelesDalam contoh ini, semua deployment akan memiliki ukuran yang diset menjadi 0 kapanpun di luar dari jam 5:00 hingga 19:00, Senin hingga Jumat. Pada tiap namespaces dan deployment dapat mengganti (override) uptime-nya menggunakan anotasi. Dapat juga diatur pembaruan yang berbeda dengan anotasi downscaler/uptime atau bahkan menonaktifkannya sama sekali dengan downscaler/exclude.
Seperti yang ditunjukkan dari grafik di bawah ini, instans EC2 dapat terlihat sbb:
Amazon CloudWatch – EC2 Instance Count

Grafana – Cluster CPU Utilization
Saat mengaktifkan penskalaan turun, kita dapat mengurangi waktu hidup pod (pod hours) dan menghasilkan penambahan penghematan sebesar 15% seperti yang ditunjukkan pada bagan di bawah ini.
Opsi pembelian
Bagian terakhir dari pilar optimasi biaya pada AWS Well-Architected Framework yang akan kita terapkan berasal dari bagian Opsi Pembelian (Purchasing Options) dengan penjelasan sebagai berikut:
“Spot Instances memungkinkan Anda untuk menggunakan kapasitas komputasi cadangan dengan biaya yang jauh lebih rendah daripada mesin EC2 On-Demand (hingga 90%).”
Saat melihat riwayat penetapan harga Spot Instance di konsol EC2, kita melihat bahwa harga spot untuk tipe instans m5.large secara konsisten 55–60% lebih murah daripada menggunakan On-Demand Instance.
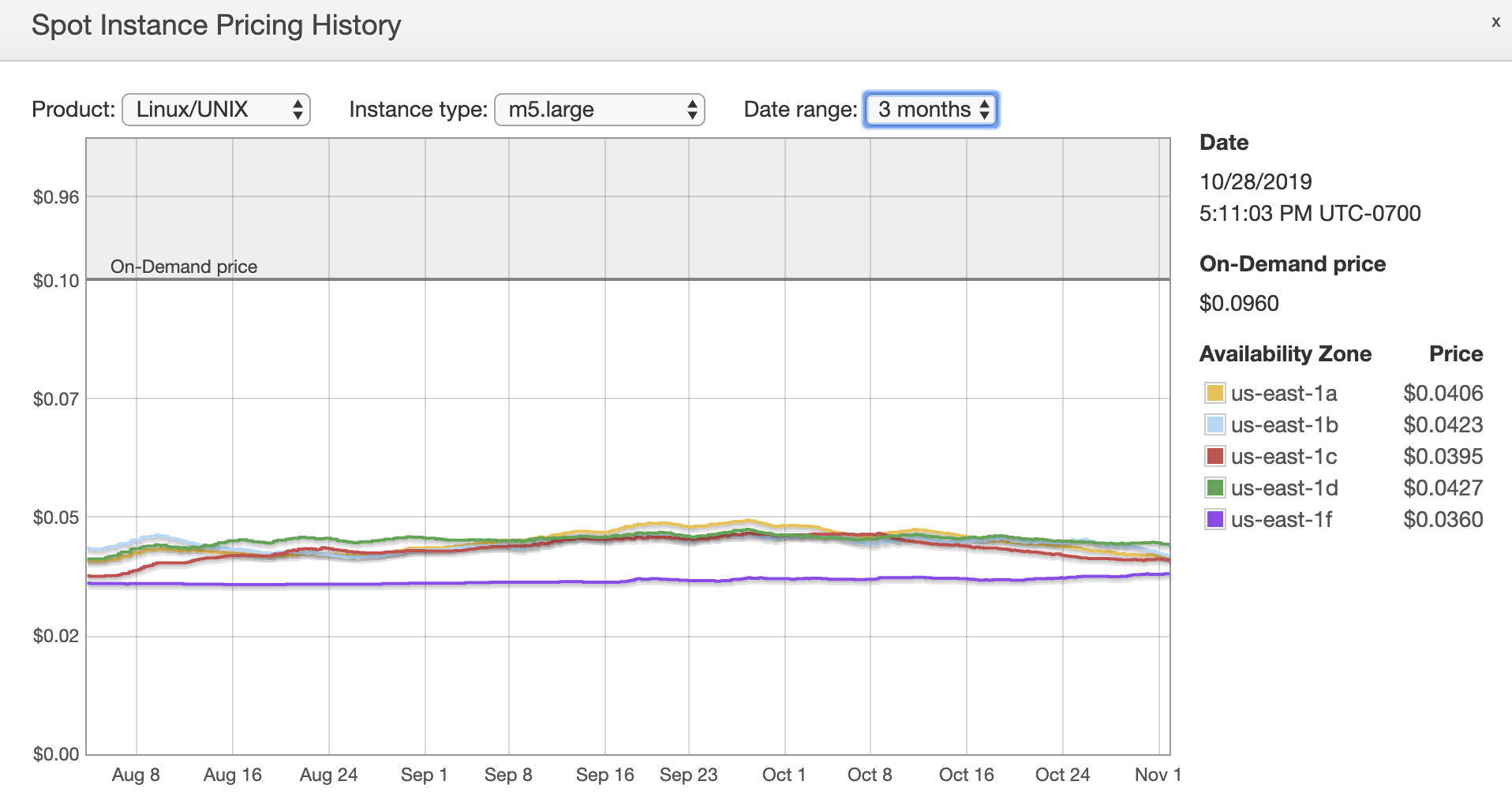
Untuk mengatur node Anda agar dijalankan di Spot Instances dan bukan dengan On-Demand Instances, tinjau tulisan blog AWS Compute berjudul, “Jalankan Beban Kerja Kubernetes Anda di Amazon EC2 Spot Instances dengan Amazon EKS“. Dari pada Anda menjalankan handler terminasi khusus seperti yang dijelaskan di tulisan blog tersebut, sebaiknya pasang alat kube-spot-termination-notice-handler. Ini akan menyediakan mekanisme untuk menjadwal ulang pod-pod ke node lain dengan aman saat terjadi interuspsi pada Spot Instance Anda.
Biasanya kita ingin klaster memiliki Auto Scaling group tambahan yang memiliki On-Demand Instances, di samping Auto Scaling Group dari Spot Instances, yang berfungsi untuk tempat pod yang penting yang tidak toleran terhadap interupsi Spot Instance. Saat menyiapkan node, berikan argumen tambahan di kubelet di setiap Auto Scaling group untuk memberi label yang menandakan node tersebut essential atau preemptible:
- Essential:
--node-labels=kubernetes.io/lifecycle=essential - Preemptible:
--node-labels=kubernetes.io/lifecycle=preemptible
Anda kemudian dapat menggunakan node affinity dalam spesifikasi pod untuk memastikan bahwa pod dijadwalkan pada node yang sesuai:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "kubernetes.io/lifecycle"
operator: "In"
values:
- essentialSetelah memindahkan sebagian besar node ke Spot Instances, kita dapat mengurangi Harga per Instans (instance price) kita dan memperoleh penghematan tambahan sebesar 40% seperti yang ditunjukkan pada grafik di bawah ini. Perhatikan bagaimana penggunaannya tetap sama selama transisi ke spot, tetapi harga turun secara signifikan.
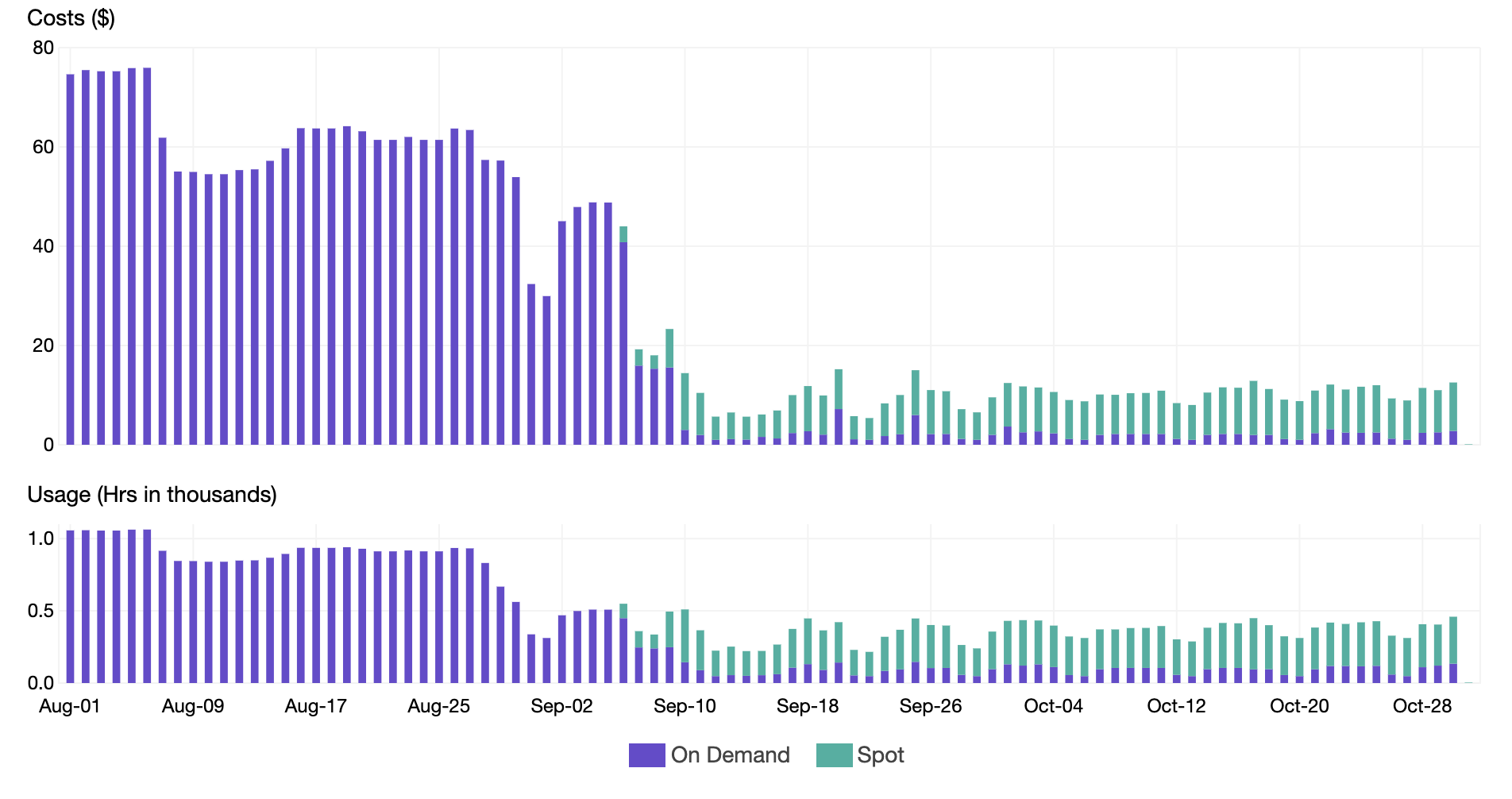
Kesimpulan
Kita dapat menghemat lebih dari 80% dari biaya instans EC2 untuk klaster Kubernetes melalui beberapa cara. Cara pertama adalah penskalaan otomatis pada node dan pod di dalam klaster. Cara kedua adalah penentuan ukuran yang tepat dari sumber daya yang dialokasikan ke container di pod. Selanjutnya, cara ketiga adalah menurunkan penskalaan (scale down) deployment di luar jam kerja. Dan cara terakhir adalah dengan memindahkan sebagian besar pod ke Spot Instances. Semua teknik ini menunjukkan praktik terbaik dari pilar optimisasi biaya pada AWS Well-Architected Framework selain juga membantu pelanggan menjalankan beban kerja Kubernetes mereka secara efisien.
Artikel ini berasal dari artikel Cost optimization for Kubernetes on AWS yang disumbangkan oleh Casey Leed dan diterjemahkan oleh Eryan Ariobowo.