AWS Trainium
Trainium: progettato appositamente per un’IA su larga scala ad alte prestazioni e conveniente
Perché scegliere Trainium?
AWS Trainium è una famiglia di acceleratori di IA appositamente progettati (Trainium1, Trainium2 e Trainium3) e realizzati per offrire prestazioni scalabili ed efficienza dei costi per l’addestramento e l’inferenza su un’ampia gamma di carichi di lavoro di IA generativa.
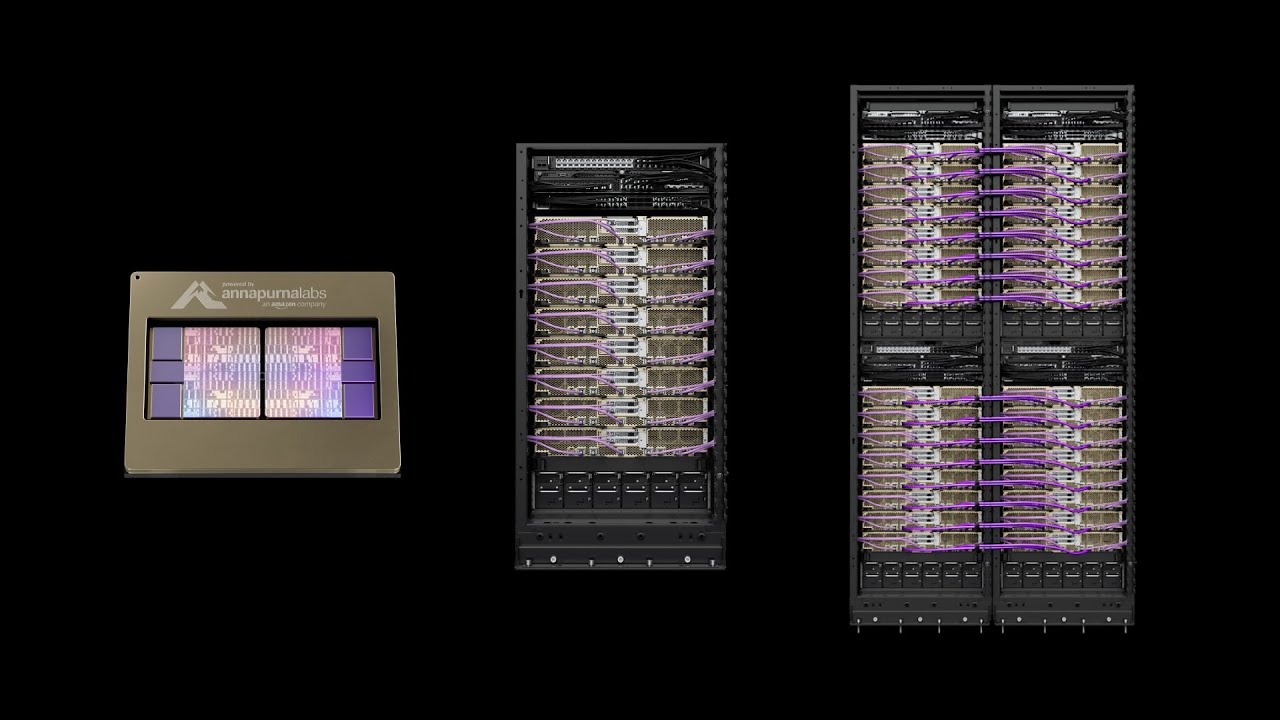
La famiglia AWS Trainium
Trainium1
Il chip AWS Trainium di prima generazione alimenta le istanze Trn1 di Amazon Elastic Compute Cloud (Amazon EC2), che hanno costi di addestramento fino al 50% inferiori rispetto alle istanze Amazon EC2 comparabili. Molti clienti, tra cui Ricoh, Karakuri, SplashMusic e Arcee AI, si stanno rendendo conto dei vantaggi in termini di prestazioni e costi delle istanze Trn1.
Trainium2
Il chip AWS Trainium2 offre prestazioni fino a quattro volte superiori rispetto a Trainium di prima generazione. Le istanze Amazon EC2 Trn2 e Trn2 UltraServers basate su Trainium2 sono realizzate appositamente per l’IA generativa e offrono un rapporto prezzo/prestazioni migliore del 30-40% rispetto a Trn2 EC2 e alle ostanzeP5e basate su GPU. Le istanze Trn2 presentano fino a 16 chip Trainium2 e UltraServer Trn2 con fino a 64 chip Trainium2 interconnessi con NeuronLink, la nostra interconnessione chip-to-chip proprietaria. È possibile utilizzare le istanze Trn2 e gli UltraServer per addestrare e implementare i modelli più impegnativi, che includono modelli linguistici di grandi dimensioni (LLM), modelli multimodali e trasformatori di diffusione, al fine di creare un’ampia gamma di applicazioni di IA generativa di nuova generazione.
Trainium3
Il primo chip AWS basato sull’IA a 3 nm creato appositamente per offrire la migliore economia dei token per applicazioni agentiche, di ragionamento e generazione di video di nuova generazione. Il chip AWS Trainium3 offre prestazioni di elaborazione due volte superiori a 2,52 petaflop (PFLOP) di calcolo FP8, aumenta la capacità di memoria di 1,5 volte e la larghezza di banda di 1,7 volte rispetto a Trainium2 raggiungendo 144 GB di memoria HBM3e e 4,9 TB/s di larghezza di banda di memoria. Gli UltraServer Trn3, alimentati da Trainium3, offrono prestazioni fino a 4,4 volte superiori, una larghezza di banda di memoria 3,9 volte superiore e un’efficienza energetica oltre 4 volte migliore rispetto agli UltraServer Trn2. Trainium3 è progettato per carichi di lavoro sia densi che basati su parallelismo tra esperti, utilizza tipi di dati avanzati (MXFP8 e MXFP4) e offre un migliore equilibrio tra memoria e capacità di calcolo per attività in tempo reale, multimodali e di ragionamento.
Creato per gli sviluppatori
I nuovi UltraServer basati su Trainium3 sono progettati per i ricercatori di IA e sono alimentati dall’SDK AWS Neuron, per ottenere prestazioni eccezionali.
Con l’integrazione nativa di PyTorch, gli sviluppatori possono addestrare e distribuire senza modificare una sola riga di codice. Per gli ingegneri delle prestazioni dell’IA, abbiamo consentito un accesso più approfondito a Trainium3, in modo da poter eseguire il fine-tuning delle prestazioni, personalizzare i kernel e sfruttare al massimo i modelli. L’apertura è alla base dell’innovazione: per questo AWS mette a disposizione degli sviluppatori strumenti e risorse open source per favorire collaborazione e sviluppo.
Per ulteriori informazioni, visita Amazon EC2 Trn3 UltraServers ed esplora l’SDK AWS Neuron.
Vantaggi
Gli UltraServer Trn3 sono dotati delle ultime innovazioni nella tecnologia UltraServer scalabile verticalmente, con NeuronSwitch-v1 per collettivi complessivamente più veloci su un massimo di 144 chip Trainium3. Gli UltraServer Trn3 forniscono fino a 20,7 TB di HBM3e, 706 TB/s di larghezza di banda di memoria e 362 PFLOP MXFP8, offrendo prestazioni fino a 4,4 volte superiori e un’efficienza energetica oltre 4 volte migliore rispetto agli UltraServer Trn2. Trn3 offre prestazioni al minor costo per l’addestramento e l’inferenza con i più recenti modelli MoE (Mixture of Experts) e di ragionamento di tipo 1T+ e consente un throughput significativamente più elevato per il servizio GPT-OSS su larga scala rispetto alle istanze basate su Trainium2.
Gli UltraServer Trn2 rimangono un’opzione ad alte prestazioni e conveniente per l’addestramento dell’IA generativa e l’inferenza di modelli con parametri fino a 1T. Le istanze Trn2 sono datate di un massimo di 16 chip Trainium2, mentre gli UltraServer Trn2 sono dotati di un massimo di 64 chip Trainium2 connessi con NeuronLink, una interconnessione chip-to-chip proprietaria.
Le istanze Trn1 sono dotate di una massimo di 16 chip Trainium e forniscono fino a 3 PFLOP FP8, 512 GB di HBM con 9,8 TB/s di larghezza di banda di memoria e fino a 1,6 Tbps di rete EFA.
L’SDK AWS Neuron consente di estrarre le prestazioni complete dalle istanze Trn3, Trn2 e Trn1 in modo da poterti concentrare sulla creazione e sulla distribuzione di modelli e sull’accelerazione del time-to-market. AWS Neuron si integra in modo nativo con, PyTorch Jax e librerie fondamentali come Hugging Face, vLLM, PyTorch Lightning e altre ancora. Ottimizza i modelli pronti all’uso per l’addestramento distribuito e l’inferenza, offrendo al contempo approfondimenti per la profilazione e il debug. AWS Neuron si integra con servizi come Amazon SageMaker, Amazon Sagemaker Hyerpod, Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), AWS ParallelCluster e AWS Batch, oltre a servizi di terze parti come Ray (Anyscale), Domino Data Lab e Datadog.
Per fornire prestazioni elevate rispettando al contempo gli obiettivi di precisione, AWS Trainium supporta una gamma di tipi di dati
di precisione misti come BF16, FP16, FP8, MXFP8 e MXFP4. Per sostenere il rapido ritmo dell'innovazione nell'IA generativa,
Trainium2 e Trainium3 sono dotati di ottimizzazioni hardware per una sparsità 4x (16:4), microscalabilità, arrotondamento
stocastico e motori collettivi dedicati.
Neuron consente agli sviluppatori di ottimizzare i propri carichi di lavoro utilizzando Neuron Kernel Interface (NKI) per lo sviluppo del kernel. NKI espone l’intero Trainium ISA, consentendo il controllo completo sulla programmazione a livello di istruzione, sull’allocazione della memoria e sulla pianificazione dell’esecuzione. Oltre a creare i propri kernel, gli sviluppatori possono utilizzare la Neuron Kernel Library, che è open source, pronta per distribuire kernel ottimizzati. Infine, Neuron Explore offre una visibilità completa dello stack, connettendosi al codice degli sviluppatori fino ai motori nell’hardware.
Clienti
Clienti come Anthropic, Decart, Poolside, Databricks, Ricoh, Karakuri, SplashMusic e altri stanno ottenendo i vantaggi in termini di prestazioni e costi delle istanze Trn1, Trn2 e Trn3 e degli UltraServer.
I primi ad adottare Trn3 stanno raggiungendo nuovi livelli di efficienza e scalabilità per la nuova generazione di modelli di IA generativa su larga scala.

Conquista le prestazioni, i costi e la scalabilità dell’IA

AWS Trainium2 per prestazioni IA rivoluzionarie

Testimonianze dei clienti dei chip IA di AWS

