Amazon Web Services ブログ
AWS Lake Formation と Amazon Forecast を使用して、エンドツーエンドの自動在庫予測機能を構築する
Amazon Forecast は、機械学習 (ML) により、それまでの機械学習経験を待つことなく、非常に正確な予測を生成できる完全マネージド型サービスです。Forecast は、製品需要の見積もり、在庫計画、労働力計画など、さまざまなユースケースに適用できます。
Forecast では、プロビジョニングするサーバーや手動で構築する機械学習モデルはありません。また、使用した分だけお支払いいただくようになっており、最低料金や前払い料金を求められることはありません。Forecast を使用するために必要なことは、予測対象の履歴データをご提供いただくことだけです。予測に影響を与えると思われる関連データも併せてご提供ください。後者には、価格、行事、天候など、時により変化するデータと、色、ジャンル、リージョンなどカテゴリに関するデータの、両方が含まれます。このサービスでは、お手元のデータに基づいて機械学習モデルを自動的にトレーニングし、デプロイして、予測を取得するためのカスタム API を提供します。
この記事では、データの抽出、変換、および Forecast の使用を自動化して、定期的な在庫の補充を必要とする小売業者のユースケースについて説明します。これを実現するには、AWS Lake Formation を使用して安全なデータレイクを構築し、データを取り込み、AWS Glue ワークフローを使用してデータ変換を調整し、Amazon QuickSight で予測結果を視覚化します。
ユースケースの背景
小売業者は、在庫の補充を繰り返す必要があります。たとえば、通常は e コマースチャネルと実際の店舗チャネルを通じて販売する衣料品小売業者があるとします。倉庫のコストを最小限に抑えながら需要を満たすために、手持ちの在庫の最適なレベルを維持する必要があります。効果的な在庫管理のためのいくつかの共通質問にお答えください。
- 次の販売サイクルに向けてサプライヤーに再注文する際に最適な在庫数量はどれくらいですか?
- サプライヤー宛ての注文書に製品 SKU の構成を含めるには、どうすればよいですか?
- 各小売店で用意する在庫製品の適切な構成と数量を最も効果的に決めるには、どうすればよいですか?
Forecast を使用して、これらの質問に答えることができます。ソースシステムからデータを抽出し、変換を適用してデータを Forecast で使用できるように準備を整え、Forecast を使用してロード、トレーニング、予測を行います。
次の図は、Lake Formation、AWS Glue、および Amazon QuickSight を使用した提案ソリューションのエンドツーエンドシステムアーキテクチャを示しています。
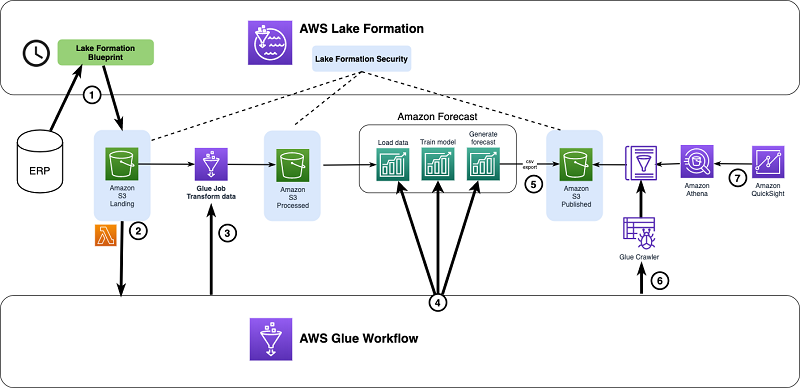
Lake Formation を使用して、データレイクのガバナンスとアクセス制御を管理します。さらに、次のリソースを使用します。
- Lake Formation のブループリントが売上データをデータレイクに取り込む
- AWS Lambda および Amazon S3 イベント通知で AWS Glue ワークフローをトリガーする
- AWS Glue ワークフローでデータ変換 AWS Glue ジョブの実行をトリガーする
- Forecast 内の 3 つのステップ (ロード、トレーニング、予測) を調整する AWS Glue ワークフロー
- Forecast で予測結果をデータレイクにエクスポートする
- AWS Glue がエクスポートされた予測結果でクローラをトリガーする
- Amazon Athena および Amazon QuickSight がエクスポートされた予測結果を視覚化する
必要な IAM ポリシーを設定する
開始する前に、必要な IAM ポリシーを設定する必要があります。次の手順を実行します。
AdministratorAccessAWS 管理ポリシーを持つユーザーとして IAM コンソールにサインインします。- Amazon QuickSight 分析レポートと可視化用のダッシュボードを作成するときに使用する、
report_builderという名前の IAM ユーザーを作成します。 AmazonAthenaFullAccessポリシーをユーザーに付与します。次の手順では、AWS Glue ジョブ、クローラ、およびワークフローの実行中に承認する IAM ロールを作成します。- IAM コンソールで [ロール] を選択します。
- [ロールの作成] を選択します。
- [ロールの作成] ページで、[AWS サービス] と [Glue] を選択します。
- [次: アクセス許可] をクリックします。
- 使用可能なポリシー一覧から、AWSGlueServiceRole ポリシーを検索して選択します。
- ロールに
GLUE_WORKFLOW_ROLEという名前を付けます。 - [ロールの作成] を選択します。
- [ロール] ページで、
GLUE_WORKFLOW_ROLEを検索して選択します。 - [信頼関係] タブで、[信頼関係の編集] を選択します。
- Forecast に次のロールの承認を追加します。
- [信頼ポリシーの更新] を選択します。
- ロール [概要] ページの [アクセス許可] タブで、[インラインポリシーの追加] を選択します。
- 次のインラインポリシーを追加します。
データレイクストレージのセットアップ
次に、この自動化で使用するデータレイクが必要です。データストレージ用の S3 バケットを作成し、適切なセキュリティとガバナンスを適用します。Amazon S3 にすでにデータレイクがある場合は、Lake Formation で引き続き S3 バケットを使用できます。
Amazon S3 コンソールで、次のバケットを作成します。
forecast-blog-landing(生データ取り込み用)forecast-blog-processed(変換されたデータ用)forecast-blog-published(最終消費者が結果にアクセスする用)
この記事には、他の 2 つのフォルダについても繰り返し適用できる、ランディングフォルダのチュートリアル手順が含まれています。
データレイクでの集中アクセス制御を有効にする
Lake Formation の集中型アクセス制御を使用して、ユーザーとロールが基盤となる S3 バケットにアクセスできるようにします。このモデルでは、ユーザーとロール用に追加の IAM アクセスポリシーや S3 バケットポリシーを作成する必要はありません。
- データレイク管理者の IAM ユーザーとして AWS Lake Formation コンソールにサインインします。データレイク管理者ユーザーの設定手順については、データレイク管理者を作成するを参照してください。Lake Formation からのアクセス制御を管理するには、先に作成した 3 つの S3 バケットをデータレイクの場所として Lake Formation に登録します。
- Lake Formation ダッシュボードで、[場所の登録] を選択します。

- Amazon S3 パスの場合は、S3 バケットの場所を入力します (
s3://forecast-blog-landing)。 - [場所を登録] を選択します。

処理済みおよび公開済みの場合、これらの手順を繰り返します。
データレイク向けの Lake Formation データカタログの設定
Lake Formation データカタログには、以前作成した各 S3 バケットに 1 つずつ、3 つのデータベースを作成します。AWS Glue を介して行われるすべての変換は、このカタログのデータベースで動作します。
- Lake Formation コンソールで、[データカタログ] の下にある [データベース] を選択します。
- [データベースの作成] を選択します。

- [データベースの詳細] セクションの [名前] に、データベースの名前を入力します (
forecast-blog-landing-db)。 - [場所] に、対応する S3 バケットへの場所を入力します。
- [説明] に、オプションの説明を追加します。
- [このデータベースの新しいテーブルに IAM アクセス制御のみを使用する] の選択を解除します。
- [データベースの作成] を選択します。

処理済みおよび公開済みの場合、上記の手順を繰り返します。- [データベース] ページで、たった今作成したデータベースを選択します。
- [アクション] ドロップダウンメニューから、[付与] を選択します。

- [IAM ユーザーとロール] で、以前作成した [
GLUE_WORKFLOW_ROLE] を選択します。 - [データベース権限] で、[テーブルの作成] を選択します。
- [付与] を選択します。
 この段階で、Lake Formation を使用してデータレイクを設定しました。次の図は、これまでのリソースを示しています。
この段階で、Lake Formation を使用してデータレイクを設定しました。次の図は、これまでのリソースを示しています。
これで、売上データをデータレイクに取り込む準備ができました。
データの取り込み
この記事では、単一製品の 2 年間の販売履歴を含む sales という MySQL テーブルの例を使用しています。テーブルのスキーマは次のとおりです。
| 列名 | 列タイプ |
InvoiceNo |
int |
StockCode |
int |
Description |
varchar(200) |
Quantity |
int |
InvoiceDate |
varchar(50) |
UnitPrice |
float |
CustomerID |
int |
StoreLocation |
varchar(100) |
CustomerName |
varchar(200) |
- 取り込みを開始するには、ソースデータベースを作成します。次の CloudFormation テンプレートは、この記事に必要なサンプルデータを含む新しい VPC 内に
sales_schemaという名前のデータベースを備えた無料利用枠の RDS MySQL インスタンスを作成します。テンプレートはus-west-2リージョンにデプロイされます。
![]()
- ソースデータベースの新しい Glue 接続を作成します。
- Lake Formation コンソールで、[ブループリント] を選択します。
- [ブループリントを使用] を選択します。
- ソースリレーショナルデータベースから定期的な売上データを取り込むためのブループリントタイプとして、[増分データベース] を選択します。
- プロンプト通りに、増分ブループリントのセットアップを完了します。

- [データベース接続] で、forecast-blog-db を選択します。
- [ソースデータパス] に、「
sales_schema/sales」と入力します。
- [ターゲットデータベース] で、forecast-blog-landing-db を選択します。
- [ターゲットストレージの場所] に、「
s3://forecast-blog-landing」と入力します。 - [日付形式] では、[Parquet] を選択します。

- [ワークフロー名] に、「
forecast-blog-wf」と入力します。 - [IAM ロール] で、[GLUE_WORKFLOW_ROLE] を選択します。
- [テーブルプレフィックス] に「
blog」と入力します。
ターゲットの場所は、以前作成したランディング S3 バケットでなければなりません。テーブルプレフィックスは blog に設定する必要があります。後に続く AWS Glue ジョブが変換して処理する生データです。増分データベースブループリントの使用については、ワークフローを使用したデータのインポートを参照してください。
作成したブループリントを開始します。
データ変換と予測生成の調整
生の販売データをデータレイクのランディングバケットに取り込んだら、カスタム AWS Glue ワークフローを実行して、データ変換の自動化、AWS Forecast のロード/トレーニング/予測の実行を調整し、予測をビジネスダッシュボードで利用できるようにします。次の手順を実行します。
- AWS Glue クローラを作成して、以前作成した
公開済みの S3 バケットをクロールします。- 以前作成した
GLUE_WORKFLOW_ROLEを使用します。
- 以前作成した
- 予測の自動化で使用する次の AWS Glue ジョブを作成します。
- データ変換ジョブを Spark ジョブとして作成し、残りのジョブを Python シェル (Python 3) ジョブとして作成します。
- [IAM ロール] に、
GLUE_WORKFLOW_ROLEを使用します。
- [接続] ページで、接続を選択せずに [ジョブを保存してスクリプトを編集] を選択します。GitHub では次のジョブを利用できます。
- データ変換ジョブ (Spark)
- Forecast にデータをインポートする (Python シェル: Python 3)
- 読み込みデータのジョブステータスを確認する (Python シェル: Python 3)
- Forecast 予測子をトレーニングする (Python シェル: Python 3)
- トレーニング予測子のジョブステータスを確認する (Python シェル: Python 3)
- 予測を生成する (Python シェル: Python 3)
- 予測ジョブのステータスを確認する (Python シェル: Python 3)
- データレイク公開バケットへの予測をエクスポートする (Python シェル: Python 3)
- エクスポート予測ジョブのステータスを確認する (Python シェル: Python 3)
次に、新しい AWS Glue ワークフローを作成して、自動化全体を調整します。ワークフローを使用すれば、トリガーを介して一連の AWS Glue ジョブとクローラを構築および調整し、複雑なプロセスを完了することができます。
- AWS Glue コンソールで、[ワークフロー] を選択します。
- [ワークフローを追加] を選択します。

- [ワークフロー名] に、「
AmazonForecastWorkflow」と入力します。 - [説明] に、オプションの説明を追加します。
- [デフォルトの実行プロパティ] で、次の表のキーと値を入力します。
| キー | 値 |
landingDB |
forecast-blog-landing-db |
landingDBTable |
blog_sales_schema_sales |
processedBucket |
forecast-blog-processed |
publishedBucket |
forecast-blog-published |

- 以前作成したワークフローを選択します。
- [トリガーの追加] を選択します。
- [名前] に、「
StartWorkflow」と入力します。 - [トリガータイプ] で、[オンデマンド] を選択します。
- [追加] をクリックします。

- [ジョブ] タブで、以前作成したジョブを選択します。
- [追加] をクリックします。

- [ノードを追加] を選択します。
- 新しいトリガーを作成して、変換ジョブの終了を監視し、データインポートジョブを開始します。
- [名前] に、「
StartDataImport」と入力します。 - [トリガータイプ] で、[イベント] を選択します。
- [トリガーロジック] で、[監視対象のイベントが発生した後に開始する] のままにします。
- [追加] をクリックします。

- トリガーの左側にある [ノードの追加] を選択し、以前作成したデータ変換ジョブを選択します。

- トリガーの右側にある [ノードの追加] を選択し、以前作成したデータインポートジョブを選択します。

- これらの手順を繰り返して、次のトリガーを作成します。
| トリガー | 完了する Glue ジョブ | 開始する Glue ジョブ |
| CheckImportTrigger |
Forecast へのデータのインポート
|
読み込みデータのジョブステータスを確認する |
| StartPredictorTrigger |
読み込みデータのジョブステータスを確認する
|
Forecast 予測子をトレーニングする
|
| CheckPredictorTrigger |
Forecast 予測子をトレーニングする
|
トレーニング予測子のジョブステータスを確認する |
| GenerateForecastTrigger | トレーニング予測子のジョブステータスを確認する | 予測を生成する |
| CheckForecastTrigger | 予測を生成する | 予測ジョブのステータスを確認する |
| ExportForecastTrigger | 予測ジョブのステータスを確認する | データレイク公開バケットへの予測をエクスポートする |
| CheckExportTrigger | データレイク公開バケットへの予測をエクスポートする |
エクスポート予測ジョブのステータスを確認する
|
| StartCrawlerTrigger |
エクスポート予測ジョブのステータスを確認する
|
作成したクローラで、公開された S3 バケットをクロールする |
- [アクション] ドロップダウンメニューから、[実行] を選択します。
これにより、エンドツーエンドの予測プロセスが開始されます。
予測の視覚化
新しい予測で定期的に更新されるダッシュボードをユーザーに提供するには、Amazon QuickSight レポートとダッシュボードをセットアップし、Athena を介してデータレイクに接続します。Amazon QuickSight と Athena データソースを使用して、予測データにアクセスし、視覚化を行うことができます。
まず、QuickSight に予測データへのアクセスを許可する必要があります。アカウントで Amazon QuickSight のサービスロールを特定します。Amazon QuickSight は、他の AWS サービスとやり取りするためのサービスロール (aws-quicksight-service-role-v0) を承認します。サービスロールは、Amazon QuickSight の使用を開始するときに自動的に作成されます。
- データレイク管理者ユーザーとして、Lake Formation コンソールで、AWS Glue ワークフローによって
published-dbの下に作成されたテーブルを見つけます。これは、視覚化するためにエクスポートされた予測データを含むテーブルです。 - Lake Formation 内の付与アクションを使用して、このテーブルの Amazon QuickSight サービスロールへの選択アクセスを許可します。詳細については、データカタログのアクセス許可の付与を参照してください。ここで、Amazon QuickSight で予測データを視覚化するダッシュボードを作成します。
- Amazon QuickSight コンソールで、[データの管理] を選択します。
- Athena のデータソースを作成します。
- [データソース名] に、「
forecast-blog-published-db」と入力します。 - [データソースの作成] を選択します。

- [データベース] で、「forecast-blog-published-db」を選択します。
- クローラがエクスポートされた予測 (forecast_blog_published) 用に作成したテーブルを選択します。
- [選択] を選択します。

- [視覚化] を選択します。

- データセットで新しい分析を作成します。
- 視覚化ダッシュボードを公開します。次は、エクスポートされた予測を表示する QuickSight ダッシュボードのスクリーンショットです。ダッシュボードは、y 軸で選択した列
p10、p50、およびp90の値と x 軸で選択した日付を使用して行った折れ線グラフ分析から作成しました。
Forecast は確率的な予測を生成するため、特定のユースケースに応じて異なるパーセンタイルで予測を生成できます (たとえば、在庫不足や在庫過剰がビジネスにとって重要な場合)。上記のグラフは、サンプルデータ内製品の予測在庫値の上位幅と下位幅、10 日間で選択した場所 (フィルター適用) を表しています。これを使用して、その週に保持または注文する在庫の最適レベルを決定できます。
p10 は下限です。実際の値がこの線を下回る可能性は 10% しかありません。ただし、P90 は上限です。実際の値がこの線を下回る確率は 90% です。トレーニングデータがより包括的になると、p10 と p90 は収斂し始めます。また、選択したカスタム分位数に基づいて予測を生成することもできます。
控えめに計画を立てる場合は、p90 に近い値を選択します。実際に販売するよりも多くの在庫を購入する意思があることを意味します。積極的に計画を立てる場合は、p10 に近い値を選択します。在庫不足のリスクを受け入れる用意ができていることを意味します。
まとめ
この記事では、予測と Lake Formation 経由で AI を使用して AWS でビジネスの自動在庫予測機能を構築する方法を学びました。Lake Formation を使用して、必要なセキュリティガバナンスを備えた AWS 上でのデータレイクを設定する方法を学びました。また、販売データをデータレイクに取り込み、データ変換を自動化するエンドツーエンドのプロセスを自動化する方法、Forecast を使用して予測をロード、トレーニング、生成する方法についても学びました。また、Amazon QuickSight の視覚化を介して、エンドユーザーが予測にアクセスできるようにします。
著者について
 Syed Jaffry は、アマゾン ウェブ サービスのソリューションアーキテクトです。彼は、金融サービス業界の顧客と協力して、安全で回復力があり、スケーラブルで高性能なアプリケーションをクラウドにデプロイするのを支援しています。
Syed Jaffry は、アマゾン ウェブ サービスのソリューションアーキテクトです。彼は、金融サービス業界の顧客と協力して、安全で回復力があり、スケーラブルで高性能なアプリケーションをクラウドにデプロイするのを支援しています。