Amazon Web Services ブログ
AWS Glue でメモリ管理を最適化する
AWS Glue は、Apache Spark のパワーを使用して分析用のデータセットを準備および処理するサーバーレス環境を提供します。シリーズの第 3 回目の記事では、AWS Glue が一般的なデータ変換を実行するコードを自動的に生成する方法について説明しました。また、AWS Glue ワークフローを使用して、分析のためにデータを簡単に取り込んで変換し、ロードできるデータパイプラインを構築する方法も見てきました。
Apache Spark には、さまざまなワークロードに対してメモリがどのように管理されるかを制御するためのノブがいくつもあります。ただし、これは厳密な科学ではなく、非効率的な変換ロジック、最適化されていないデータ分割、または基盤となる Spark エンジンの他の特異な動作のために、アプリケーションにさまざまなメモリ不足 (OOM) の例外が発生する可能性があります。本シリーズのこの記事では、Glue Spark ETL ジョブの内部処理について詳しく説明し、AWS Glue 機能を Spark のベストプラクティスとどう組み合わせて、ジョブをスケーリングしてデータの多様性とボリュームを効率的に処理するかについて説明します。
Apache Spark ドライバーのスケーリング
Apache Spark ドライバーは、ジョブを分析および調整し、作業をタスクに分散させて、可能な限り最も効率的な方法でジョブを完了できるようにします。ETL ジョブの大部分で、ドライバーは通常、Amazon S3 でテーブルパーティションとデータファイルを一覧表示してから、ファイル分割を計算して個々のタスクを処理しています。ドライバーは次に、各ファイル分割を処理する変換タスクを調整します。さらに、ドライバーは各タスクの進行状況を追跡し、最後に結果を収集する必要があります。ジョブが多数のファイルとパーティションを処理する必要がある場合、Spark ドライバーがボトルネックになる可能性があります。AWS Glue は、多数のファイルを処理する際、Spark ドライバーのメモリを効率的に管理するための 5 つの異なるメカニズムを提供しています。
- プッシュダウン述語: Glue ジョブでは、プッシュダウン述語を使用して、基になるデータを読み取る前に、テーブルから不要なパーティションをプルーニングできます。これは、テーブルに多数のパーティションがあり、Glue ETL ジョブでそのサブセットのみを処理する場合に便利です。カタログパーティションをプルーニングすると、ドライバーのメモリフットプリントが削減され、さらにプルーニングパーティション内のファイルを一覧表示するために必要な時間が短縮されます。不要なパーティションを無視するために先ずプッシュダウン述語を適用してから、ジョブのブックマークやその他の除外によって、各パーティションから読み取られるファイルのリストをさらにフィルタリングできます。以下は、週末に限って記録されたイベントのデータのみを処理するためにプッシュダウン述語を使用する方法の例です。
- Glue S3 Lister: AWS Glue は、DynamicFrame にデータを読み込んでいる間に S3 のファイルをリストする最適化されたメカニズムを提供します。Glue S3 Lister を有効にするには、DynamicFram の additional_options パラメータ useS3ListImplementation を「True」に設定します。Glue S3 Lister は、読み取られるフィルタリング済みファイルの最終リストを厳密に反復することにより、デフォルトの S3 リストの実装よりも優れた点があります。
- グループ化: AWS Glue では、ファイルのグループ化 機能を使用して、Spark タスクごとに複数のファイルを統合できます。ファイルをグループ化すると、Spark ドライバーのメモリフットプリントが削減され、ファイル分割オーケストレーションが簡素化されます。グループ化しない場合、Spark アプリケーションは別の Spark タスクを使って各ファイルを処理する必要があります。次に、各タスクは、位置情報を含む mapStatus オブジェクトを Spark ドライバーに送信する必要があります。AWS Glue の標準ワーカータイプを使用したテストでは、次のエラーメッセージに示されているように、約 650,000 を超えるファイルを処理する Spark アプリケーションがメモリ不足の例外でクラッシュすることがよくあります。
groupFilesにより、Hive スタイルの S3 パーティション内 (inPartition) および S3 パーティション間 (acrossPartition) でファイルをグループ化できます。groupSizeは、各ファイルから読み取り、個々の Spark タスクで処理するデータの量を設定できるオプションのフィールドです。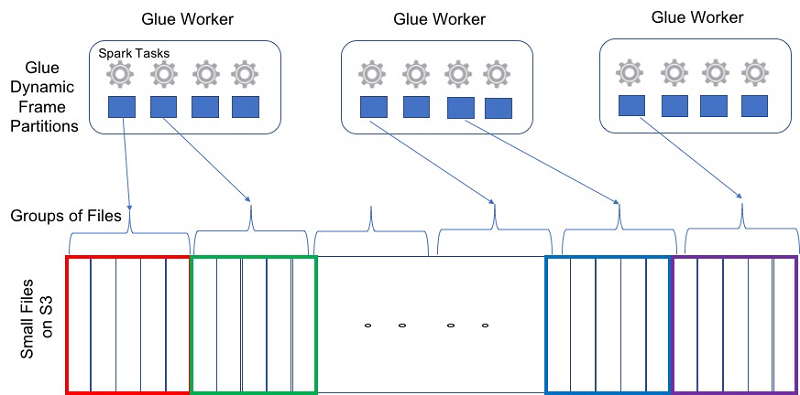
- S3 パスの除外: ジョブに不要なファイルのフィルタリングをさらにしやすくするために、AWS Glue は、除外する S3 パスのグロブ式をユーザーが指定できるようにしたメカニズムを導入しました。これにより、Spark ドライバーのメモリフットプリントを削減しながら、ジョブ処理が高速化されます。次のコードスニペットは、選択した S3 パスで_metadata で終わるすべてのオブジェクトを除外する方法を示しています。
S3 ストレージクラスの除外: AWS Glue は、基盤となる S3 ストレージクラスに基づいてオブジェクトを除外する機能を提供します。データのライフサイクルが進行するにつれ、ホットデータはコールドデータになり、設定された S3 バケットポリシーに基づいて自動的に低コストのストレージに移動します。ここで重要なのは、ETL ジョブが正しいデータを処理することを保証することです。これは、Apache Parquet ファイル形式を使用して、複数の S3 ストレージクラスにまたがる大規模なデータセットを処理する場合に特に便利です。その際、Spark がこのようなストレージクラスにあるファイルのフッターからスキーマを読み取ろうとします。Amazon S3 は、STANDARD、INTELLIGENT_TIERING、STANDARD_IA、ONEZONE_IA、GLACIER、DEEP_ARCHIVE、REDUCED_REDUNDANCY の 5 つの異なるストレージクラスを提供しています。DynamicFrames を使用してデータを読み取る場合、除外する S3 ストレージクラスのリストを指定できます。この機能は、最適化された AWS Glue S3 Lister を利用します。 次の例は、GLACIER および DEEP_ARCHIVE ストレージクラスに格納されているファイルを除外する方法を示しています。
GLACIER および DEEP_ARCHIVE ストレージクラスはファイルを一覧表示することのみを許可し、実際のデータを読み取るには非同期の S3 リストアプロセスが必要です。以下は、Glue ETL ジョブから Glacier および Deep Archive ストレージクラスにアクセスしようとしたときに表示される例外です。
- Spark クエリを最適化: 非効率的なクエリまたは変換は、Apache Spark ドライバーのメモリ使用率に大きな影響を与える可能性があります。一般的な例は次のとおりです。
収集は、ワーカーから結果を収集してドライバーに返す Spark アクションです。場合によっては、結果が非常に大きく、ドライバーを圧倒することがあります。以下に示すように、Spark ドライバーの OOM 例外が頻繁に発生する可能性があるため、収集を使用する際は注意することをお勧めします。- シェア変数: Apache Spark は、Spark ドライバーとエグゼキュータの間で変数を共有する 2 つの別個の方法を提供します。それは、ブロードキャスト変数とアキュムレータです。ブロードキャスト変数は、マップ側の結合を改善するために Spark ワーカー間で共有されるデータまたはファクトテーブルの読み取り専用コピーを提供するのに役立ちます。アキュムレータは、書き込み可能なコピーを提供し、Spark エグゼキュータ全体に分散カウンターを実装するのに役立ちます。ブロードキャスト変数とアキュムレータのどちらも慎重に使用し、不要になったら破棄する必要があります。これは、Spark ドライバーの OOM 例外が頻繁に発生する可能性があるためです。
Apache Spark エグゼキュータのスケーリング
Apache Spark エグゼキュータはデータを並行して処理します。ただし、JDBC ソースからの最適化されていない読み取り、不均衡なやり取り、PySpark UDF による行のバッファリング、各 Spark ワーカーのオフヒープメモリの超過、パーティションのサイズのスキューにより、Spark エグゼキュータ OOM 例外が発生する可能性があります。OOM 例外の原因となるこれらの状況が発生するのを回避するための AWS Glue および Apache Spark のベストプラクティスの一部を以下に示します。
- JDBC 最適化: Apache Spark は JDBC ドライバーを使用して、MySQL、PostgresSQL、Oracle などの JDBC ソースからデータをフェッチします。
- フェッチサイズ: デフォルトでは、Spark JDBC ドライバーのフェッチサイズがゼロに設定されています。つまり、Spark トランスフォーメーションは一度に 1 行ずつしかストリーミングしませんが、Spark エグゼキュータの JDBC ドライバーは、1 回のネットワークの往復でデータベースからすべての行をフェッチしてメモリにキャッシュしようとします。これにより、次の例外を除き、Spark エグゼキュータがメモリ不足になる可能性があります。
Spark では、フェッチサイズパラメータのデフォルト値をゼロ以外に明示的に設定することで、このシナリオを回避できます。AWS Glue では、Dynamic Frames が、JDBC ドライバーのキャッシュされた行のサイズを制限する 1,000 行のフェッチサイズを自動的に使用し、Spark エグゼキュータとデータベースインスタンス間のネットワークの往復のレイテンシーから生じるオーバーヘッドを漸減します。以下の例は、Glue 動的フレームを使用して JDBC ソースから読み取る方法を示しています。
- フェッチサイズ: デフォルトでは、Spark JDBC ドライバーのフェッチサイズがゼロに設定されています。つまり、Spark トランスフォーメーションは一度に 1 行ずつしかストリーミングしませんが、Spark エグゼキュータの JDBC ドライバーは、1 回のネットワークの往復でデータベースからすべての行をフェッチしてメモリにキャッシュしようとします。これにより、次の例外を除き、Spark エグゼキュータがメモリ不足になる可能性があります。
- Spark の読み取りパーティション: デフォルトでは、Apache Spark が データベースとの JDBC 接続を開き、テーブル全体を Spark データフレームに読み込むのに、エグゼキュータを 1 つしか使用していません。これにより、さまざまなエグゼキュータ間で処理されるデータの分散が不均衡になる可能性があります。その結果、
partitionColumn、lowerBound、upperBound、およびnumPartitionsを使用して、異なるエグゼキュータからの並列読み取りを可能にすることが通常お勧めです。これにより、均一な値の分布を持つ列が存在する場合、よりバランスのとれたパーティション化が可能になります。ただし、Apache Spark はpartitionColumnを数値、日付、またはタイムスタンプのいずれかのデータ型に制限します。例: - Glue の読み取りパーティショニング: AWS Glue では、文字列などの一般的なタイプの列に基づいて、JDBC テーブルをパーティション化できます。これにより、重複しない並列 SQL クエリを使用して、JDBC ソースから読み取ることができます。このクエリは、異なる Spark エグゼキュータからのテーブルの論理パーティションに対して実行されます。
hashfieldまたはhashexpressionを設定することにより、パーティショニングを制御できます。また、hashpartitionsを指定することで、データへのアクセスに使用される並列読み取りの数を制御することもできます。最良の結果を得るには、パーティション間でデータを分散するために、この列の値が均等に分布している必要があります。たとえば、データが月ごとに均等に分散されている場合、month列を使用して、データの各月を並行して読み取ることができます。データベースインスタンスタイプに基づいて、hashpartitionsを調整することにより、並列接続の数を調整できます。例: - 一括挿入: AWS Glue は、JDBC ターゲットへの一括ロードを高速化するための並列挿入を可能にしています。次の例では、2 のバルクサイズを使用することで、、2 つの挿入を並行して実行できます。これは、Aur などのデータベースへの書き込みのパフォーマンスを向上させるのに役立ちます。
- 結合の最適化: Apache Spark アプリケーションがメモリ不足になる一般的な理由の 1 つに、2 つ以上のテーブル間の結合が最適化されていないことがあります。これは通常、結合列の分散または結合変換の非効率的な選択によりデータスキューが発生することで生じます。さらに、ユーザースクリプトでの変換とフィルターの順序によっては、Spark クエリプランナーの最適化機能が制限される場合があります。AWS Glue での結合を最適化するための一般的なアプローチは 3 つあります。
- 結合前にテーブルをフィルタリングする: 結合する前に、テーブルをできるだけ事前にフィルタリングする必要があります。これにより、ネットワーク上のエグゼキュータ間でやり取りされるデータを最小限に抑えることができます。AWS Glue のプッシュダウン述語を使用して、パーティション列に基づいてフィルタリングできます。また AWS Glue の除外を使用して、ファイル名に基づいてフィルタリングできます。さらに AWS Glue ストレージクラス除外を使用して S3 ストレージクラスに基づいてフィルタリングできます。また、列値の最小/最大などの列統計に基づく行グループの破棄をサポートする Parquet や ORC などの列ストレージ形式を使用できます。
- 小さなテーブルをブロードキャストする: テーブルを結合すると、異なるワーカーで実行されているエグゼキュータ間で、ネットワークを介して大量のデータのやり取りまたは移動が行われる可能性があります。このため、Spark はメモリを使い果たし、ワーカーの物理ディスクにデータを書き出す可能性があります。この動作は、次のログメッセージで確認できます。
結合内のテーブルの 1 つが数十 MB と小さい場合、Spark に別の方法で処理するように指示できます。これにより、データをやり取りすることで生じるオーバーヘッドが削減されます。これは、小さいテーブルを、ネットワーク全体で分割してやり取りするのではなく、ブロードキャストするように Apache Spark に示すことで行えます。Spark パラメータ
spark.sql.autoBroadcastJoinThresholdは、結合の実行時にすべてのワーカーノードにブロードキャストされるテーブルの最大サイズをバイト単位で設定します。Apache Spark は、テーブルが 10 MB 未満になると自動的にブロードキャストします。次の例に示すように、ブロードキャストするテーブルを Spark に明示的に指示することもできます。
- PySpark ユーザー定義関数 (UDF): PySpark UDF を使用すると、エグゼキュータのメモリにコストがかかる場合があります。これは、Spark エグゼキュータ JVM と Python インタープリター間でデータを交換するときに、データをシリアル化/非シリアル化する必要があるためです。 Python インタープリターは、シリアル化されたデータを Spark エグゼキュータのオフヒープメモリで処理する必要があります。大きなレコードやネストされたレコードがあるデータセットの場合、または複雑な UDF を使用している場合、この処理は大量のオフヒープメモリを消費し、Yarn のオーバヘッドメモリの超過が原因で OOM 例外が発生する可能性があります。その場合、次のようなエラーメッセージを受け取ります。
同様に、データのシリアル化は遅くなることがあり、多くの場合、ジョブの実行時間が長くなります。このような OOM の例外を回避するには、Python ではなく Scala または Java で UDF を記述することをお勧めします。これらは、Glue ジョブ設定で Dependent Jars の S3 パスを指定することでインポートできます。PySpark UDF でオフヒープメモリ内の大きなレコードのバッファリングを回避するための最適化手段には、他にもアップストリームの選択とフィルタリングを AWS Glue スクリプトの初期の実行ステージで実行することがあります。
- 段階的に処理: S3 で大きなデータセットを処理すると、コストのかかるネットワークのやり取り、メモリからディスクへのデータの書き込み、および OOM 例外が発生する可能性があります。これらのシナリオを回避するには、AWS Glue Job Bookmarks、プッシュダウン述語、および除外を使用して、大規模なデータセットを段階的に処理することがベストプラクティスです。同時実行ジョブは、S3 パーティションを個別に処理できます。また大きな Spark パーティションや、データスキューによる不均衡なデータのやり取りが原因で OOM が発生する可能性を最小限に抑えることができます。より高いメモリインスタンスを伴う垂直スケーリングでは、オフヒープメモリが不十分であったり、Apache Spark アプリケーションが最適化できないことが原因で OOM 例外が発生する可能性を軽減できます。
より多くのメモリとディスク領域を提供する Glue の G.1X および G.2X ワーカータイプを使用することもできます。これにより、中間のシャッフル出力を格納するために大量のメモリまたはディスク領域を必要とする Glue ジョブを垂直方向にスケーリングできます。Glue ジョブの垂直スケーリングについては、このシリーズの最初のブログ記事で説明しています。
まとめ
この記事では、JDBC コネクタを使用して Amazon S3 および互換性のあるデータベースからデータを読み取るときに、Apache Spark アプリケーションの効率的なメモリ管理を可能にする手法をいくつかご紹介しました。Glue ETL ジョブが AWS Glue データカタログから利用できるパーティション情報を利用して、大規模なデータセットをプルーニングし、多数の小さなファイルを管理する方法について説明しました。また JDBC の最適化を使用して、データベースからのパーティション化された読み取りとバッチレコードフェッチする方法についても説明しました。これらの手法の一部またはすべてを使用して、ETL ジョブが適切に実行されるようにすることができます。
次の記事では、このような最適化が取り入れられた Glue Spark Runtime を使用して、ノートパソコンからローカルで Apache Spark アプリケーションと ETL スクリプトを開発する方法について説明します。Maven から入手できる Glue Spark ランタイムに対してビルドするか、クロスプラットフォームサポート向けの Docker コンテナを使用してビルドできます。開発には、Jupyter/Zeppelin ノートブック、または PyCharm などのお気に入りの IDE を使うことができます。そして開発した Spark アプリケーションを AWS Glue のサーバーレス Spark プラットフォームにデプロイできます。
著者について
 Mohit Saxena は AWS Glue のテクニカルリードマネージャーです。彼はクラウドのデータの効率的な管理を目指して、スケーラブルな分散システム構築に熱心に取り組んでいます。また、映画鑑賞や最新テクノロジーについての本を読むことが好きです。
Mohit Saxena は AWS Glue のテクニカルリードマネージャーです。彼はクラウドのデータの効率的な管理を目指して、スケーラブルな分散システム構築に熱心に取り組んでいます。また、映画鑑賞や最新テクノロジーについての本を読むことが好きです。