Amazon Web Services ブログ
Category: AWS Glue
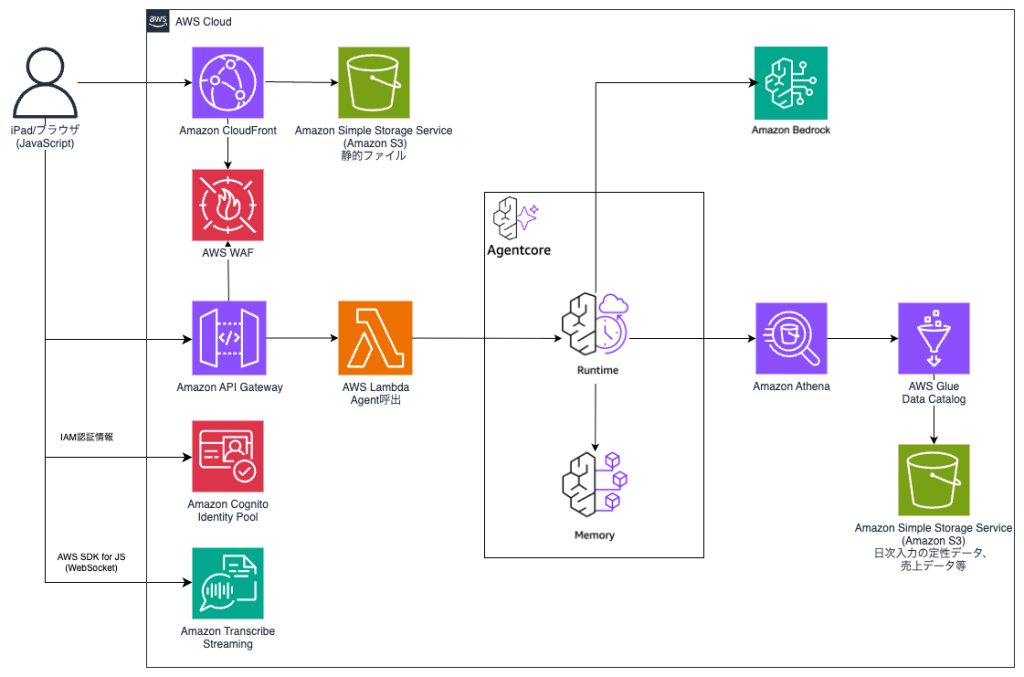
店舗の気づきを本部に届ける AI エージェント SMART のご紹介 — Amazon Bedrock AgentCore × Strands Agents によるユナイテッドアローズでの取り組み
本記事では、AWS サンプルアセットである AI エージェント SMART(Store Manager Agent for Retail Tech) についてのご紹介と、それを活用した株式会社ユナイテッドアローズ(以下、ユナイテッドアローズ)の取り組みについてご紹介します。小売業にとって、店舗の声をどう本部に届けるかは永遠のテーマです。売上数字の裏には、現場スタッフだけが感じている気づきが必ずあります。しかし店舗の日報や週報のフォーマットだけでは、その気づきを届けるのは難しいのが実情です。SMART は、店舗の気づきを AI の力で引き出し言語化して、本部に届けることを支援するために誕生しました。

Amazon Aurora スナップショットから Amazon Aurora DSQL へのデータ移行
Amazon Aurora DSQL はサーバーレスの分散 SQL データベースで、データ移行には COPY コマンドや dataloader スクリプトが利用できますが、テーブル単位の処理しかできず、データ変換の手段もありません。本記事では AWS Glue を使い、Aurora PostgreSQL のスナップショットから Aurora DSQL へ、データ型変換や主キーの UUID 化を含めて移行する手順を紹介します。
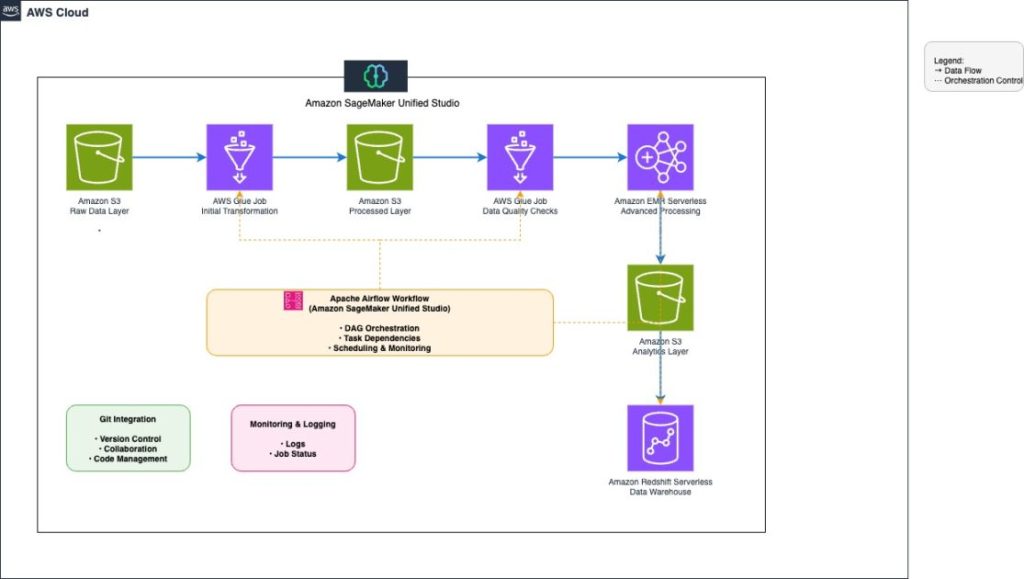
Amazon SageMaker ワークフローによるスケーラブルなエンドツーエンド ETL パイプラインのオーケストレーション
本記事では、Amazon SageMaker Unified Studio ワークフローでコードベースのエンドツーエンド ETL パイプラインを構築・管理する方法を紹介します。AWS Glue、Amazon EMR Serverless、Amazon Redshift Serverless、Amazon MWAA を組み合わせ、EC の顧客行動分析を例に、データ取り込みから変換、品質チェック、データウェアハウスへのロード、日次スケジュール実行まで、単一の統合 UI で構築する手順を解説します。

Amazon DataZone によるデータガバナンスのスケール: Covestro の事例
本記事では、Covestro が中央集権型のデータレイクから Amazon DataZone と AWS Serverless Data Lake Framework (SDLF) を使ったデータメッシュアーキテクチャへ移行した事例を紹介します。標準化されたブループリントと自動化されたガバナンスにより、1,000 を超えるデータパイプラインを運用しながら市場投入までの時間を 70% 短縮し、部門横断のデータ共有と品質管理を実現した経緯を解説します。

Fivetran の Managed Data Lake Service の CDC で実現する業務システムから Apache Iceberg へのリアルタイムデータ連携
本記事は アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト 疋田、畠 と、Fivetr […]

アプリケーションを変更せずに Amazon SageMaker Catalog でデータメッシュパターンを実装する
Amazon SageMaker Catalog を使用してデータメッシュパターンを実装する方法を説明します。既存のアプリケーションやデータリポジトリを変更せずに、Amazon SageMaker Unified Studio でデータをオンボード、公開、サブスクライブする手順を紹介します。

AWS で DER アグリゲーター向けのスケーラブルな DERMS ソリューションを構築する
エネルギー環境が分散型モデルへと進化する中、分散型エネルギーリソース (DER) は、エネルギー市場のさまざまなプレーヤー (電力会社、立法機関、アグリゲーター、消費者、サービスプロバイダー) に課題と機会の両方をもたらしています。
さまざまな関係者が Amazon Web Services (AWS) を活用して DER を最大限に活用する方法について、一連のブログを計画しています。最初のブログでは、アグリゲーターが事業の成長に合わせて拡張できる堅牢な分散型エネルギーリソース管理システム (DERMS) を構築するために、AWS サービスがどのように役立つかを探ります。

AWS Glue 5.0 の Apache Spark におけるオープンテーブルフォーマット機能の活用
この記事では、AWS Glue 5.0 における Apache Iceberg、Delta Lake、Apache Hudi のオープンテーブルフォーマットライブラリの主要なアップデートについて解説します。ブランチとタグによるライフサイクル管理、変更ログビュー、ストレージパーティション結合などの新機能を紹介します。

AWS Glue Data Catalog のテーブル統計自動収集機能の紹介 – Amazon Redshift と Amazon Athena のクエリパフォーマンス向上
AWS Glue Data Catalog で、新しいテーブルの統計情報を自動的に生成できるようになりました。この機能により、Amazon Redshift Spectrum と Amazon Athena のコストベースオプティマイザー (CBO) がクエリを最適化し、パフォーマンス向上とコスト削減を実現します。
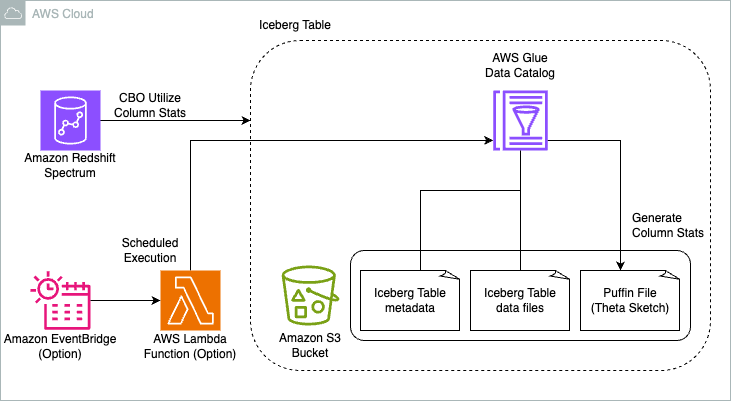
AWS Glue Data Catalog で Apache Iceberg 統計情報を収集してクエリパフォーマンスを高速化する
AWS Glue Data Catalog で Apache Iceberg テーブルのカラムレベル統計情報を生成し、Redshift Spectrum と Amazon Athena のクエリパフォーマンスを最大 83% 向上させる方法を紹介します。