Amazon Web Services ブログ
Category: Customer Solutions

富士電機ITソリューションが挑戦する働き方の大変革 〜Amazon Q Developer 活用から Kiro による新しい企業価値創出へ〜
この記事では、富士電機ITソリューション株式会社(以下、FSL)が Amazon Q Developer Pro サブスクリプションを活用し、開発者が実施する業務だけではなく日常業務でも生成 AI を取り込むことで、業務効率化のその先にある新しい企業価値の創出へと歩みを進めている旅路をご紹介します。AWS は、Amazon Q Developer や Kiro をはじめとするコーディングエージェントや生成 AI サービスを通じて、お客様ならではの価値創出の旅路を引き続きサポートしてまいります。生成 AI を活用した開発変革について、ぜひ AWS の担当者にご相談ください。

AWS GenAIIC の技術支援で実現する建設・BIM 特化基盤モデル開発 — GENIAC 第 3 期 ONESTRUCTION Ishigaki-IDS 事例
本ブログは ONESTRUCTION 株式会社様と Amazon Web Services Japan 合同会 […]

実践企業に学ぶ生成 AI 導入の勘所 〜眠るデータを企業価値に変える〜 – AWS Local Executive Roadshow 名古屋編(#3/8)開催レポート
こんにちは。Amazon Web Services Japan のソリューションアーキテクト、田中 里絵 です […]

AI ツールで実現する継続収益ビジネス 〜開発力を資産に変える〜 – AWS Local Executive Roadshow 大阪編(#2/8)開催レポート
こんにちは。Amazon Web Services Japan のソリューションアーキテクト、田中 里絵 です […]
実践企業に学ぶ生成 AI 導入の勘所 〜眠るデータを企業価値に変える〜 – AWS Local Executive Roadshow 大阪編(#1/8)開催レポート
こんにちは。Amazon Web Services Japan のソリューションアーキテクト、田中 里絵 です […]
株式会社アクト・ノード様の AWS 生成 AI 活用事例:Amazon Bedrock Agent Coreで実現する「見守りエージェントAI」。一次産業の人手不足と熟練知識の属人化を解決し、見守り頻度を最大48倍に拡大、生産者の工数を50%削減
本ブログは株式会社アクト・ノード様とAmazon Web Services Japan 合同会社が共同で執筆い […]
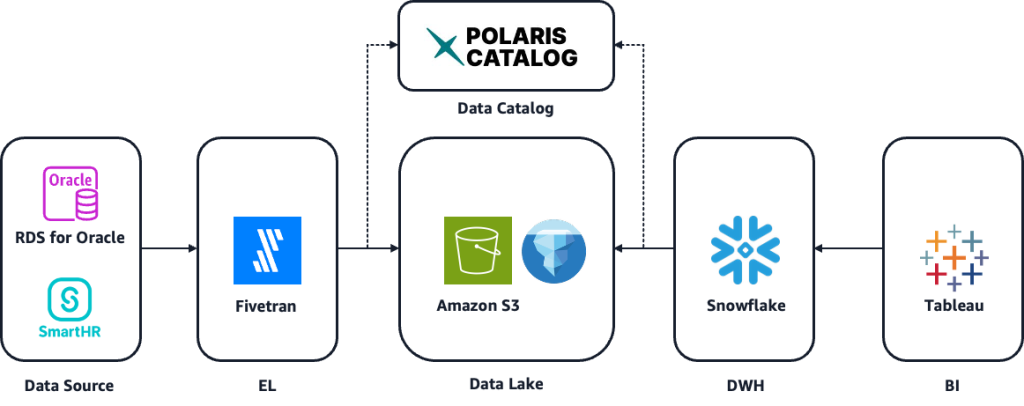
Fivetran の CDC 機能で実現するラーメン山岡家の Iceberg on AWS データパイプライン
ラーメンチェーン「山岡家」を展開する株式会社丸千代山岡家が、Fivetran の CDC(Change Data Capture)機能を活用して Amazon RDS for Oracle から Amazon S3 上の Apache Iceberg テーブルへのデータ同期を実現した事例をご紹介します。アーキテクチャの検討プロセスや Fivetran 採用の理由、約 5 分のデータ反映、月あたりの運用工数を 6 日から 0.5 日に削減、PoC から本番稼働まで約 1 ヶ月という短期導入といった導入効果を解説します。

Amazon DataZone によるデータガバナンスのスケール: Covestro の事例
本記事では、Covestro が中央集権型のデータレイクから Amazon DataZone と AWS Serverless Data Lake Framework (SDLF) を使ったデータメッシュアーキテクチャへ移行した事例を紹介します。標準化されたブループリントと自動化されたガバナンスにより、1,000 を超えるデータパイプラインを運用しながら市場投入までの時間を 70% 短縮し、部門横断のデータ共有と品質管理を実現した経緯を解説します。

データサイロの解消: Volkswagen の Amazon DataZone を活用したアプローチ
本記事では、Volkswagen が Amazon DataZone を使ってデータサイロを解消し、データメッシュアーキテクチャを実装した事例を紹介します。AWS CDK を使った自動登録ワークフローにより、Amazon Redshift データウェアハウスのデータ資産を中央のデータメッシュに自動公開する仕組みを構築し、データガバナンスを維持しつつデータ検出とアクセスを効率化する方法を解説します。

ボトルネックからブレークスルーへ:Dutchie のデータベース移行の軌跡
この投稿では、Dutchie が 2025 年の 4/20 週に向けて、ミッションクリティカルなワークロードを Amazon RDS for SQL Server に移行する際の課題をいかに成功裏に乗り越えたのかを探ります。