Amazon Web Services ブログ
Category: Database

【開催報告 & 資料公開】IT 基盤の環境変化に対応する AWS マイグレーション
こんにちは。アマゾン ウェブ サービス ジャパン合同会社 パートナーソリューションアーキテクトの深井 宣之です […]

Amazon ElastiCache 向け Valkey 9.1 のお知らせ
本ブログでは、Amazon ElastiCache で利用可能になった Valkey 9.1 の新機能についてご紹介します。再設計された I/O スレッディングによるスループット向上や、小さな文字列・ソート済みセットのメモリ効率改善といった性能強化に加え、データベース単位の ACL によるマルチテナント環境での分離強化、HGETDEL・MSETEX・CLUSTERSCAN などワークフローを簡素化する新コマンド、JSON 形式のログ出力による可観測性向上について学べます。大規模インメモリワークロードのコスト最適化と運用効率化を目指す方におすすめの内容です。

Open Governance for MySQL: A Step Forward for the Community
このBlog postはOpen Governance for MySQL: A Step Forward f […]
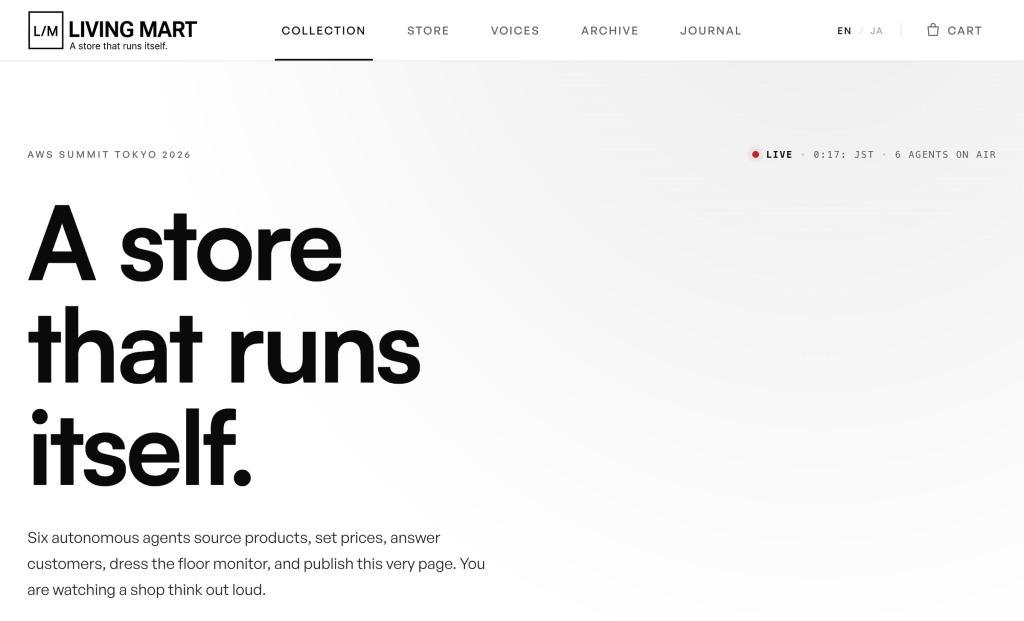
AI が経営するお店で買い物しませんか? — AWS Summit Japan 2026 Builders’ Fair で「Living Mart」体験
6 体の AI エージェントが、仕入れ・値付け・サイト運営・接客・広告までを人間の指示なしに動かすお店。AWS Summit Japan 2026(幕張メッセ/ブース A080)で、AI 運営の EC サイトでのお買い物と、当選者向け AI デザインのオリジナルステッカーを体験できます。

株式会社 MIXI、FC東京の写真選定業務効率化システムを Amazon Aurora DSQL で実現
株式会社 MIXI が FC東京向けに開発した「写真選定業務効率化システム」のバックエンドデータベースとして Amazon Aurora DSQL を採用した経緯と技術的な工夫、得られた効果を、お客様の声を交えてご紹介します。

BIM データを生成 AI で活用する: IFC を RDF グラフに変換し Amazon Neptune で問い合わせるアーキテクチャ
建設業界で導入が進む BIM には、建物の豊富なデータが蓄積されています。本ブログでは、このデータを生成 AI から自然言語で問い合わせる方法として、BIM のオープンな標準フォーマットである IFC を RDF グラフに変換して Amazon Neptune に格納し、AI エージェントが text-to-SPARQL で回答する仕組みを、実装レベルで解説します。

「フィジカル AI 開発支援プログラム by AWS ジャパン」Community Meetup #1 を開催しました
2026 年 6 月 1 日、アマゾン ウェブ サービス ジャパン合同会社(以下、AWS ジャパン)は、「フィジカル AI 開発支援プログラム by AWS ジャパン」の第 1 回コミュニティイベント「Community Meetup #1」を、 AWS ジャパン 麻布台オフィスにて開催しました。本プログラムは 2026 年 1 月 27 日に発表し、3 月 3 日にキックオフイベントを開催しました。今回の Community Meetup は、約 6 ヶ月間の開発支援期間のなかで、採択企業同士の交流を主な目的として開いた初めてのコミュニティイベントです。

Amazon RDS for Db2 12.1 の提供開始と Community Edition の追加
Amazon RDS for Db2 で IBM Db2 12.1 がサポートされました。AI Query Optimizer、名前空間の分離、セキュリティ強化などの新機能に加え、IBM ソフトウェアライセンス料なしで利用できる Community Edition (db2-ce) が新たに追加されました。

Similarweb の HBase から Amazon DynamoDB への移行
大規模なデータ量を運用するうえで、運用面での重要な課題に直面します。Similarweb では Apache […]
セガサミーホールディングスがオンプレミスの Oracle Database を Amazon RDS for Oracle に移行し、性能と運用効率を大幅改善
セガサミーホールディングス株式会社は、エンタテインメントコンテンツ事業、遊技機事業、ゲーミング事業の 3 つの […]