Amazon Web Services ブログ
Category: RDS for PostgreSQL

Amazon RDS ブルー/グリーン デプロイを使用した Amazon Aurora PostgreSQL アップグレードのロールバック戦略の実装
本記事は、2025 年 6 月 20 日に公開された Implement a rollback strateg […]

Amplitude が Amazon OpenSearch Service をベクトルデータベースとして活用し、自然言語による分析を実現した方法
Amplitude が Amazon OpenSearch Service をベクトルデータベースとして活用し、自然言語による分析機能 Ask Amplitude を構築した過程を紹介します。PostgreSQL での総当たりコサイン類似度から pgvector による ANN 検索を経て、OpenSearch Service でのハイブリッド検索へと進化させ、アーキテクチャの簡素化、レイテンシーの削減、マルチテナント環境でのスケーラビリティ向上を実現しました。

Amazon Aurora PostgreSQL および Amazon RDS for PostgreSQL のバージョン 13 からのアップグレード戦略
本記事は 2026 年 1 月 27 日 に公開された「Strategies for upgrading Am […]

AWS Database Migration Service で PostgreSQL のテーブルをグループ毎にタスク化
本投稿は、 Manojit Saha Sardar と Chirantan Pandya による記事 「Gro […]

大容量テーブルの継続的レプリケーションを、AWS DMS の列フィルターによる並列化でパフォーマンス向上
本投稿は、Vanshika Nigam による記事 「Improve AWS DMS continuous r […]

Amazon RDS for PostgreSQL および Amazon Aurora PostgreSQL データベース向け AI 搭載チューニングツール: PI Reporter
AWS では、Amazon Relational Database Service (Amazon RDS) […]
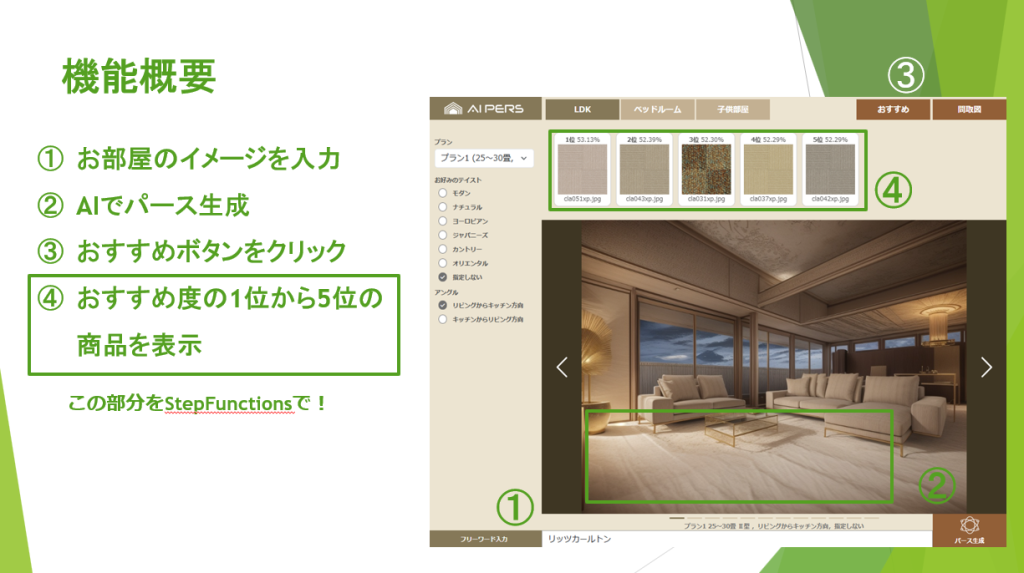
株式会社ファイン様のAWS 生成AI活用事例:建築AIパース生成サービスにレコメンドAI機能を実装。担当者の商品検索時間を75%削減し、顧客満足度も向上。
本ブログは株式会社ファイン様と Amazon Web Services Japan 合同会社が共同で執筆いたし […]

【寄稿】株式会社 GEOTRA 未来の人流シミュレーションへの取組
GEOTRAは、独自の人流シミュレーションサービスの基盤としてAWSを採用し、フルマネージド型サービスを中心としたアーキテクチャを構築しています。AWS Step Functions、Amazon ECR、Amazon RDSを効果的に活用することで、GPS位置情報から「非集計トリップデータ」を安全に生成・分析しています。
AWSの採用理由は、充実したコミュニティ、サーバーレスによる運用負荷軽減などのメリットを評価いただいた。GEOTRAは、橋梁・道路建設などの影響の高精度な人流シミュレーションサービスを展開しています。

PostgreSQL パフォーマンス向上 : ロックマネージャー競合の診断と対策
(この記事は、Improve PostgreSQL performance: Diagnose and mit […]

より豊かなコンテキストのための Model Context Protocol (MCP) による Amazon Q Developer CLI の拡張
本日、Amazon Q Developer はコマンドラインインターフェイス(CLI)での Model Context Protocol (MCP) サポートを発表しました。開発者は MCP サポートを使用して外部データソースを Amazon Q Developer CLI に接続し、よりコンテキストを意識した応答を得ることができます。MCP ツールとプロンプトを Amazon Q Developer CLI に統合することで、事前構築された幅広い統合リストや、stdio をサポートするあらゆる MCP サーバーにアクセスできるようになります。この追加コンテキストにより、Amazon Q Developer は、独自の統合用のコードを開発する必要なく、より正確なコードを記述し、データ構造を理解し、適切なユニットテストを生成し、データベースドキュメントを作成し、正確なクエリを実行できるようになります。MCP ツールとプロンプトで Amazon Q Developer を拡張することで、開発者は開発タスクをより迅速に実行でき、開発者体験を効率化できます。AWS では、Anthropic による Model Context Protocol (MCP) のようなエージェント向けの人気のあるオープンソースプロトコルをサポートすることに取り組んでいます。今後数週間のうちに、Amazon Q Developer IDE プラグイン内でこの機能を拡張していく予定です。