Amazon Web Services ブログ
IBM Db2 LUW から Amazon Aurora PostgreSQL または Amazon RDS for PostgreSQL に移行した後にデータベース オブジェクトを検証する
異種データベースの移行は多段階のプロセスであり、通常、評価、データベーススキーマの変換、データ移行、機能テスト、パフォーマンスチューニングなど、複数のチームにわたる多くのステップが含まれます。 IBM Db2 LUW から Amazon Aurora PostgreSQL 互換エディション または Amazon Relational Database Service (Amazon RDS) for PostgreSQL への移行は、本質的に異種DBの移行であり、従前から用いられているこういった手順が必要です。
AWS では、異種データベース移行のスキーマ変換を簡素化する AWS Schema Conversion Tool (AWS SCT)や、ダウンタイムを最小限に抑えながらデータを迅速かつ安全に AWS に移行できる AWS Database Migration Service (AWS DMS) などのツールとサービスを提供しています。
AWS SCT は、PostgreSQL に自動的に変換される Db2 コードの割合、変換に手作業が必要なコードの割合と詳細なアクション項目を示す評価レポートを生成します。 AWS SCT によるスキーマの移行は完全に自動化されたプロセスではないため、ターゲットデータベースのオブジェクトや主要なオブジェクト機能が不足している可能性は常にあります。 スキーマの検証は移行プロセスにおいて、スキーマ変換プロセスでの問題を、それ以降の段階に持ち越さないようにするための重要なマイルストーンです。
この記事では、Db2 LUW から Amazon RDS for PostgreSQL または Aurora PostgreSQL に移行されたデータベーススキーマオブジェクトを検証する方法について説明します。
いつ、どのオブジェクトを検証すべきか
スキーマを Db2 LUW から正常に変換し、AWS SCT またはその他の変換ツールを使用して PostgreSQL に変換されたスキーマをデプロイ後、スキーマ検証を実行する必要があります。
次のリストは、データベース移行時に検証する必要がある Db2 LUW (ソース) と Aurora PostgreSQL (ターゲット) のデータベースオブジェクトを示しています。
- スキーマ
- テーブル
- ビュー
- 主キー
- 外部キー
- インデックス
- マテリアライズドクエリテーブル
- ユーザー定義データ型
- トリガー
- シーケンス
- プロシージャ
- 関数
以下のセクションでは、各オブジェクトタイプのオブジェクト数がソースデータベースとターゲットデータベースで一定であることを確認するために、各オブジェクトタイプの検証シナリオを詳細に説明します。 これらの検証シナリオでは、変換の精度は対象外です。
スキーマ
スキーマは、アプリケーションまたはマイクロサービスに関連した機能を提供するデータベースオブジェクトの集まりです。 SQL クエリを使用して、ソースデータベースとターゲットデータベースのスキーマを検証できます。
| DB2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
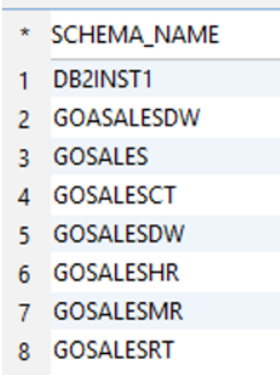 |
PostgreSQL example output:
 |
Db2 LUW スキーマを変換すると、AWS SCT はターゲットデータベースに追加のスキーマ (aws_db2_ext と aws_db2_ext_data) を追加します。 これらのスキーマは、変換されたスキーマを Aurora PostgreSQL データベースに書き込む際に必要な Db2 LUW データベースの SQL システム関数を実装します。 これらの追加スキーマは AWS SCT 拡張パックと呼ばれます。
Db2 LUW と PostgreSQL (‘pg_catalog‘、’information_schema‘、’public‘) のシステムテーブルまたはカタログテーブル (‘SYS%‘、’SQLJ‘、’NULLID‘) に関連するスキーマは除外されます。 また、Aurora PostgreSQL の特定の機能に関連するスキーマ (aws_commons、aws_lambda) も除外しています。
ソースデータベースとターゲットデータベースのスキーマの数が一致していることを確認する必要があります。 相違点が見つかった場合は、AWS SCT のログを調べて障害の原因を特定するか、手動で作成する必要があります。
テーブル
AWS SCT はソース Db2 LUW テーブルを同等のターゲット (PostgreSQL) テーブルに変換します。 必要に応じて、カスタムマッピングルールを使用して特定のテーブルを移行対象に含めたり除外したりできます。 以下のスクリプトは、すべてのテーブルの数と詳細レベルの情報を返します。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
IBM Db2 ではテーブルパーティションを個別のテーブルとしてリストしていないため、PostgreSQL のパーティションテーブルを除外するために C.RELISPARTITION = 'f' という条件を追加しました。 PostgreSQL には、プライマリキー、外部キー、インデックスのオブジェクト数に影響する可能性のあるパーティションテーブルに関するいくつかの制限があることに注意してください。
詳細レベルの情報については、以下のクエリを使用してください。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |

ソースデータベースとターゲットデータベースの結果を検証します。 違いが見られる場合は、AWS SCT または手動ログから理由を特定し、問題を解決した後に失敗したステートメントを再実行してください。
ビュー
AWS SCT によって変換されたビュー数は、ソースデータベースとターゲットデータベースで次のクエリを実行して検証できます。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
詳細レベルの情報については、以下のクエリを使用してください。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
この SQL を使用して、ソースとターゲットの間の数と詳細を確認する必要があります。 相違点が見つかった場合は、原因を特定して相違点を修正してください。
主キー
データベースオブジェクトの検証に加えて、データに一貫性があり、整合性が保たれていることを確認する必要があります。 制約の種類が異なると、挿入時にデータを柔軟に制御して確認できるため、実行時のデータ整合性の問題を回避できます。
主キーを使用すると、列に一意の値を設定できるため、正規化処理後に情報が重複するのを防ぐことができます。 このキーは、キー値に基づく検索を改善し、テーブルスキャンを回避するのに役立ちます。
次のクエリは、ソースデータベースとターゲットデータベースの主キーの数と詳細を抽出するのに役立ちます。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
詳細レベルの情報については、以下のクエリを使用してください。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
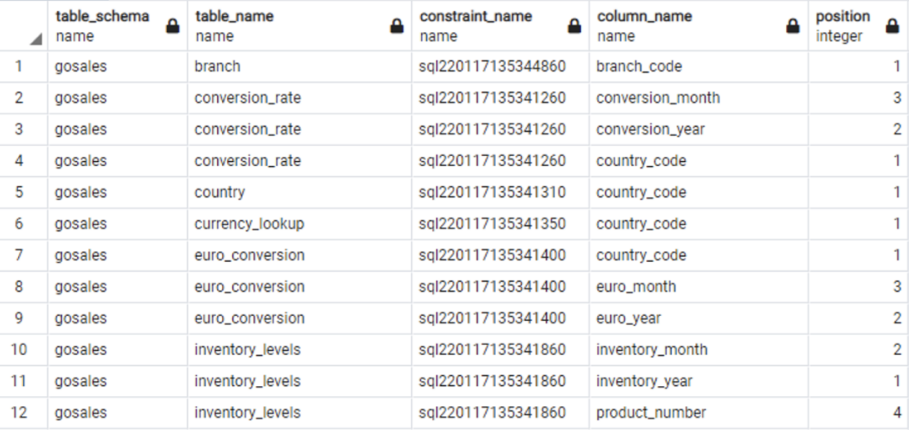 |
この SQL を使用して、ソースとターゲットの間のプライマリキーの数と詳細を確認する必要があります。 相違点が見つかった場合は、デプロイログから原因を特定し、違いを修正してください。
外部キー
外部キーはテーブル間の参照整合性を維持するのに役立ちます。 AWS DMS のフルロードを使用してデータ移行を実行する前に、ターゲット側でこれらのキーをオフにする必要があります。 詳細については、「PostgreSQL データベースの AWS Database Migration Service のターゲットとしての使用」を参照してください。
次のクエリでは、ソースデータベースとターゲットデータベースの両方にある外部キーの数と詳細レベルの情報を取得できます。 外部キーは、AWS DMS を使用してフルロードによるデータ移行を完了した後に検証します。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
詳細レベルの情報については、以下のクエリを使用してください。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
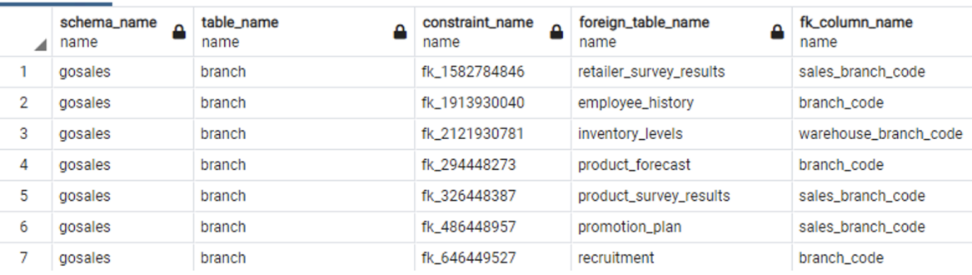 |
PostgreSQL バージョン 11 にはパーティションテーブルの外部キーに関する制限がありますが、その制限の多くはバージョン 12 以降では解消されています。 ソースデータベースとターゲットデータベース間の外部キーの数と詳細を検証する際は、これらの制限に留意する必要があります。
インデックス
インデックスは、テーブルの 1 つ以上の列に基づいて作成されるデータベースオブジェクトです。 インデックスはクエリのパフォーマンスを改善し、ユニークインデックスとして定義した場合にはデータの一意性を保証します。
ユニークインデックス
ユニークキーを使用すると、カラム内のデータの一意性を維持できます。 次のクエリを使用すると、ソースデータベースとターゲットデータベースの両方にあるユニークキーの数と詳細レベルの情報を取得できます。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
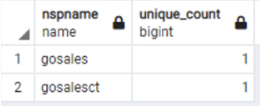 |
詳細レベルの情報については、以下のクエリを使用してください。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
非ユニークインデックス
インデックスはクエリのパフォーマンスを向上させる上で重要な役割を果たします。 チューニング方法はデータベースごとに異なるため、Db2 LUW データベースと PostgreSQL データベースではユースケースによってインデックスの数や種類が異なるため、インデックスの数も異なる場合があります。 PostgreSQL のパーティションテーブルの制限により、インデックス数も異なる場合があります。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
詳細レベルの情報については、以下のクエリを使用してください。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
ソースデータベースとターゲットデータベース間のインデックスの数と詳細を確認する必要があります。違いがある場合は、既知の理由によるものか、デプロイメントログに基づいて調査して修正する必要があります。
マテリアライズド・クエリー・テーブル
Db2 LUW のマテリアライズドクエリテーブルは PostgreSQL のマテリアライズドビューとして移行されます。 マテリアライズドクエリテーブルが結果をテーブルのような形で保持することを除けば、通常のビューと似ています。 これにより、データがすぐに返されるので、クエリのパフォーマンスが向上します。 次のクエリを使用して、ソースとターゲットのオブジェクトを比較できます。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
詳細レベルの情報については、以下のクエリを使用してください。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
ソースデータベースとターゲットデータベース間のマテリアライズドクエリテーブルとマテリアライズドビューの数と詳細を確認し、違いがあればデプロイログに基づいて調査して修正する必要があります。
ユーザー定義データ型
AWS SCT はカスタムデータタイプを Db2 LUW から PostgreSQL にタイプとして移行します。次のクエリを使用して、ソースとターゲットのオブジェクトを比較できます。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
ソースデータベースとターゲットデータベース間のユーザー定義型の数と詳細を確認し、違いがあればデプロイログに基づいて調査して修正する必要があります。
トリガー
トリガーは、データベースの監査、ビジネスルールの実装、参照整合性の実装に役立ちます。 また、適切な領域での使用状況によっては、パフォーマンスに影響を与えることもあります。 以下のクエリでは、ソースデータベースとターゲットデータベースの両方のトリガーの数と詳細がわかります。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
詳細レベルの情報については、以下のクエリを使用してください。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
Db2 LUW と PostgreSQL の間のトリガー数は、PostgreSQL でのトリガーの実装方法によって異なる場合があります。 ソースデータベースとターゲットデータベース間のトリガーの数と詳細を確認する必要があります。相違点がある場合は、既知の理由によるものか、デプロイメントログに基づいて調査して修正する必要があります。
シーケンス
シーケンスは、指定した範囲と順序に基づいて列の整数値を作成したり増やすのに役立ちます。 ID 列とは異なり、シーケンスは特定のテーブルに関連付けられません。 アプリケーションはシーケンスオブジェクトを参照して次の値を取得します。 シーケンスとテーブルの関係はアプリケーションによって制御されます。 ユーザーアプリケーションはシーケンスオブジェクトを参照し、複数の行やテーブルにわたって値を調整できます。
以下のクエリは、ソースデータベースとターゲットデータベースにあるシーケンスの数と詳細レベルの情報を取得するのに役立ちます。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
詳細レベルの情報については、以下を使用してください。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
|
ソースとターゲットの間のシーケンスの数と詳細を確認する必要がありますが、移行後にシーケンスを正しい値に設定することも重要です。 シーケンスをソースデータベースからターゲットデータベースに移行した後は、シーケンスの minvalue から始まるため、挿入文や更新文の実行中に重複キーエラーが発生する可能性があります。
プロシージャ
Db2 LUW ストアドプロシージャは、ビジネスロジックをカプセル化し、関連する DDL または DML 操作を単一の作業単位で実行します。 PostgreSQL では、プロシージャの制限により、ストアドプロシージャよりも関数を使用します。この数は、ソースデータベース内の既存の関数数に加算されます。 ソースデータベースとターゲットデータベースの両方で、次のクエリはプロシージャの数と詳細レベルの情報を提供します。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
詳細レベルの情報については、以下のクエリを使用してください。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
 |
関数
Db2 LUW では、関数は入力パラメータに特定のビジネスロジックまたは機能ロジックを実装し、特定の種類の定義済み出力を返します。 PostgreSQL では、ビジネスロジックとファンクショナルロジックの実装に関数が好まれるため、その数は通常 Db2 LUW よりも多くなります(訳注: PostgreSQL では、関数を使ってロジック実装されることが Db2 と比較すると多いためで、 SCT の変換機能により関数の数が増えるわけではありません)。ソースデータベースとターゲットデータベースの両方で、以下のクエリは関数の数と詳細レベルの情報を提供します。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
 |
PostgreSQL example output:
|
詳細レベルの情報については、以下のクエリを使用してください。
| Db2 LUW Query | PostgreSQL Query |
Db2 LUW example output:
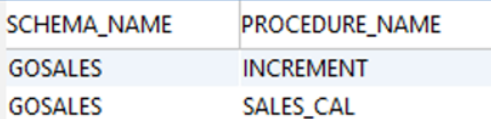 |
PostgreSQL example output:
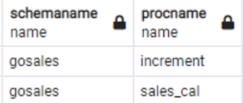 |
有用な PostgreSQL カタログテーブル
次の表は、いくつかの有用な Db2 LUW と、それに対応する PostgreSQL システムおよびカタログのテーブルとビューをまとめたものです。 これらのテーブルとビューには、データベース内に存在するさまざまなオブジェクトに関するメタデータが含まれており、データベースオブジェクトの検証に使用されます。
| Db2 LUW | PostgreSQL | Use Case |
| syscat.tables/ syscat.columns |
pg_tables /information_schema.tables |
さまざまなテーブルのプロパティ |
| syscat.tables/ syscat.columns | Pg_views/information_schema.views | ビューのさまざまなプロパティ |
| syscat.tables/ syscat.tabconst/ syscat.references/ syscat.keycoluse | pg_indexes/pg_index | インデックスに関する詳細情報 |
| syscat.routines | pg_proc | プロシージャ、関数、トリガー関数に関する詳細情報 |
| syscat.triggers | information_schema.triggers | トリガーに関する詳細情報 |
| Syscat.sequences | pg_sequence/information_schema.sequences | シーケンス、ID、serialカラムに関する詳細情報 |
| Syscat.tables | pg_matviews | マテリアライズドビューの詳細 |
| syscat.datatypes | pg_type | カスタムデータ型に関する詳細情報 |
PostgreSQL ではサポートされていないオブジェクトの扱い
PostgreSQL でサポートされていない Db2 LUW オブジェクトの移行は手動で実行する必要があります。 この記事で提供するクエリを使用すると、移行したオブジェクトを繰り返し検証してギャップを特定し、それに応じて修正できます。
まとめ
この投稿では、Db2 LUW と Aurora PostgreSQL、または PostgreSQL データベース用の RDS のメタデータクエリによるデータベースオブジェクトの検証について説明しました。 データベースオブジェクトの検証は、移行の正確性を詳細に把握し、すべてのデータベースオブジェクトが適切に移行されたかどうかを確認するための重要なステップです。 また、データベース検証フェーズでは、ターゲットデータベースの整合性を確認し、依存するアプリケーションプロセスの事業継続性を確保します。
オブジェクトが自動変換されるか手動で変換されるかに関係なく、機能テストだけでなくユニットテストも数回繰り返す必要があります。 これにより、アプリケーションとの統合テストを行う際の多くのやり直しが省けます。
コメントや質問がある場合はお知らせください。 私たちは皆さんのフィードバックを大切にしています!
翻訳はソリューションアーキテクトの山根 英彦が担当しました。原文はこちらです。
著者について
 Sai Parthasaradhi は AWS プロフェッショナルサービスのデータベース移行スペシャリストです。 彼はお客様と緊密に連携して、お客様が AWS でデータベースを移行し、最新化できるよう支援しています。
Sai Parthasaradhi は AWS プロフェッショナルサービスのデータベース移行スペシャリストです。 彼はお客様と緊密に連携して、お客様が AWS でデータベースを移行し、最新化できるよう支援しています。
 Rakesh Raghav は、インドの AWS プロフェッショナルサービスの主任データベースコンサルタントで、お客様がクラウドの導入と移行を成功させるお手伝いをしています。 彼は、お客様のデータベースのクラウドへの移行を加速させる革新的なソリューションの構築に情熱を注いでいます。
Rakesh Raghav は、インドの AWS プロフェッショナルサービスの主任データベースコンサルタントで、お客様がクラウドの導入と移行を成功させるお手伝いをしています。 彼は、お客様のデータベースのクラウドへの移行を加速させる革新的なソリューションの構築に情熱を注いでいます。
 Veeranjaneyulu Grandhi は、AWSのデータベースコンサルタントです。 彼はお客様と協力して、スケーラブルで可用性が高く、安全なソリューションを AWS クラウドで構築しています。 彼の重点分野は、同種データベース移行と異種データベース移行です。
Veeranjaneyulu Grandhi は、AWSのデータベースコンサルタントです。 彼はお客様と協力して、スケーラブルで可用性が高く、安全なソリューションを AWS クラウドで構築しています。 彼の重点分野は、同種データベース移行と異種データベース移行です。