Amazon Web Services ブログ
Category: PostgreSQL compatible

Amazon RDS ブルー/グリーン デプロイを使用した Amazon Aurora PostgreSQL アップグレードのロールバック戦略の実装
本記事は、2025 年 6 月 20 日に公開された Implement a rollback strateg […]

AWS Weekly Roundup: AWS AI/ML Scholars プログラム、Agent Plugin for AWS Serverless など (2026 年 3 月 30 日)
2026 年 3 月 23 日週の出来事で私が最も心を躍らせたのは、AWS Agentic AI バイスプレジ […]

Amazon Aurora PostgreSQL の共有プランキャッシュの使用
Aurora PostgreSQL の共有プランキャッシュ機能により、高並行性環境で汎用 SQL プランのメモリ消費を大幅に削減できます。プラン重複を解消することで、40GB のメモリ負荷を 400MB まで削減し、より小さなインスタンスでより多くの接続を実行できます。

Amazon Aurora PostgreSQL および Amazon RDS for PostgreSQL のバージョン 13 からのアップグレード戦略
本記事は 2026 年 1 月 27 日 に公開された「Strategies for upgrading Am […]
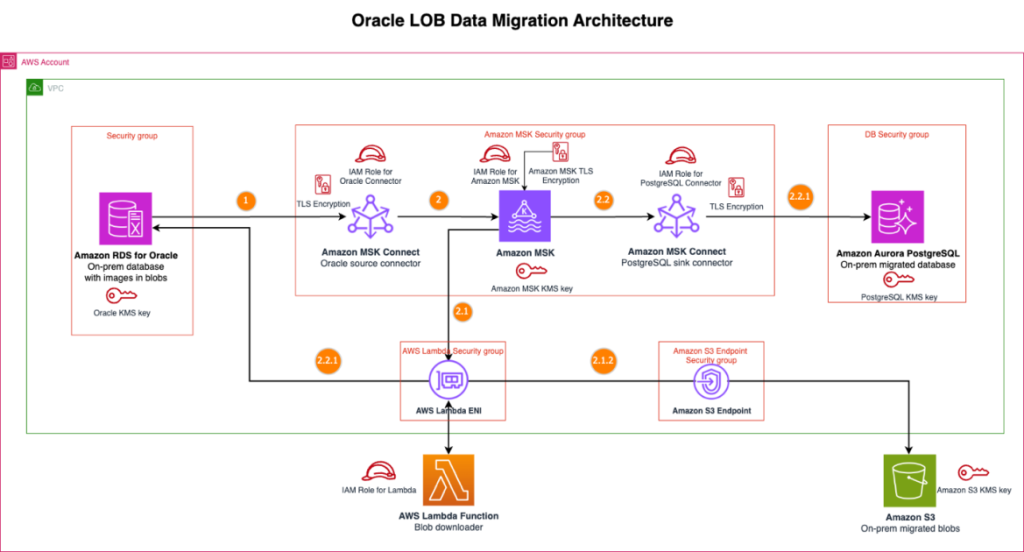
Oracle から Amazon Aurora PostgreSQL および Amazon S3 への大容量バイナリオブジェクト移行を効率化する Kafka ベースのソリューション
Amazon MSK、Amazon Aurora PostgreSQL-Compatible Edition、Amazon MSK Connect を使用して、Oracle データベースから AWS への大容量バイナリオブジェクト (LOB) 移行を効率化するストリーミングソリューションを紹介します。
AWS Transform がフルスタック Windows モダナイゼーション機能を発表
2025 年の 5 月、.NET アプリケーションを大規模にモダナイズするための初のエージェント型 AI サー […]

AWS Database Migration Service で PostgreSQL のテーブルをグループ毎にタスク化
本投稿は、 Manojit Saha Sardar と Chirantan Pandya による記事 「Gro […]

大容量テーブルの継続的レプリケーションを、AWS DMS の列フィルターによる並列化でパフォーマンス向上
本投稿は、Vanshika Nigam による記事 「Improve AWS DMS continuous r […]

Amazon RDS for PostgreSQL および Amazon Aurora PostgreSQL データベース向け AI 搭載チューニングツール: PI Reporter
AWS では、Amazon Relational Database Service (Amazon RDS) […]

ニフティ株式会社、Oracle Database Enterprise Edition からAmazon Aurora PostgreSQLへの移行によりメンテナンス時の対応コストを50%削減
ニフティ株式会社は、基幹ポイントサービス「ニフティポイントクラブ」をOracle DatabaseからAurora PostgreSQLへ移行しました。本ブログでは、をOracle Database Enterprise EditionからAurora PostgreSQLへ移行した際のエピソードについてご紹介します。