Amazon Web Services ブログ
Amazon Aurora Limitless Database のプレビューが公開
Amazon Aurora Limitless Database のプレビューを開始しました。Aurora Limitless Database は自動水平スケーリングをサポートする新機能であり、1 秒間に数百万件の書き込みトランザクションを処理し、1 つの Aurora データベースでペタバイト規模のデータを管理できるようにします。
Amazon Aurora リードレプリカを使用すると、1 つのデータベースインスタンスが提供できる上限を超えて、Aurora クラスターの読み込みキャパシティを増やせます。今回、Aurora Limitless Database によって、データベースの書き込みスループットとストレージ容量を単一の Aurora ライターインスタンスの上限を超えてスケールできるようになりました。Limitless Database に使用されるコンピューティング能力とストレージ容量は、クラスター内のライターインスタンスとリーダーインスタンスの容量とは独立して追加されます。
Limitless Database を使用することで、大規模なアプリケーションの構築に集中できます。ワークロードをサポートするために、複数のデータベースインスタンスにわたってデータをスケールする複雑なソリューションを構築、保守する必要はありません。Aurora Limitless Database はワークロードに基づいてスケーリングを行い、これまで複数の Aurora ライターインスタンスが必要だった書き込みスループットとストレージ容量を実現します。
Amazon Aurora Limitless Database のアーキテクチャ
Limitless Database には、複数のデータベースノード (トランザクションルーターまたはシャード) で構成される 2 層アーキテクチャが使用されています。

シャードは Aurora PostgreSQL DB インスタンスであり、それぞれがデータベースのデータのサブセットを保存します。これによって並列処理が可能になり、書き込みスループットが向上します。トランザクションルーターは、データベースの分散性を管理し、単一のデータベースイメージをデータベースクライアントに提供します。
トランザクションルーターは、データの保存場所に関するメタデータの管理、受信した SQL コマンドの解析とシャードへの送信、シャードからのデータの集約と単一の結果のクライアントへの返信、分散トランザクションの管理による分散データベース全体の整合性の維持を行います。Limitless Database アーキテクチャを構成するすべてのノードは、DB シャードグループに含まれています。DB シャードグループには、Limitless Database リソースにアクセスするための独立したエンドポイントがあります。
Aurora Limitless Database の利用開始
Aurora Limitless Database のプレビューを利用するには、サインアップをしてください。間もなく招待されます。プレビューは、米国東部 (オハイオ)、米国東部 (バージニア北部)、米国西部 (オレゴン)、アジアパシフィック (東京)、欧州 (アイルランド) の各 AWS リージョンにて、新しい Aurora PostgreSQL クラスターのバージョン 15 で利用可能です。
Aurora クラスターの作成ワークフローの一環として、Amazon RDS コンソールまたは Amazon RDS API で Limitless Database と互換性のあるバージョンを選択します。次に、DB シャードグループを追加して、新しい Limitless Database テーブルを作成できます。また、Aurora キャパシティユニット (ACU) の最大値を選択できます。
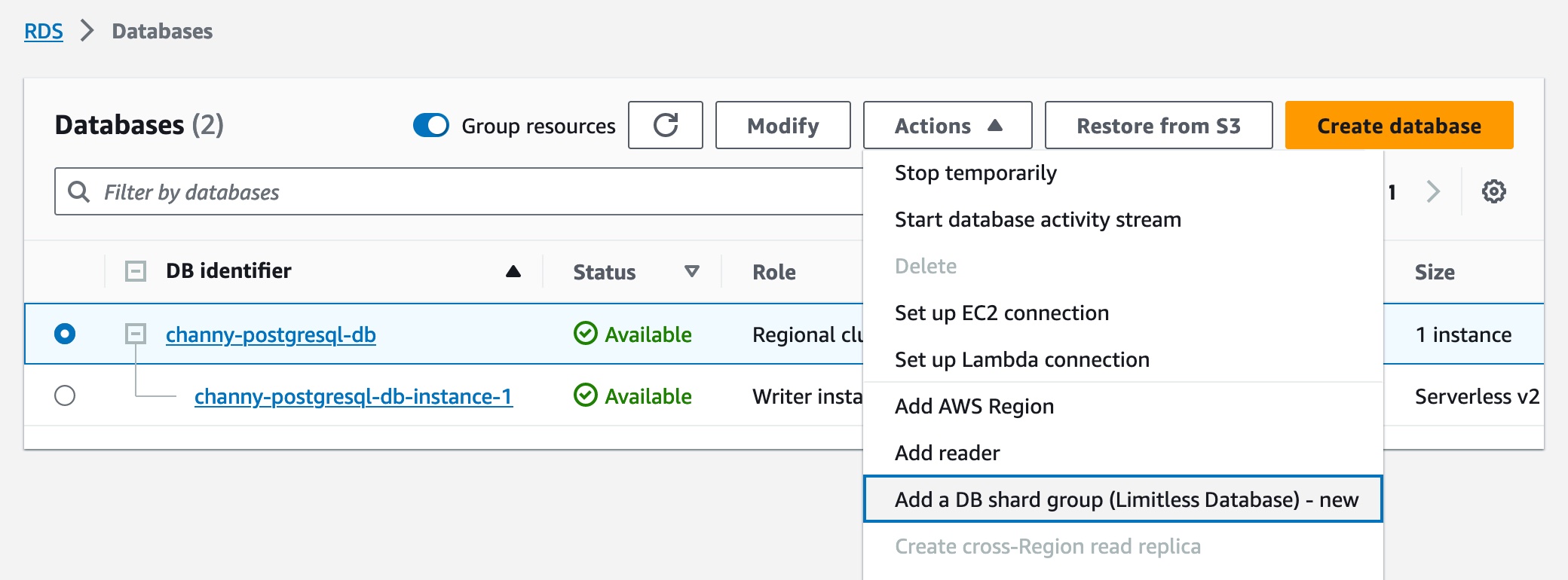
DB シャードグループを作成したら、エンドポイントを含む詳細を[データベース]ページで確認できます。
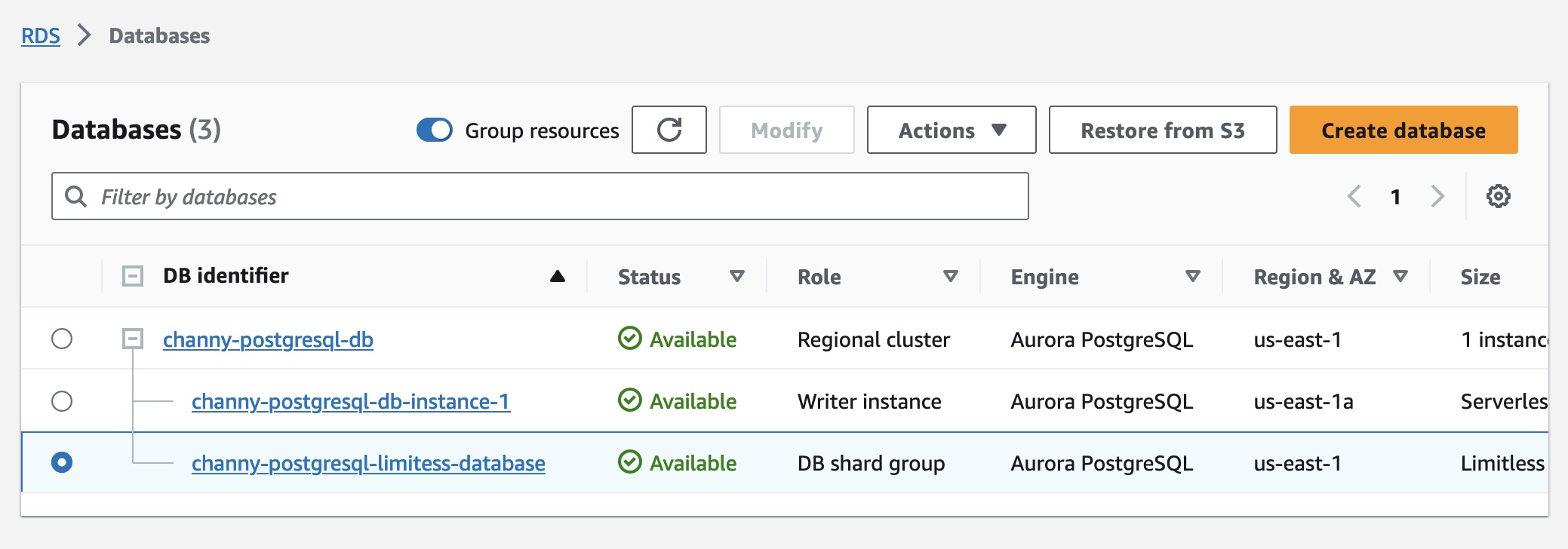
Aurora Limitless Database を使用するには、psql または PostgreSQL で動作するその他の接続ユーティリティを使用して、DB シャードグループのエンドポイント (Limitless エンドポイント) に接続する必要があります。
Aurora Limitless Database には、データを格納するテーブルが 2 種類あります。
- シャードテーブル – このテーブルは複数のシャードに分散されています。データは、シャードキーと呼ばれるテーブル内の指定された列の値に基づいてシャード間で分割されます。
- 参照テーブル – このテーブルでは、すべてのデータがすべてのシャードに存在するため、不要なデータ移動がなくなり、結合クエリをより高速に実行できます。製品カタログや郵便番号など、あまり変更されない参照データによく使用されます。
シャードテーブルまたは参照テーブルを作成したら、大量のデータを Aurora Limitless Database にロードし、標準の PostgreSQL クエリを使用してそれらのテーブル内のデータを操作できます。
プレビューが公開中
Amazon Aurora Limitless Database のプレビューで、そのパワーをいち早く体験できます。
ぜひサインアップしてお試しいただき、AWS re:Post for Amazon Aurora または通常の AWS サポート窓口をとおしてフィードバックをお寄せください。
– Channy
原文はこちらです。