Amazon Web Services ブログ
Category: News

週刊AWS – 2026/6/8週
Amazon OpenSearch Serverless が Agentic Search に対応、Amazon Redshift がマニュアルスナップショットのコストを削減、Claude Fable 5 が一般提供開始、AWS FinOps Agent がプレビュー提供開始、OpenAI GPT-5.4 / GPT-5.5 が Amazon Bedrock で利用可能に、Amazon EC2 M9g / M9gd インスタンスが一般提供開始等

AWS クレジット詳細ページのご紹介
この記事では、パブリック API および Amazon Q との統合を備えた AWS Billing and […]

経済産業省 GENIAC 基盤モデル開発支援事業 (第4期) における採択事業者への支援を開始
2026年6月4日、経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構 (NEDO) が実施する […]

現在利用可能: AWS Graviton5 プロセッサを搭載した Amazon EC2 M9g および M9gd インスタンス
AWS Graviton プロセッサは世代を重ねるごとに着実に進化を遂げ、イテレーションを経るごとに、コンピュ […]

AWS FinOps Agent のパブリックプレビュー提供開始のお知らせ
本日 AWS は、AWS FinOps Agent のパブリックプレビューを発表します。これは、コスト異常を調 […]

Anthropic Claude Fable 5 on AWS: 保護手段が組み込まれた Mythos クラスの機能が利用可能に
2026年6月12日更新 – Amazon Bedrock版「Claude Fable 5」および […]

AWS Weekly Roundup: BYOM for Amazon RDS for SQL Server、AWS IoT Device SDK for Swift など (2026 年 6 月 8 日)
2026 年 6 月 8 日週、AWS IoT Device SDK for Swift が一般公開されました […]

週刊AWS – 2026/6/1週
Amazon Bedrock で OpenAI の GPT-5.5、GPT-5.4、Codex が一般提供開始, Amazon Bedrock AgentCore Identity で AWS Secrets Manager の既存シークレットを利用可能に, Amazon Quick が MCP 接続で VPC connectivity をサポート, Amazon RDS for SQL Server が Bring Your Own Media をサポート, Amazon ElastiCache for Valkey の durability サポートを発表, AWS Config が internal service linked rules をサポート開始, AWS Config が 9 つの新しいリソースタイプに対応, AWS Step Functions が AgentCore を活用したエージェント推論ステップに対応, Amazon Bedrock が OpenAI および Anthropic 互換 API に最適化された再設計コンソールを発表, Amazon Cognito がマルチリージョンレプリケーションに対応, Amazon SageMaker Data Agent がビジネスコンテキストを会話に統合, AWS MCP Server が cross-account および cross-role アクセスに対応, Amazon Bedrock AgentCore Runtime に対話型シェル (インタラクティブターミナル) 機能を導入
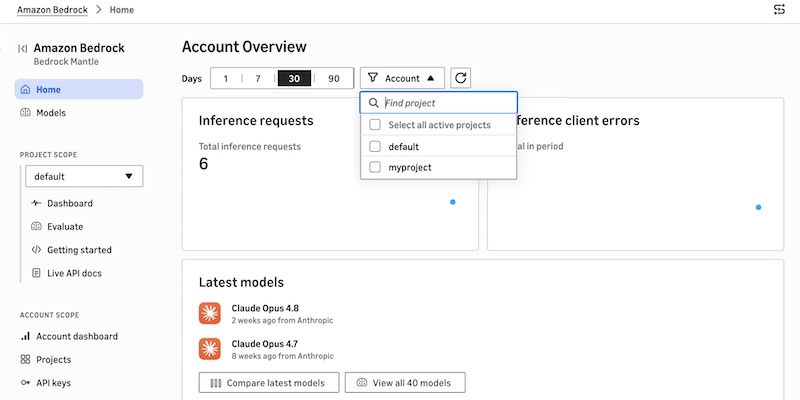
Anthropic および OpenAI 互換 API 向けに最適化された、Amazon Bedrock における新しいコンソールエクスペリエンスをお試しください
2026 年 6 月 5 日、Amazon Bedrock における新しいコンソールエクスペリエンスをお知らせ […]
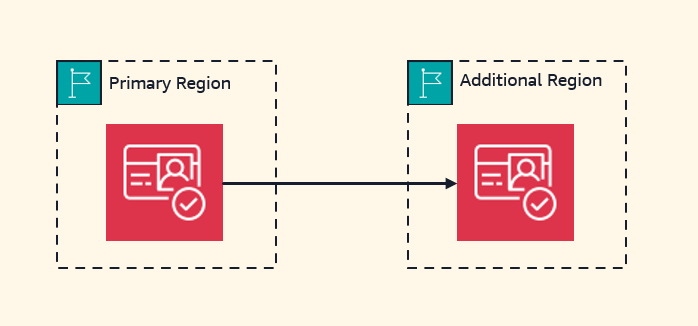
Amazon Cognito マルチリージョンレプリケーションを利用して、アプリケーションの回復力の向上を実現
ウェブアプリケーションおよびモバイルアプリのデベロッパーと連携するデベロッパーアドボケートとして、私は、リージ […]