Amazon Web Services ブログ
Category: AWS Lambda

AIで変える鉄道保全と、「クローズド」を読み解くクラウド設計 — AWS Summit Japan 2026 展示ブース開催報告
2026年6月25日〜26日、幕張メッセで開催された AWS Summit Japan 2026 にて、AWS […]

井村屋グループ様:Amazon SageMaker Canvas を活用したチルド製品の AI 需要予測で、業務工数 90% 削減と熟練者同等の予測精度を実現
本ブログは井村屋グループ株式会社様、株式会社 Hashup 様、Amazon Web Services Jap […]

AI を活用した Amazon Redshift のパフォーマンスレコメンデーション
Amazon Redshift のパフォーマンスチューニングを自動化する AI ソリューションの構築方法を解説します。AWS Lambda でテレメトリを収集し、シグナルベースのプロンプト設計で Amazon Bedrock から具体的な推奨事項を生成してメール通知します。
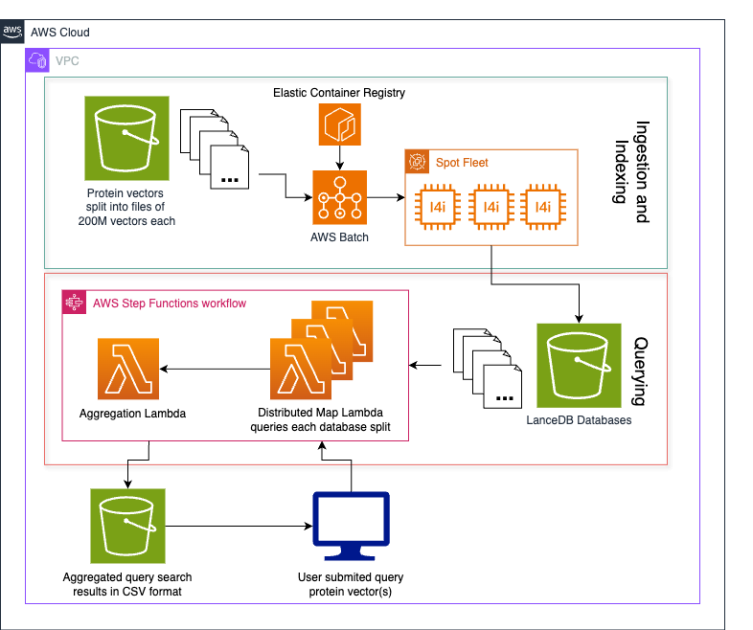
Metagenomi が LanceDB と Amazon S3 で実現した 10 億ベクトル超のスケーラブルな検索基盤
Metagenomi は LanceDB、Amazon S3、AWS Lambda を組み合わせ、35 億件のタンパク質エンベディングを低コストで保存・検索するサーバーレスソリューションを構築しました。データをバケット分割して並列インデックス化し、map-reduce 方式で検索する設計により、常時稼働サーバーなしで数十億ベクトル規模の近似最近傍検索を実現しています。

AWS Weekly Roundup: Amazon Connect Customer 向け Agentic CX Designer、EC2 AMI ウォーターマーク、MySQL 向けのオープンガバナンスなど (2026 年 6 月 29 日)
AWS Summit が各地で開催されており、多忙な日々を過ごしています。私は New York City S […]
完全なライフサイクル制御による分離されたサンドボックスの実行: AWS Lambda が MicroVM を導入
本記事は、2026 年 6 月 22 日に公開された Run isolated sandboxes with […]
AWS Deadline Cloud の Wait and Save サービスマネージドフリートを使ってみる
Deadline Cloud のサービス管理フリートで Wait and Save を設定し、CPU レンダリングコストを削減する方法を紹介します。

フルライフサイクル制御を備えた分離サンドボックスの実行:AWS Lambda が MicroVMs を導入
2026 年 6 月 22 日、私たちは AWS Lambda 内の新しいサーバーレスコンピュートプリミティブ […]
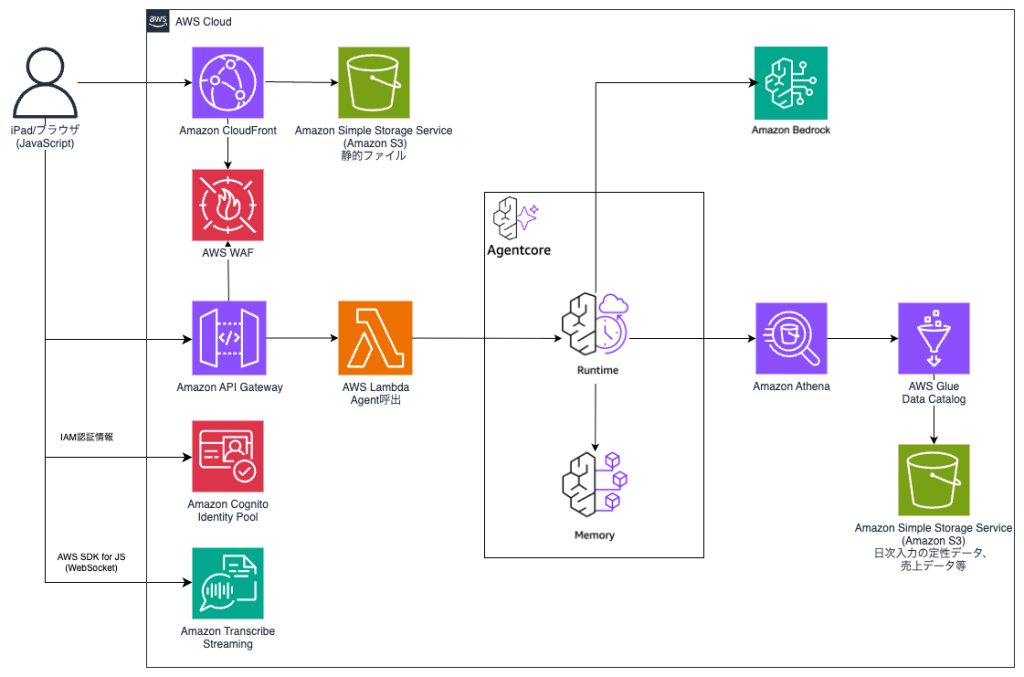
店舗の気づきを本部に届ける AI エージェント SMART のご紹介 — Amazon Bedrock AgentCore × Strands Agents によるユナイテッドアローズでの取り組み
本記事では、AWS サンプルアセットである AI エージェント SMART(Store Manager Agent for Retail Tech) についてのご紹介と、それを活用した株式会社ユナイテッドアローズ(以下、ユナイテッドアローズ)の取り組みについてご紹介します。小売業にとって、店舗の声をどう本部に届けるかは永遠のテーマです。売上数字の裏には、現場スタッフだけが感じている気づきが必ずあります。しかし店舗の日報や週報のフォーマットだけでは、その気づきを届けるのは難しいのが実情です。SMART は、店舗の気づきを AI の力で引き出し言語化して、本部に届けることを支援するために誕生しました。

VR × モーションキャプチャ × AI でパデルフォームを可視化する ── AWS Builders’ Fair 展示のご紹介
MetaQuestによるVR空間にて、HaritoraXでのモーショントラッキング技術とカメラによるMoveNetによる骨格推定を合わせて、パデルのフォーム分析。パデルトッププレイヤーとどのようにフォームが異なるのかを評価。AWS Summit 2026 Builders Fairのブースに出展。