Amazon Web Services ブログ
AWS 上の CI/CD パイプラインにおける Terraform State ファイル管理のベストプラクティス
はじめに
昨今、多くのお客様はインフラストラクチャのデプロイとメンテナンスに関する手動運用を減らしたいと考えています。
AWS でインフラストラクチャをデプロイしたり運用したりするためには、 AWS CloudFormation、AWS Cloud Development Kit (AWS CDK)、 Terraform のようなツールを利用した Infrastructure-As-Code (IaC) モデルを採用することが推奨されます。
Terraform を利用する上では、インフラストラクチャの設定やリソースを追跡するための State ファイルの管理がとても重要な要素となります。
AWS 上の CI/CD パイプラインで Terraform を実行する場合、State ファイルはパイプラインからアクセスできる共通の安全なパスに保存する必要があります。
チームの複数の開発者が同時にアクセスしようとすることを想定して、State ファイルをロックするメカニズムも必要です。
このブログ記事では、AWS で Terraform の State ファイルを管理する方法とその設定のベストプラクティス、および AWS CodeCommit や AWS CodeBuild などの AWS デベロッパーツールを利用した継続的インテグレーションパイプラインにおける効率的な管理の例について説明します。このブログ記事は、Terraform、AWS デベロッパーツール、AWS 上での CI/CD パイプラインに関する基本的な知識のある読者を想定しています。では始めましょう!
State ファイルの取り扱いにおける課題
デフォルトでは、State ファイルは Terraform を実行するローカル環境に保存されます。これは、デプロイメントの作業をする開発者が 1 人だけの場合は大きな問題とはならないでしょう。しかしそうでない場合は、次のような問題が発生する可能性があるため、State ファイルをローカルに保存することは推奨されません。
- チームで協力して作業する場合、複数の人が State ファイルにアクセスする必要がある
- State ファイル内のデータはプレーンテキストで保存されるが、そこには機密情報やセンシティブな情報が含まれる可能性がある
- ローカルファイルは紛失したり、破損または削除される可能性がある
State ファイルの取り扱いにおけるベストプラクティス
Terraform の組み込み機能としてサポートされているリモートバックエンド機能を利用して State ファイルをリモート管理することが推奨されます。
Amazon Simple Storage Service(Amazon S3) 上のリモートバックエンド: 耐久性とスケーラビリティに優れたストレージである Amazon S3 バケットに State ファイルを保存するように Terraform を設定できます。Amazon S3 に保存することで、State ファイルを他のユーザーと共有してコラボレーションすることも可能になります。
Amazon S3 上のリモートバックエンドと Amazon DynamoDB の利用: Amazon S3 バケットを利用してファイルを管理することに加え、Amazon DynamoDB テーブルを利用してState ファイルのロックを管理することもできます。特定の State ファイルを変更できる人を常に 1 人だけに限定してコンフリクトを回避し、State ファイルへの同時アクセスを安全に制御できます。
他にも Terraform Cloud 上のリモートバックエンドやサードパーティのバックエンドなどの選択肢があります。
AWS 上で Terraform State ファイルを管理するためにどんな方法が最適かは、固有の要件によって異なるといえるでしょう。
AWS 上で Terraform を利用してデプロイする際に、State を管理するために Amazon S3 と Amazon DynamoDB を使用する方法はお勧めの選択肢です。
State ファイルの管理のための AWS 設定
- Terraform を利用して Amazon S3 バケットを作成します。AWS Identity and Access Management (AWS IAM) ポリシー や Amazon S3 バケットポリシー を設定して Amazon S3 バケットのセキュリティ対策を実装します。アクセスを制限したり、データの保護やリカバリーのためにオブジェクトのバージョニングを設定したり、SSE-KMS を利用した AES256 暗号化を有効にしたりできます。
- 次に、Terraform を利用して、パーティションキーを LockID に設定した Amazon DynamoDB テーブルを作成します。読み取りキャパシティユニット/書き込みキャパシティユニットなどの追加の構成オプションも設定できます。テーブルが作成されたら、設定ファイルの中の terraform ブロックでテーブル名を指定して、State ロックでそのテーブル使用するように Terraform バックエンドを構成します。
- 単一の AWS アカウントの中に複数の環境やプロジェクトが存在している場合、単一の Amazon S3 バケットでそれらの State の管理ができます。
複数の AWS アカウントにまたがって環境やアプリケーションが存在するような場合は、アカウントごとに Amazon S3 バケットを作成して State の管理ができます。
この Amazon S3 バケット内で環境ごとに適切なフォルダを作成し、個別にプレフィックスを付加して State ファイルを格納できます。
AWS で Terraform の State ファイルを扱う方法がわかったので、次は AWS 上の 継続的インテグレーション パイプラインでこれらを設定する例を見ていきましょう。
アーキテクチャ
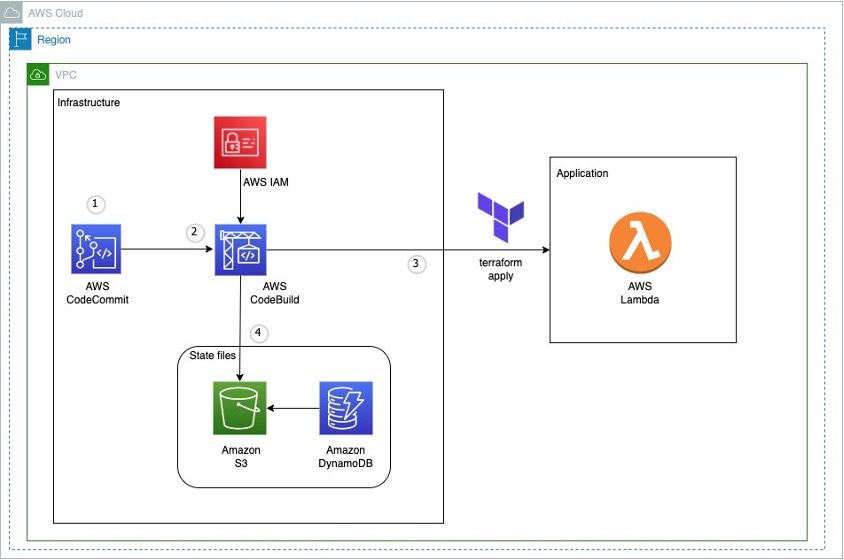
図1: AWS 上の CI パイプラインで Terraform を使用するサンプルアーキテクチャ
この図は、このブログで実装されるワークフローの概要を示しています。
- AWS CodeCommit リポジトリでコードを管理する (ここには Lambda などのアプリケーションのコードも含まれる)
- AWS CodeBuild ジョブは どの buildspec ファイルを使うかの設定を保持しており、AWS CodeCommit のソースコードを参照して動作する
terraform applyの実行によって作成された AWS Lambda 関数には、同じリポジトリで管理されたアプリケーションコードが実装される- Amazon S3 には
terraform applyの実行で作成された State ファイルが保存される
Amazon DynamoDB は Amazon S3 にある State ファイルのロックを管理する
実装
前提条件
始める前に、次の前提条件を満たしている必要があります。
- AWS Command Line Interface(AWS CLI) の最新バージョンが インストール されている
- Terraform の最新バージョンが インストール されている
- Git の最新バージョンが インストール されており git-remote-codecommit がセットアップ されている
- 使用するAWS アカウントの準備ができている (既存の AWS アカウント、もしくは 新規作成 )
- ローカルターミナルから AWS アカウントにアクセスできるように AWS IAM や AWS CLI の設定 がされている
環境の設定
- AWS CLI を設定するには、AWS アクセスキー ID とシークレットアクセスキーが必要です。AWS CLI の設定の詳細については、 こちらの説明 を参照してください。
- 次のコマンドで、サンプルコード全体を含むリポジトリをクローンしてください。
git clone https://github.com/aws-samples/manage-terraform-statefiles-in-aws-pipeline - クローンすると、次のようなフォルダ構成が確認できます。
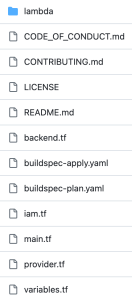
図2: AWS CodeCommit リポジトリ構成
Terraform のコードを 2 つのパートに分けてみましょう。1 つはインフラストラクチャの準備用、もう 1 つはアプリケーションの準備用です。
インフラストラクチャの準備
- main.tf ファイルは以下を行うコアコンポーネントです。
-
- State ファイルを保存するための Amazon S3 バケットを作成します。バケットの ACL、バージョニング、暗号化を設定することで、 State ファイルをセキュアに管理することができます。
- State ファイルをロックするために使用する Amazon DynamoDB テーブルを作成します。
- 2 つの AWS CodeBuild プロジェクトを作成します。1 つは
terraform planを実行するもので、もう1 つはterraform applyを実行するものです。
注記: 後で使用する AWS Lambda を作成するコードブロック(デフォルトではコメントアウトされている)も含まれています。
-
- AWS CodeBuild プロジェクトは、Amazon S3、Amazon DynamoDB、AWS CodeCommit、AWS Lambda にアクセスできる必要があります。 これらのリソースにアクセスするために必要な権限を持つ AWS IAM ロールを iam.tf ファイルで作成します。
- terraform コマンド
terraform planとterraform applyをそれぞれ実行する buildspec-plan.yaml とbuildspec-apply.yaml という 2 つの buildspec ファイルがあります。 - provider.tf ファイル内の AWS リージョンの設定を変更します。
(翻訳者補足: 作業中のAWS 環境に合わせて、必要であれば変更してください。) - variable.tf ファイルで、Amazon S3 バケット名、Amazon DynamoDB テーブル名、AWS CodeBuild コンピュートタイプ、AWS Lambda ロールとポリシー名を必要な値に更新します。このファイルを使って、さまざまな環境に合わせてパラメーターを簡単にカスタマイズすることができます。
これでインフラストラクチャの設定は完了です。
(翻訳者補足: この時点では、backend.tf には local バックエンド が設定されている必要があります。念のため、設定をご確認ください。)
ローカルターミナルを使用して以下のコマンドを順番に実行すると、上記のリソースを AWS アカウントにデプロイできます。
terraform apply が成功してAWS アカウントに上記のすべてのリソースが正常にデプロイできたら、アプリケーションのデプロイに進みましょう。
アプリケーションの準備
- クローンしたリポジトリで、backend.tf ファイルを使用して、 State ファイルを保存するための独自の Amazon S3 バックエンドを作成します。デフォルトでは以下の値が設定されます。必要に応じてこれらの値を更新します。
(翻訳者補足: ここでは「インフラストラクチャの準備」のセクションで作成した s3 バケットを指定してください。リージョンも同セクションにて provider.tf ファイルで変更している場合は同じ設定にしてください。)
- このリポジトリにある main.py ファイルには、呼び出されたときにシンプルなメッセージを返す Python コードのサンプルがあります。
- main.tf ファイルには、main.py ファイルのコードを使用して Lambda 関数を作成およびデプロイするための、以下のコードブロックがあります (これらのコードブロックのコメントを解除してください)。
- これで、AWS CodeBuild を利用してアプリケーションをデプロイできるようになりました。もう terraform コマンドをローカルで実行する必要はありません。これが AWS CodeBuild を利用することの最大の利点です。
terraform planとterraform applyを再度実行するために、それぞれの AWS CodeBuild プロジェクトを起動します。
(翻訳者補足: AWS CodeBuild プロジェクトを起動する前にterraform init -migrate-stateコマンドをローカルで実行することで、ローカルに保存されている State を Amazon S3 バックエンド に引き継ぐことができます。コマンドの仕様については ドキュメント を参照してください。)
(翻訳者補足: AWS CodeBuild プロジェクトを起動する前に、「インフラストラクチャの準備」で作成した AWS CodeCommit リポジトリにソースコードを Push しておく必要があります。CodeBuild プロジェクトはこのソースコードを参照して動作します。)- デプロイが成功したら、作成した AWS Lambda 関数でコードをテストしてみましょう。Lambda 関数をテストする手順は以下のとおりです。(コンソールでの作業になります)
-
- AWS Lambda コンソールを開き、関数「tf-codebuild」を選択します。
- ナビゲーションペインの Code セクションで、Test をクリックしてテストイベントを作成します。
- イベント名 (例えば「test-lambda」) を指定します。
- 他はデフォルト値のまま Save をクリックします。
- Test を再度クリックして、テストイベント「test-lambda」を起動します。
Lambda 関数は、main.py ファイルに記述してあるサンプルメッセージを返すはずです。
デフォルトでは以下に示すように「Hello from AWS Lambda !」のメッセージが表示されます。
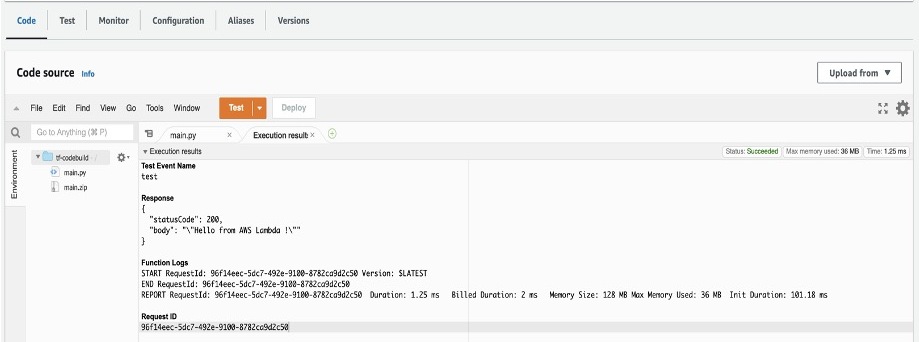
図3: サンプル Lambda 関数のレスポンス
- State ファイルを確認するには、Amazon S3 コンソールに移動し、作成されたバックエンドバケット (tfbackend-bucket) を選択してください。 State ファイルが含まれているはずです。
(翻訳者補足: ここでは「インフラストラクチャの準備」のセクションで作成した s3 バケットを選択してください。)
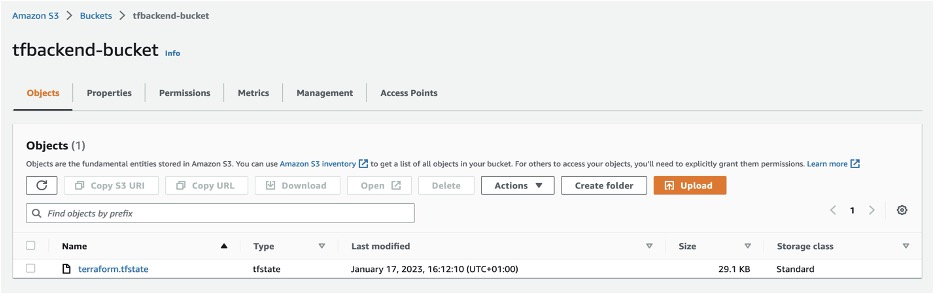
図4: Terraform の State ファイルが保存された Amazon S3 バケット
- Amazon DynamoDB コンソールを開き、テーブル tfstate-lock を確認してみてください。LockID を持つエントリがあるはずです。
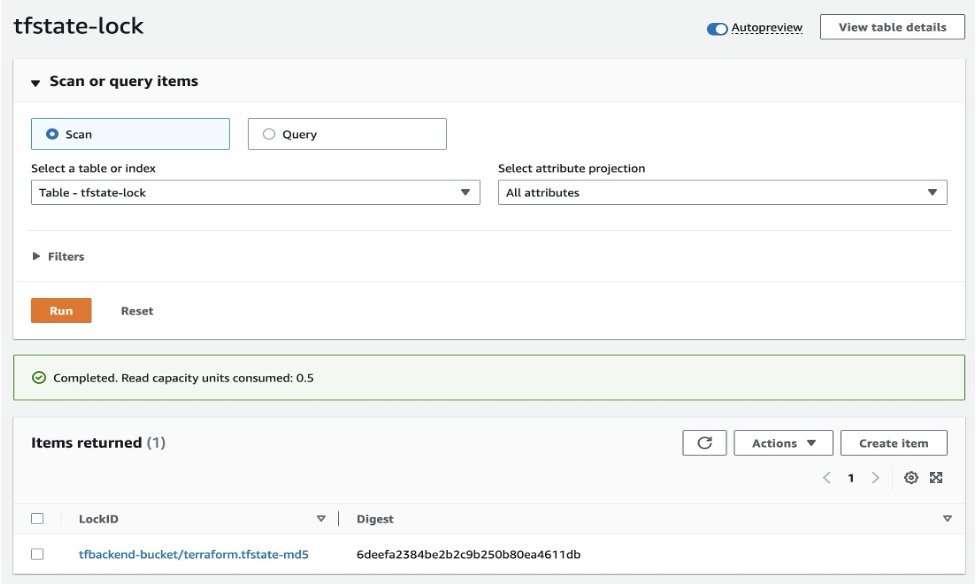
図5: LockID を持つエントリが登録された Amazon DynamoDB テーブル
このように、継続的インテグレーションパイプラインから Terraform のリモートバックエンドを利用して、 Terraform State ファイルを安全に保存しロックすることができました。
クリーンアップ
リポジトリから作成されたすべてのリソースを削除するには、ターミナルから以下のコマンドを実行してください。
terraform destroy
まとめ
このブログ記事では、Terraform の State ファイルの基本を掘り下げ、AWS 環境内での安全な保存のためのベストプラクティスと、ファイルをロックして不適切な同時アクセスを防ぐメカニズムについて説明しました。そして最後に、AWS 上の継続的インテグレーションパイプラインで、それらをいかに効率的に管理できるかの例を示しました。
AWS 上の 継続的デリバリー パイプラインでも、State ファイルを管理するために同じ方法が適用できます。
より詳細を知りたい場合は、AWS での CI/CD パイプライン、Terraform バックエンドの種類、Terraform State の目的をご覧ください。
著者について
本記事は 2024/02/19 に投稿された Best practices for managing Terraform State files in AWS CI/CD Pipeline を翻訳したものです。翻訳は Solutions Architect : 国兼 周平 (Shuhei Kunikane) が担当しました。