Amazon Web Services ブログ
Category: Amazon Simple Storage Service (S3)

井村屋グループ様:Amazon SageMaker Canvas を活用したチルド製品の AI 需要予測で、業務工数 90% 削減と熟練者同等の予測精度を実現
本ブログは井村屋グループ株式会社様、株式会社 Hashup 様、Amazon Web Services Jap […]
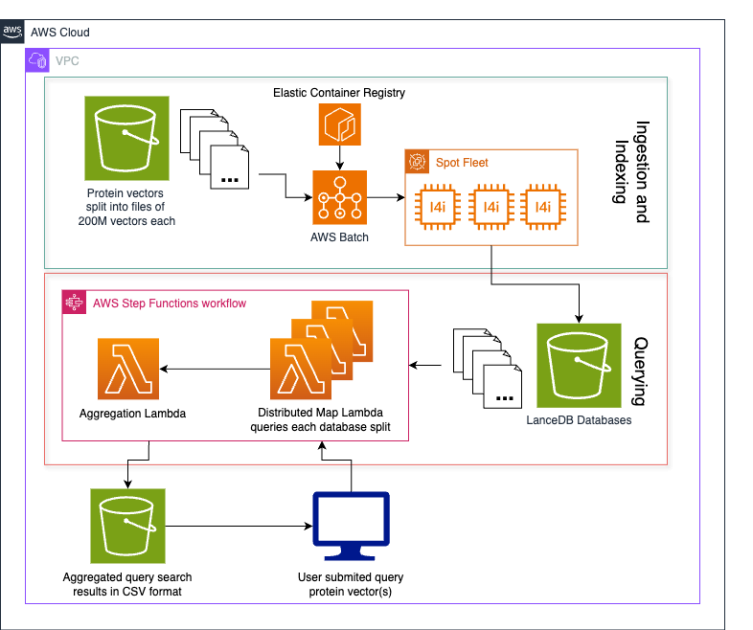
Metagenomi が LanceDB と Amazon S3 で実現した 10 億ベクトル超のスケーラブルな検索基盤
Metagenomi は LanceDB、Amazon S3、AWS Lambda を組み合わせ、35 億件のタンパク質エンベディングを低コストで保存・検索するサーバーレスソリューションを構築しました。データをバケット分割して並列インデックス化し、map-reduce 方式で検索する設計により、常時稼働サーバーなしで数十億ベクトル規模の近似最近傍検索を実現しています。

AWS 週間まとめ:NY Summit の振り返り、ハノイでのローカルゾーン、Bedrock での Grok 4.3、価格引き下げなど(2026年6月22日)
2026 年 6 月 15 日週、AWS Summit New York City では、何千人ものお客様、パ […]

ニューヨークで開催される 2026 年の AWS Summit に関する主要なお知らせ
2026 年 6 月 17 日、ニューヨーク市で開催された AWS Summit では、AWS VP of A […]

Amazon S3 アノテーション: クエリ可能かつリッチなコンテキストをオブジェクトに直接アタッチ
2026 年 6 月 16 日、Amazon Simple Storage Service (Amazon S […]
経済産業省 GENIAC 基盤モデル開発支援事業 (第4期) における採択事業者への支援を開始
2026年6月4日、経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構 (NEDO) が実施する […]
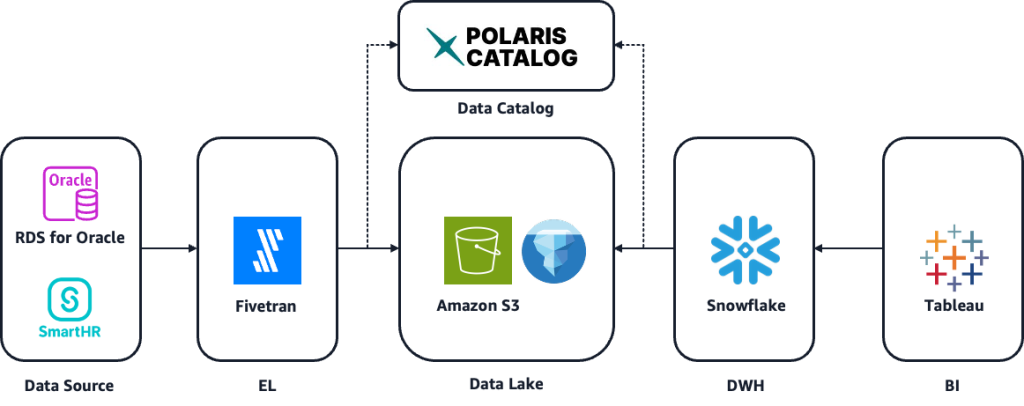
Fivetran の CDC 機能で実現するラーメン山岡家の Iceberg on AWS データパイプライン
ラーメンチェーン「山岡家」を展開する株式会社丸千代山岡家が、Fivetran の CDC(Change Data Capture)機能を活用して Amazon RDS for Oracle から Amazon S3 上の Apache Iceberg テーブルへのデータ同期を実現した事例をご紹介します。アーキテクチャの検討プロセスや Fivetran 採用の理由、約 5 分のデータ反映、月あたりの運用工数を 6 日から 0.5 日に削減、PoC から本番稼働まで約 1 ヶ月という短期導入といった導入効果を解説します。
サーバーレス関連の見逃し情報 2025 年第 4 四半期
お知らせ 2026年7月からオンラインでサーバーレスに関するワークショップを4件開催します。ぜひ、ご参加くださ […]

AI ツールで実現する継続収益ビジネス 〜開発力を資産に変える〜 – AWS Local Executive Roadshow 大阪編(#2/8)開催レポート
こんにちは。Amazon Web Services Japan のソリューションアーキテクト、田中 里絵 です […]

実践企業に学ぶ生成 AI 導入の勘所 〜眠るデータを企業価値に変える〜 – AWS Local Executive Roadshow 大阪編(#1/8)開催レポート
こんにちは。Amazon Web Services Japan のソリューションアーキテクト、田中 里絵 です […]