Amazon Web Services ブログ
Category: Amazon Simple Storage Service (S3)

リアルタイム分析ダッシュボードを備えた Innovation sandbox on AWS
本記事は、2026 年 1 月 28 日に公開された “Innovation sandbox on […]

AWS Weekly Roundup: Amazon Bedrock での Claude Mythos のプレビュー、AWS Agent Registry など (2026 年 4 月 13 日)
前回の Week in Review に、2026 年、お客様との AI-Driven Development […]

S3 Files の提供開始 – S3 バケットがファイルシステムとしてアクセス可能に
Amazon S3 Files の提供が開始されました。S3 Files は S3 バケットをファイルシステムとしてアクセスできる新機能で、EC2 インスタンス、ECS/EKS コンテナ、Lambda 関数から NFS v4.1 以降でマウントできます。アクティブなデータに対して約 1 ミリ秒のレイテンシーを実現し、複数のコンピューティングリソースからの同時アクセスをサポートします。

AWS Deadline Cloud のサービスマネージドフリートで 3ds Max を使う方法
本記事では、AWS Deadline Cloud のサービスマネージドフリート (SMF) 上で Autodesk 3ds Max を使用する方法を紹介します。設定スクリプトを活用して 3ds Max をフリートワーカーにインストールし、マネージドインフラストラクチャの利便性とレンダリングパイプラインの柔軟性を両立する手順を解説します。

Fivetran の Managed Data Lake Service の CDC で実現する業務システムから Apache Iceberg へのリアルタイムデータ連携
本記事は アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト 疋田、畠 と、Fivetr […]
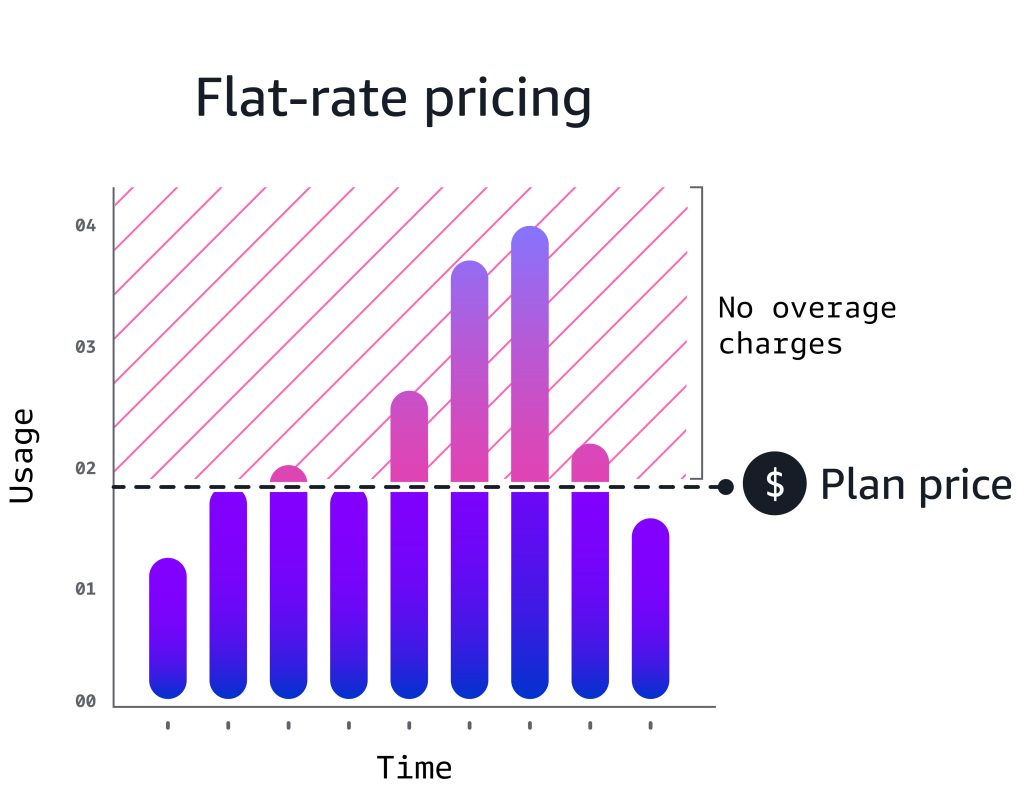
Amazon CloudFront 定額料金プラン:新機能と対応機能の拡大
Amazon CloudFront は定額料金プランのリリース以降、お客様からいただいたフィードバックをもとに新しい機能を追加してきました。この記事では、 Lambda@Edge のサポート、 CAPTCHA 、相互 TLS (mTLS) 、そして AI ボットやエージェントのトラフィックを可視化する AI アクティビティダッシュボードなど、最新の追加機能をご紹介します。また、使用量の上限を超えたトラフィックの扱いについても明確化しています。

AWS Weekly Roundup: 20 周年を迎えた Amazon S3、Amazon Route 53 Global Resolver の一般提供など (2026 年 3 月 16 日)
Amazon S3 の一般提供が開始されたのは、20 年前の先週にあたる 2006 年 3 月 14 日でした […]
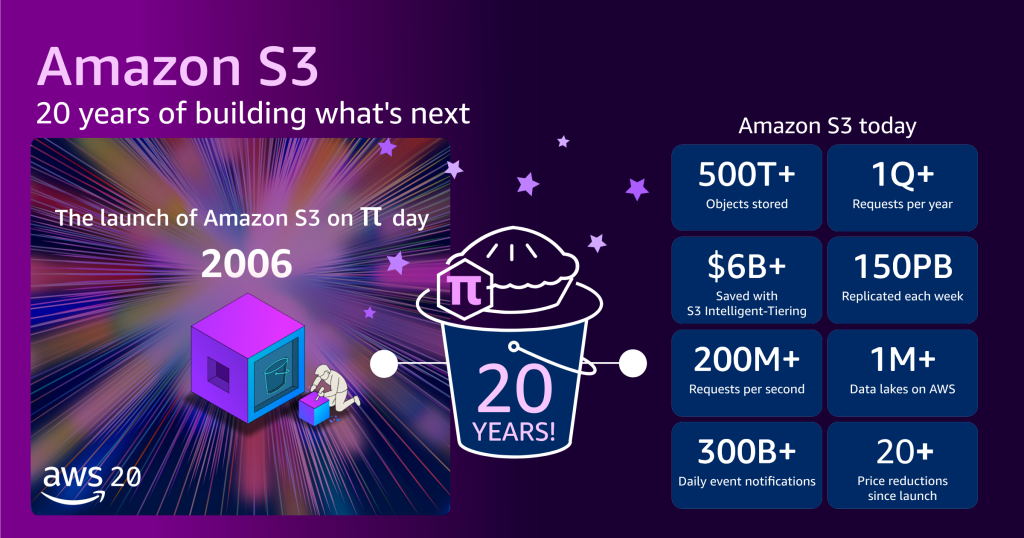
Amazon S3 の 20 年を振り返り、未来を築く
今から 20 年前の 2006 年 3 月 14 日、Amazon Simple Storage Servic […]

Amazon S3 汎用バケットのアカウントリージョナル名前空間の紹介
2026 年 3 月 12 日、Amazon Simple Storage Service (Amazon S […]

2026 年 2 月の AWS Black Belt オンラインセミナー資料及び動画公開のご案内
2026 年 02 月に公開された AWS Black Belt オンラインセミナーの資料及び動画についてご案内させて頂きます。
動画はオンデマンドでご視聴いただけます。