Amazon Web Services ブログ
Category: Amazon Neptune

AWS Japan Summit 2026 スマートマシンデモ ー自律診断とリアルタイム安全監視ー 展示報告
はじめに 2026年6月25日、26日に幕張メッセで開催された AWS Summit Japan 2026にお […]

ナレッジグラフと IoT データによる生産ラインのボトルネック分析 〜AI エージェントのための製造データの構造化〜
はじめに こんにちは、IoT Specialist ソリューションアーキテクトの新澤です。2026 年 6 月 […]

BIM データを生成 AI で活用する: IFC を RDF グラフに変換し Amazon Neptune で問い合わせるアーキテクチャ
建設業界で導入が進む BIM には、建物の豊富なデータが蓄積されています。本ブログでは、このデータを生成 AI から自然言語で問い合わせる方法として、BIM のオープンな標準フォーマットである IFC を RDF グラフに変換して Amazon Neptune に格納し、AI エージェントが text-to-SPARQL で回答する仕組みを、実装レベルで解説します。
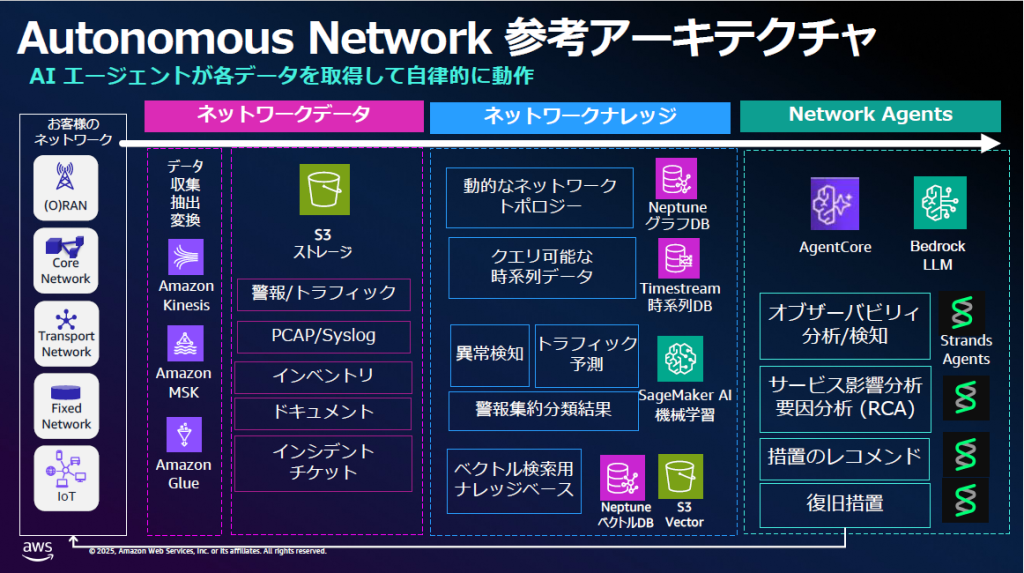
【開催報告】通信ネットワーク運用向け AI エージェントワークショップ開催しました! ( 2025 年 11 月 27 日 )
通信業界のネットワーク運用ではより安定した通信ネットワークを提供するために、障害の検知、要因特定、復旧を早期に […]
グラフデータを使用した Network Digital Twin と Agentic AI を活用した被疑箇所の特定
本記事は 2025 年 8 月 18 日に公開された Beyond Correlation: Finding […]
株式会社リネア様の AWS 生成 AI 事例:GraphRAGで実現するサプライチェーンリスク検知と管理への取り組み
みなさん、こんにちは。AWS ソリューションアーキテクトの古屋です。 企業のESG(環境・社会・ガバナンス)へ […]

Amazon Finance Automationが重要な財務アプリケーションを動かすため、AWSの目的特化型データベースを使って業務データストアを構築した事例について
Amazon Finance Automation (FinAuto) は Amazon Finance Op […]
【開催報告】AWS Summit Japan 2025 建設・不動産向けブース展示
AWS Summit Japan 2025の建設・不動産向けブース展示では、「デジタルの力で、建設・不動産の”当たり前”を革新する」をテーマに、3つの革新的なソリューションが紹介されました。
まず、RAPID(AI書類審査ソリューション)は、大量の文書審査作業を効率化し、AIによる判断根拠の透明性を確保しながら、人間の確認プロセスと組み合わせた実用的なシステムを提供します。
次に、CEDIXは建設現場のカメラ映像を活用した革新的なソリューションで、様々なカメラからの映像を一元管理し、生成AIによる分析で安全管理や現場監視の効率化を実現します。特に、工事の進捗に応じて柔軟に監視内容を変更できる特徴があります。
最後に、IFC With GraphRAGは、BIMデータの活用を促進するソリューションとして、専門知識がなくても自然言語での問い合わせが可能で、建物情報への直感的なアクセスを実現します。これにより、BIMの活用範囲を大きく広げることが期待されます。
これらのソリューションは、建設・不動産業界のデジタルトランスフォーメーションを加速させる重要な役割を果たすことが期待されています。

AWS Summit Japan 2025 ~ 生成 AI とグラフデータを活用した 業務横断データ活用(Digital Thread)の展示のご紹介
製造業におけるデータの活用はビジネスの成功に不可欠な要素となっていますが、一方で多くの企業は、業務をまたいだデータを包括的に活用することは難しいと感じています。実際、ものづくり白書2025でも、DX の具体的成果が半分以下しか出ていない、と報告されています。この理由の一つとしては、部門や関連会社ごと、さらに部門内のシステムも CRM、PLM、ERP、MES/MOM などに散らばってデータが保存されているからです。このブースでは、データ活用のハードルを下げる提案の一つとして、e-Bike の仮想的なビジネスのデータを集約し、グラフデータと生成 AI を組み合わせ、業務横断のデータ (Digital Thread) の活用を実現するアプリケーションを展示しています。

AWS Entity Resolution と Amazon Neptune を使用して顧客の 360 度ビューを作成
このブログ記事では、AWS における組み合わせ可能なアーキテクチャパターンについて説明します。このパターンは、データエンジニアリングチームが顧客の 360 度ビューをマーケターに提供するために必要な、データの取り込み、マッチング、クエリのソリューションを構築する際に役立ちます。このブログでは、AWS Entity Resolution と Amazon Neptune を使用して、高精度、低コスト、かつ柔軟な設定が可能な統合顧客ビューを開発するために、関連する顧客情報をどのように接続するかを学びます。