Amazon Web Services ブログ
Category: Amazon SageMaker

Chronos-2 on Amazon SageMaker AI にアクセスする3つのパターン – AutoGluon-Cloud v0.5.0 で数行に
みなさん、こんにちは。ソリューションアーキテクトの 寺山です。 AutoGluon-Cloud v0.5.0 […]

AIで変える鉄道保全と、「クローズド」を読み解くクラウド設計 — AWS Summit Japan 2026 展示ブース開催報告
2026年6月25日〜26日、幕張メッセで開催された AWS Summit Japan 2026 にて、AWS […]
株式会社Diverse が Amazon SageMaker で実現した「温度感」ベースのマッチング体験
はじめに 本ブログは 株式会社Diverse 様と Amazon Web Services Japan 合同会 […]

AWS Weekly Roundup: AWS Builder Center 1 周年、セキュリティハブにおけるネットワークスキャン、Loom for AWS など (2026 年 7 月 13 日)
AWS Builder Center は 2026年 7 月 6 日週、提供開始から 1 周年を迎えました。2 […]
井村屋グループ様:Amazon SageMaker Canvas を活用したチルド製品の AI 需要予測で、業務工数 90% 削減と熟練者同等の予測精度を実現
本ブログは井村屋グループ株式会社様、株式会社 Hashup 様、Amazon Web Services Jap […]

AWS Weekly Roundup: AWS での Claude Sonnet 5、AI エージェント向けの Amazon WorkSpaces、AWS サービスの可用性アップデートなど (2026 年 7 月 6 日)
数回前の号で、スタートアップと仕事をすることがどれほど活力になるかについて書きました。2026 年 6 月 2 […]

東海旅客鉄道株式会社:超電導リニアの電気設備保守を支える IoT プラットフォームの構築
このブログは、東海旅客鉄道株式会社(以下、JR 東海)中央新幹線推進本部 リニア開発部 藤原 海渡氏と、アマゾ […]

【開催報告 & 資料公開】公共分野における AI 活用最新アップデート (AWS 公共セミナー 2026 年)
こんにちは。アマゾン ウェブ サービス ジャパン合同会社 パートナー ソリューション アーキテクト の深井宣之 […]
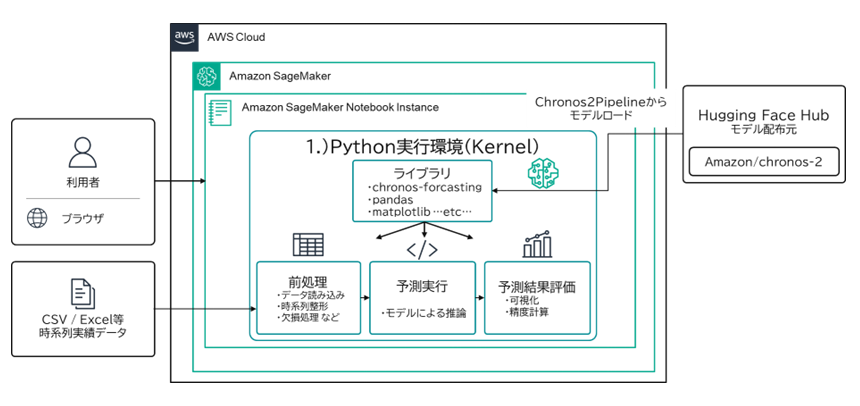
キヤノンIT ソリューションズ様と取り組むホテルのフードロス削減 – 時系列基盤モデル Chronos-2 で最適な提供量を予測する
本ブログでは、サステナビリティを組み込む取り組みの一例として、キヤノンITソリューションズ様と共同で取り組んだ Chronos-2 による需要予測を起点としたフードロス削減 PoC について、アーキテクチャと技術的なポイントをご紹介します。

2026 AWS Life Sciences Symposium ハイライト:創薬研究領域
英語版ブログ: “ Highlights from the 2026 AWS Life Sciences Sy […]