Amazon Web Services ブログ
Category: Amazon SageMaker

AI ツールで実現する継続収益ビジネス 〜開発力を資産に変える〜 – AWS Local Executive Roadshow 大阪編(#2/8)開催レポート
こんにちは。Amazon Web Services Japan のソリューションアーキテクト、田中 里絵 です […]

AUMOVIO が Amazon Bedrock 搭載のエージェント型コーディングアシスタントでソフトウェア開発を強化
本ブログ記事では、AUMOVIO が Amazon Web Services (AWS) のサービスと知見を活用して、Software-Defined Vehicle (SDV) 領域における革新的な自動車向けコーディングアシスタントを開発した事例をご紹介します。AUMOVIO のソリューションは、複数の AI モデルを活用して開発ライフサイクルの各工程を加速させながら、自動車業界の標準と AUMOVIO 独自のコーディングベストプラクティスに準拠しています。可能な限りコードを再利用し、変更を最小限に抑えることで、このアシスタントは V 字モデルの他の工程に必要な作業を大幅に削減します。

AWS Weekly Roundup: AWS AI/ML Scholars プログラム、Agent Plugin for AWS Serverless など (2026 年 3 月 30 日)
2026 年 3 月 23 日週の出来事で私が最も心を躍らせたのは、AWS Agentic AI バイスプレジ […]
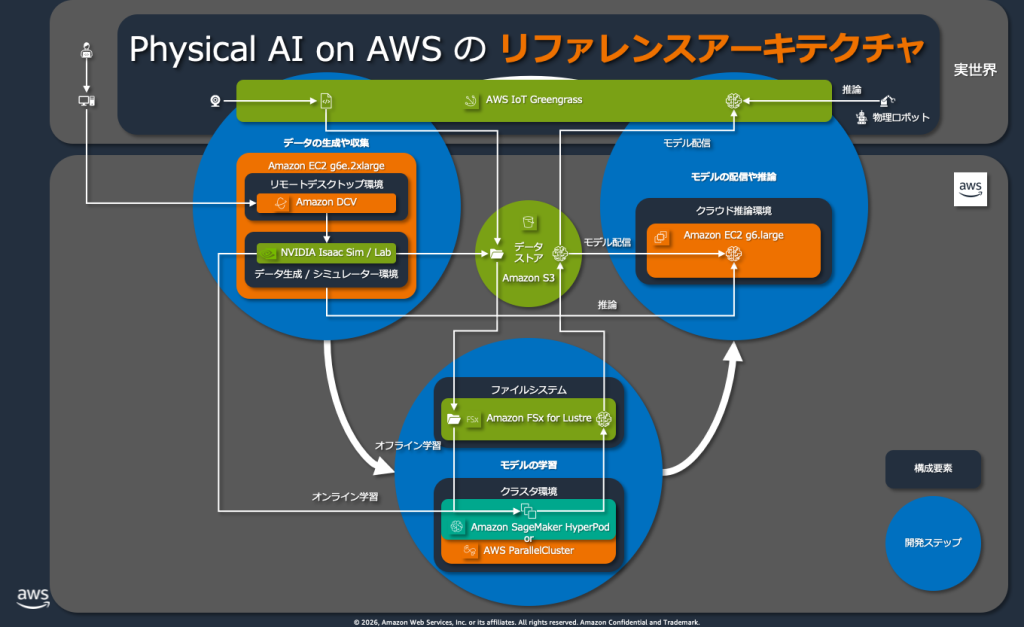
「Physical AI on AWS 勉強会 #1」を開催しました
2026 年 3 月 24 日、アマゾン ウェブ サービス ジャパン合同会社(以下、AWS ジャパン)は、「フ […]

AWS Weekly Roundup: Amazon Bedrock の Claude Sonnet 4.6、Kiro in GovCloud リージョンの Kiro、新しいエージェントプラグインなど (2026 年 2 月 23 日)
2026 年 2 月 16 日週、私のチームは米国サンノゼで開催された Developer Week で大勢の […]

カスタム Amazon Nova モデル用の Amazon SageMaker Inference の発表
AWS New Summit 2025 で Amazon SageMaker AI の Amazon Nova […]
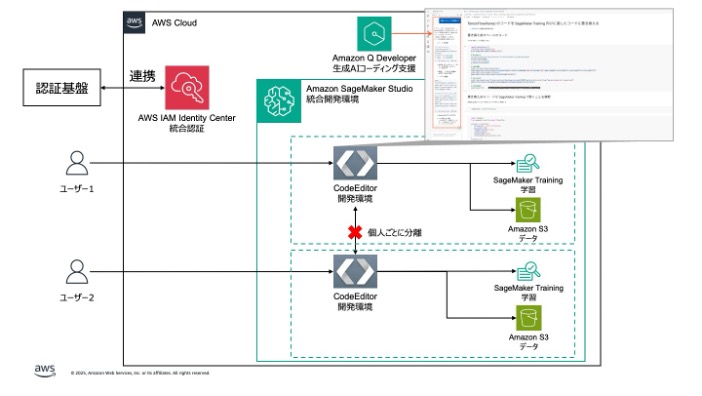
寄稿: JFE スチールが挑むインテリジェント製鉄所への道 – Amazon SageMaker AI による CPS 開発実行基盤の構築
JFE スチール株式会社における Amazon SageMaker AI を中核とした CPS 開発実行基盤の構築事例をご紹介します。ブログの中では、プロジェクトの背景、開発体制、AWS の活用方法、そして今後の AWS IoT Greengrass によるエッジ配信基盤の展開についても解説します。
Agentic workflowを使用したAmazon Nova Premierによるコード移行の効率化
多くの企業は、保守と拡張が困難になった古いテクノロジーで構築されたレガシーシステムに悩まされています。 この投 […]
自動車および製造業界むけ AWS re:Invent 2025 のダイジェスト
AWS の年次フラッグシップイベントである AWS re:Invent 2025 は、 2025 年 12 月 […]

サーバーレス MLflow で Amazon SageMaker AI を使用して AI 開発を加速
2024 年 6 月に MLflow を搭載した Amazon SageMaker AI を発表して以来、弊社 […]