Amazon Web Services ブログ
Category: Amazon EMR
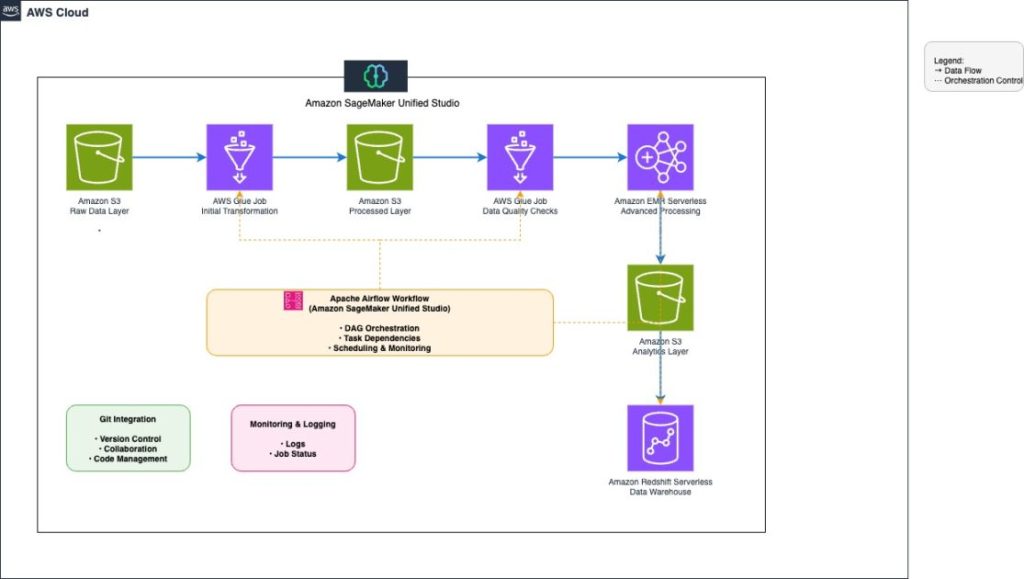
Amazon SageMaker ワークフローによるスケーラブルなエンドツーエンド ETL パイプラインのオーケストレーション
本記事では、Amazon SageMaker Unified Studio ワークフローでコードベースのエンドツーエンド ETL パイプラインを構築・管理する方法を紹介します。AWS Glue、Amazon EMR Serverless、Amazon Redshift Serverless、Amazon MWAA を組み合わせ、EC の顧客行動分析を例に、データ取り込みから変換、品質チェック、データウェアハウスへのロード、日次スケジュール実行まで、単一の統合 UI で構築する手順を解説します。

AWS Weekly Roundup : Anthropic と Meta のパートナーシップ、AWS Lambda S3 ファイル、Amazon Bedrock AgentCore CLI など (2026 年 4 月 27 日)
3 月下旬、世界中の AWS スペシャリストが集まる最も活気あふれるイベントの 1 つである Speciali […]
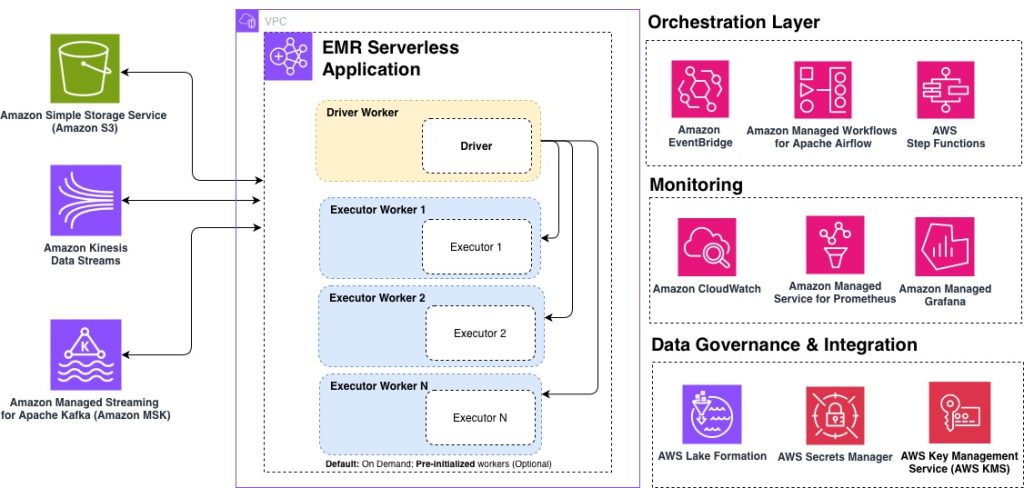
Amazon EMR Serverless のベストプラクティス 10 選
Amazon EMR Serverless のパフォーマンス、コスト、スケーラビリティを最適化するためのベストプラクティス 10 選を紹介します。アプリケーション設計、ワーカーの適正化、Graviton プロセッサの活用、ストレージ選択、マルチ AZ 構成など、効率的なデータ処理パイプラインの構築に役立つ実践的な推奨事項をまとめています。

自動車および製造業界むけ AWS re:Invent 2025 のダイジェスト
AWS の年次フラッグシップイベントである AWS re:Invent 2025 は、 2025 年 12 月 […]
Amazon S3 ストレージレンズにパフォーマンスメトリクスの追加、数十億のプレフィックスのサポート、S3 Tables へのエクスポートが追加されました
2025 年 12 月 2 日、ストレージのパフォーマンスと使用パターンをより深く理解できる Amazon S […]

Apache Iceberg V3 の deletion vectors と row lineage でデータレイク操作を高速化する
Apache Iceberg V3 では deletion vectors と row lineage が導入されました。AWS は Amazon EMR、AWS Glue、Amazon SageMaker、Amazon S3 Tables、AWS Glue Data Catalog でこの機能を提供しています。本記事では、新機能の概要、業界横断のユースケース、AWS サービスでの実装方法を紹介します。

Amazon EMR Serverless の可観測性、パート 1: Amazon CloudWatch を使用した Amazon EMR Serverless ワーカーのニアリアルタイムでのモニタリング
Amazon EMR Serverless を使用すると、クラスターやサーバーを管理することなく、Apache […]

AWS Weekly Roundup: Amazon Bedrock、AWS Amplify Gen 2、Amazon RDS などの新機能 (2024 年 5 月 13 日)
AWS Summit は世界各国で最高潮を迎えており、最近では AWS Summit Singapore が開 […]

2024 年 2 月と 3 月の AWS Black Belt オンラインセミナー資料及び動画公開のご案内
2024 年 2 月と 3 月に公開された AWS Black Belt オンラインセミナーの資料及び動画についてご案内させて頂きます。
動画はオンデマンドでご視聴いただけます。
AWS 上での BMW Group による自動運転のためのデータ処理とデータ管理のスケーリング
このブログは、Scaling Automated Driving data processing and da […]