Amazon Web Services ブログ
Category: Amazon Athena
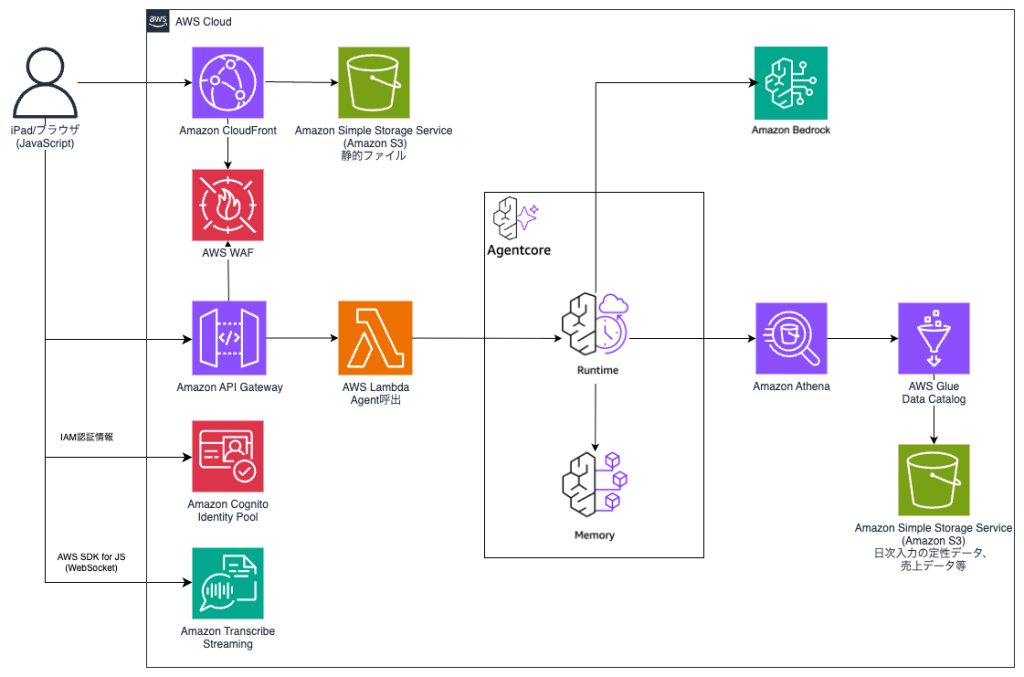
店舗の気づきを本部に届ける AI エージェント SMART のご紹介 — Amazon Bedrock AgentCore × Strands Agents によるユナイテッドアローズでの取り組み
本記事では、AWS サンプルアセットである AI エージェント SMART(Store Manager Agent for Retail Tech) についてのご紹介と、それを活用した株式会社ユナイテッドアローズ(以下、ユナイテッドアローズ)の取り組みについてご紹介します。小売業にとって、店舗の声をどう本部に届けるかは永遠のテーマです。売上数字の裏には、現場スタッフだけが感じている気づきが必ずあります。しかし店舗の日報や週報のフォーマットだけでは、その気づきを届けるのは難しいのが実情です。SMART は、店舗の気づきを AI の力で引き出し言語化して、本部に届けることを支援するために誕生しました。

AWS Cost and Usage Reports データを使用したセキュリティリスクの特定
AWS の請求書からわかるのは、支出パターンだけではありません。セキュリティ上の問題を特定することもできます。 […]

Fivetran の Managed Data Lake Service の CDC で実現する業務システムから Apache Iceberg へのリアルタイムデータ連携
本記事は アマゾン ウェブ サービス ジャパン合同会社 ソリューションアーキテクト 疋田、畠 と、Fivetr […]

BMW Group が AWS 上のエージェンティック検索でペタバイト規模のデータからインサイトを引き出す
BMW Group が AWS 上でエージェント検索ソリューションを構築し、ペタバイト規模のデータからインサイトを引き出す取り組みを紹介します。同社の Cloud Data Hub は 20 PB のデータを保存し、1 日平均 110 TB を取り込んでいますが、従来は専門知識がないユーザーにとってデータ分析が困難でした。AWS Professional Services と協力し、Amazon S3 Vectors、Amazon Bedrock、Strands Agents を組み合わせたソリューションを開発。ハイブリッド検索、網羅的検索、SQL クエリの 3 つのアプローチにより、技術スキルに関係なく自然言語でデータにアクセス可能になりました。サーバーレスアーキテクチャによりコスト効率も実現しています 。

【寄稿】SIEMからデータ基盤へ – 三井物産デジタルアセットマネジメントのAWS Security Lake活用事例
こんにちは。ソリューションアーキテクトの松本 敢大です。三井物産デジタル・アセットマネジメント株式会社(以下、 […]

AWS で DER アグリゲーター向けのスケーラブルな DERMS ソリューションを構築する
エネルギー環境が分散型モデルへと進化する中、分散型エネルギーリソース (DER) は、エネルギー市場のさまざまなプレーヤー (電力会社、立法機関、アグリゲーター、消費者、サービスプロバイダー) に課題と機会の両方をもたらしています。
さまざまな関係者が Amazon Web Services (AWS) を活用して DER を最大限に活用する方法について、一連のブログを計画しています。最初のブログでは、アグリゲーターが事業の成長に合わせて拡張できる堅牢な分散型エネルギーリソース管理システム (DERMS) を構築するために、AWS サービスがどのように役立つかを探ります。

Amazon FSx for NetApp ONTAP が Amazon S3 と統合され、シームレスなデータアクセスが可能になりました
2025 年 12 月 2 日、Amazon Simple Storage Service (Amazon S […]
Amazon S3 ストレージレンズにパフォーマンスメトリクスの追加、数十億のプレフィックスのサポート、S3 Tables へのエクスポートが追加されました
2025 年 12 月 2 日、ストレージのパフォーマンスと使用パターンをより深く理解できる Amazon S […]
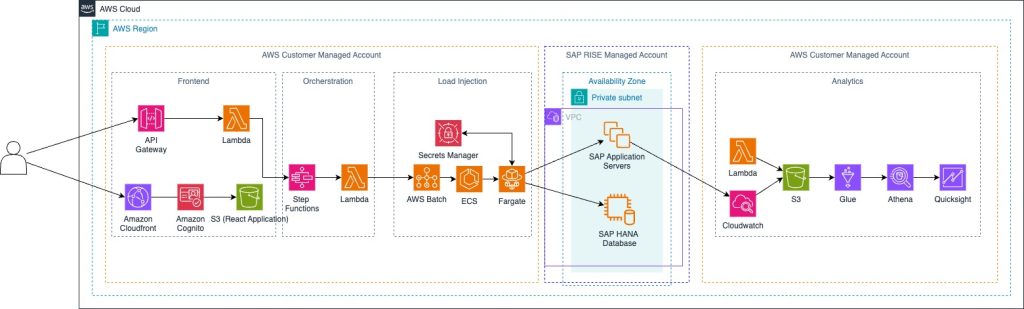
SAPの負荷テスト:AWSによるサーバーレスアプローチ
SAPシステムの適切な負荷テストを実施することは、ピーク使用時にシステムがビジネスのパフォーマンスと信頼性の期待に応えられることを保証する主要な要因です。負荷テストが必要となる典型的なシナリオには、新しい会社/国の展開、ECCからS/4HANAへのソフトウェアリリースアップグレード、アプリケーションパッチ(例:サポートパッケージ)、S/4HANA変革プロジェクト、またはSAP RISEへの移行があります。このような大規模な変更後の安定した運用を確保するため、潜在的なパフォーマンス関連の問題を回避するために、本番カットオーバー前に負荷テストを実行することが推奨されます。このブログでは、オンプレミスまたはRISEにデプロイされたSAP ERPシステムに異なるタイプの負荷を注入するために、AWS上で負荷テストプラットフォームを実装し使用する方法を学びます。

Amazon Connect Cost Insight Dashboard によるコストの可視化と最適化
コンタクトセンターのリーダーは常にコストの可視化を求めています。この記事ではコンタクトセンターのコスト情報を可視化する Amazon Connect Cost Insight Dashboard について紹介しています。このダッシュボードは月次コストトレンドの追跡、サービスコンポーネント別のコスト分析、通話料の分析などの機能を提供し、コンタクトセンターマネージャーが情報に基づいた適切な意思決定を行い、運用を最適化するためのデータを提供します。