Amazon Web Services ブログ
Category: Amazon Athena
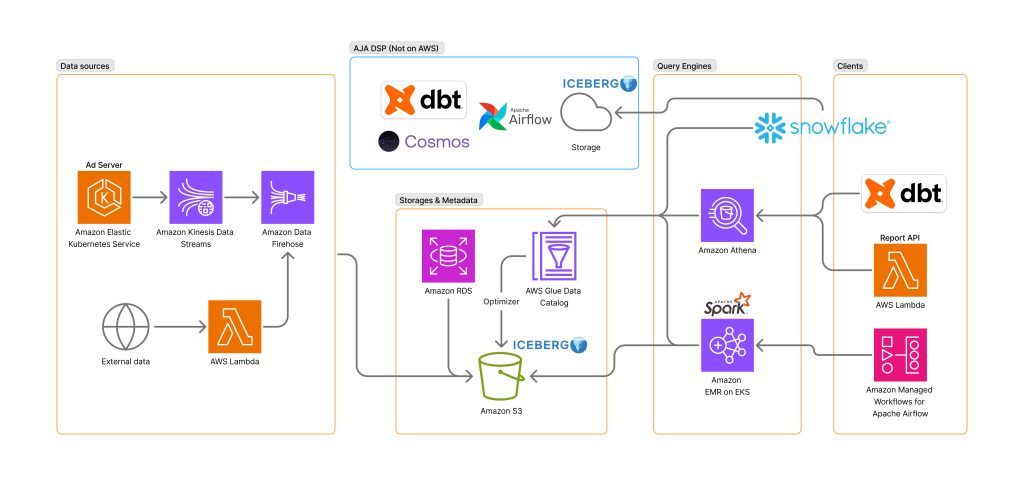
AJA SSP が Apache Iceberg と AWS Glue Data Catalog でペタバイトスケールのデータ基盤の柔軟なクエリエンジンの選択とクエリの高速化を実現
※ この記事はお客様に寄稿いただき、AWS が加筆・修正したものとなっています。 株式会社 AJA は、株式会 […]

AWS Weekly Roundup: 新しい AWS ヒーロー、Amazon Q Developer、EC2 GPU の値下げなど (2025 年 6 月 9 日)
AWS ヒーロープログラムは、知識を共有したいという熱意によってコミュニティ内に真の影響をもたらしている、活気 […]

組織全体で Amazon Connect のフロー操作を監査する方法
コンタクトセンター運営における包括的な監査証跡の取得と一元的な可視性の維持は、セキュリティ、コンプライアンス、および運用のベストプラクティスの観点で重要です。Amazon Connect は、さらに Amazon Connect コンソールのフロー管理アクティビティに対応し、ユーザーがフローを追加、更新、または削除するたびに、その活動の記録が CloudTrail ログに取得できるようになりました。 この記事では、お客様が AWS 環境全体で Amazon Connect のフロー管理のアクティビティを一元的に分析および監査する方法について詳しく説明します。

AWS Savings Plans: 効果的なチャージバック戦略を実装する方法
組織が成長するにつれて、クラウドインフラの管理はますます複雑になり、コストを最適化するための高度な財務戦略が必 […]

AWS の生成 AI を活用してリテールインサイトを変革する
グローバルな高級ファッションブランドを擁し、世界中に 1,400 を超える小売店舗を展開し、18,000 人を超える従業員を抱える Tapestry は顧客体験の改善に役立つ豊富な情報を保有しているものの、それを十分に活用できているとは言えませんでした。そこで生成 AI エンジンを活用して、店舗従業員からのフィードバックを収集・分析するアプリケーション「Tell Rexy」と「Ask Rexy」を構築した結果、店舗オペレーション、在庫管理、顧客嗜好に関する前例のないインサイトを得ることができ、アプリケーションを従来より10倍早くリリースできるようになりました。

AWS を活用した公共部門向けデータ配信
組織が情報に基づいた意思決定を行い、イノベーションを促進するためには、データの共有が不可欠です。 アマゾン ウェブ サービス (AWS) は、大規模なデータを安全に配信するためのさまざまなツールとサービスを提供しています。 公共の利益のためにオープンデータの公開、ビジネス目的でのプライベートデータセットの収益化、さらには社内での協業などの用途で、AWS は必要なインフラストラクチャとサポートを提供します。詳細については、この投稿をお読みください。

株式会社iimon 様の SaaS のデータ分析事例 : データ分析基盤を導入することで、カスタマーサポートチームがユーザーの解約リスクを発見する時間を8割程度削減し、サービス継続率 99% に貢献
本記事では AWS 上で 自社 SaaS データ分析基盤を構築し、「提供している様々な機能を、より多くの SaaS ユーザーに活用してもらうこと」 や 「SaaS ユーザーのデータに基づく営業活動の推進」 を実現された株式会社iimon 様の事例をご紹介します。

Iberdrola が AWS の IoT/エッジサービスを活用して配電設備のインシデントを削減した方法
この記事は、「Iberdrola reduces incidents at power distributio […]

Amazon SageMaker Lakehouse の統合アクセスコントロールが Amazon Athena フェデレーションクエリで利用可能に
12 月 3 日、データ、分析、AI の統合プラットフォームである次世代の Amazon SageMaker […]

Amazon SageMaker Canvas でノーコード機械学習を行うために Google Cloud Platform BigQuery からデータをインポートする
現代のクラウド中心のビジネス環境では、データが複数のクラウドやオンプレミスのシステムに分散していることが多くあります。この断片化は、お客様が機械学習 (ML) イニシアチブとして、データを統合し、分析する作業を複雑にしています。
本稿では、さまざまなクラウド環境の中でも Google Cloud Platform (GCP) BigQueryに焦点を当て、データソースを移動することなく、データを直接抽出するアプローチをご紹介します。これにより、クラウド環境間でデータ移動の際に発生する複雑さとオーバーヘッドを最小限に抑えることができるため、組織は ML プロジェクトで様々なデータ資産にアクセスし、活用できるようになります。