Amazon Web Services ブログ
Category: Technical How-to
AWS KMS と AWS Encryption SDK が対称暗号化の境界を克服する仕組み
大量のデータを暗号化する大規模アプリケーションでは、AES-GCM の暗号化限界の追跡や鍵のローテーションが課題になります。本記事では、AWS KMS と AWS Encryption SDK が派生鍵方式を用いて、暗号化のたびに一意の鍵を生成し、AES-GCM の呼び出し限界やデータ境界を自動的に処理する仕組みを解説します。鍵導出関数 (KDF) やノンスの活用により、手動管理を不要にする方法を詳しく説明します。

9 社合同 AI-DLC Unicorn Gym 大阪 ── AI と開発した 3 日間で見えた、人間の仕事
みなさん、こんにちは。ソリューションアーキテクトの池田、ポール、佐山です。 2026 年 5 月 18 日〜2 […]
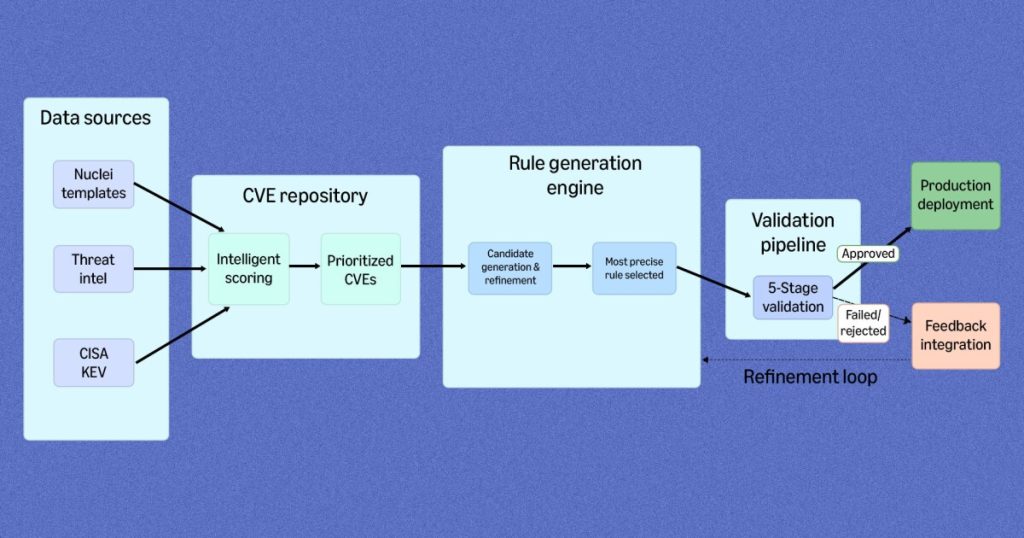
エージェンティック AI でグローバル規模の脆弱性検出を加速
Amazon が開発した RuleForge は、エージェンティック AI を活用して脆弱性検出ルールを自動生成するシステムです。ルール生成エージェントとジャッジモデルを分離するアーキテクチャにより、誤検知を 67% 削減しつつ、従来の手動プロセスと比較して 336% 速くルールを生成・検証できるようになりました。CVE 開示から防御までのギャップを埋め、AWS のお客様のワークロード保護を強化する仕組みを解説します。

Amazon Connect Customer: 中国への発信におけるコンプライアンスのベストプラクティス
Amazon Connect Customer を使用して中国 (国番号 +86) へコンプライアンスに準拠した発信を行うための 5 つのベストプラクティスを紹介します。承認済み DID 番号の設定、禁止番号タイプの排除、レート制限、発信者 ID の設定、番号検証の実装について説明します。
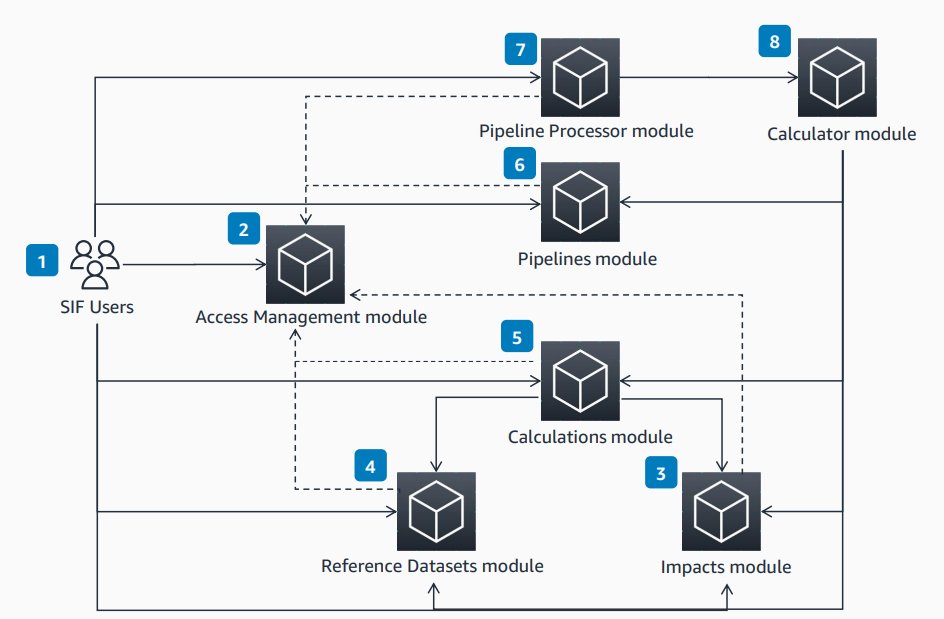
AWS上でSustainability Insights Framework (SIF) を使う方法
AWS Sustainability Insights Framework(SIF)は、組織がAWS上で炭素排出量を自動的に追跡し、気候関連レポートを作成するためのスケーラブルなソフトウェアプラットフォームです。従来の手動プロセスに代わり、モジュラーアーキテクチャを通じてデータ収集・計算・報告を自動化します。人的エラーの削減、動的なスケーリング、進化する規制への適応という3つの利点を提供し、あらゆる規模の組織のサステナビリティ報告を支援します。

Chronos-2 の紹介:単変量予測の先へ — 多変量も共変量もゼロショットで
Chronos-2は、Amazonが開発した時系列予測の基盤モデルです。従来の単変量予測に加え、多変量予測や共変量を活用した予測をゼロショットで実現します。コンテキスト内学習により、追加学習なしで多様な予測タスクに対応し、既存モデルを大幅に上回る性能を達成しました。

AWS Advanced JDBC Wrapper による JDBC クエリキャッシュの自動化
AWS Advanced JDBC Wrapper の Remote Query Cache Plugin を使用して、JDBC クエリ結果を Amazon ElastiCache for Valkey に自動的にキャッシュする方法を紹介します。SQL ヒントを追加するだけで、アプリケーションコードの大幅な変更なしにデータベース負荷を削減しパフォーマンスを向上できます。

Amazon Aurora DSQL の接続: ドライバー、接続文字列、ベストプラクティス
本記事では、Amazon Aurora DSQL への接続方法を解説します。ドライバーの設定、IAM ベースの認証トークン生成、接続プーリング、ライフサイクル管理のベストプラクティスに加え、一般的な接続問題のトラブルシューティングガイドを紹介します。
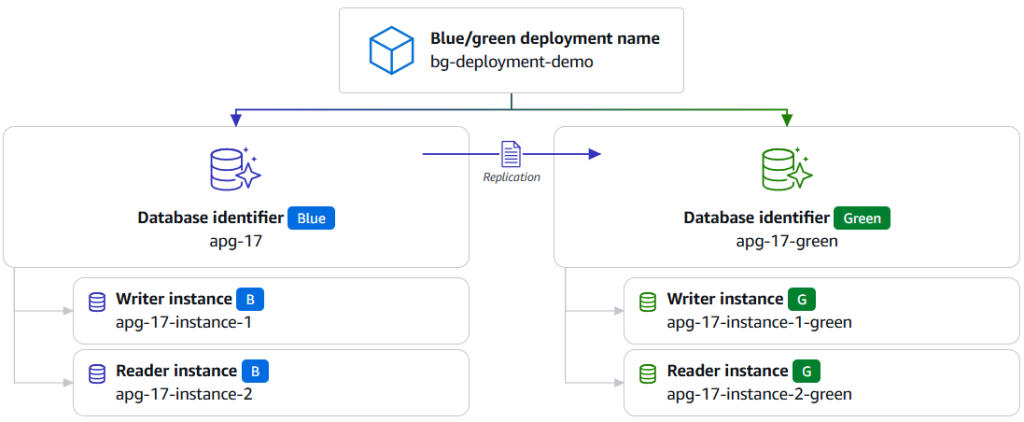
AWS JDBC Driver の Blue/Green デプロイメントプラグインでデータベースメンテナンスのダウンタイムをほぼゼロに
本記事では、AWS JDBC Driver の Blue/Green デプロイメントプラグインを紹介します。このプラグインは、Amazon RDS および Amazon Aurora の Blue/Green デプロイメント切り替え時に、接続ルーティングとトラフィック管理を自動化し、データベースメンテナンスのダウンタイムをほぼゼロにします。プラグインの設定方法とテスト結果を示し、従来の 30 秒超のダウンタイムを約 12 秒の一時停止に短縮できることを実証します。

Sim-to-Real と Real-to-Sim: 高性能な Physical AI を支える原動力
はじめに、物理 AI システム(現実世界で知覚・推論・行動するロボット)は急速に進化しています。この進歩の中心にあるのが Sim-to-Real パイプラインです。しかし、実験室の外でも安定して動作するモデルを構築することは、この分野で最も難しい課題の一つであり続けています。シミュレーションで機能するものと […]