Amazon Web Services ブログ
Category: Storage

Outpost VFX が ビジュアルエフェクト向けに AI モデルのトレーニングを AWS で加速した方法
本記事では、Outpost VFX が AWS インフラを活用してトレーニング速度を 8 倍に向上させ、顔置換ワークフローを刷新した方法、単一 GPU の限界を克服するために実装した技術アーキテクチャ、そして AWS マルチ GPU トレーニングで得られた具体的な成果について紹介します。

【開催報告】AWS Summit Japan 2026 物流業界向けブース展示「スマートグラス×生成AIエージェントで倉庫業務を革新」
こんにちは、ソリューションアーキテクトの田邊です。2026 年 6 月 25 日から 26 日にかけて幕張メッ […]

AWS Weekly Roundup: ワンクリック Lambda セットアッププロンプト、Bedrock での OpenAI GPT-5.6 モデルなど (2026 年 7 月 20 日)
2026 年 7 月 20 日週、私のチームは AWS Korea User Group (AWSKRUG) […]

Amazon OpenSearch Service の書き込み可能なウォームストレージでコストと運用負荷を削減
Amazon OpenSearch Service に、書き込み可能なウォームストレージ (writable warm) が加わりました。UltraWarm では履歴データの更新にホットとの往復が必要でしたが、writable warm ならウォームに直接書き込めます。インフラコストは最大 48% 削減でき、更新も数時間ではなく数秒で完了します。
井村屋グループ様:Amazon SageMaker Canvas を活用したチルド製品の AI 需要予測で、業務工数 90% 削減と熟練者同等の予測精度を実現
本ブログは井村屋グループ株式会社様、株式会社 Hashup 様、Amazon Web Services Jap […]
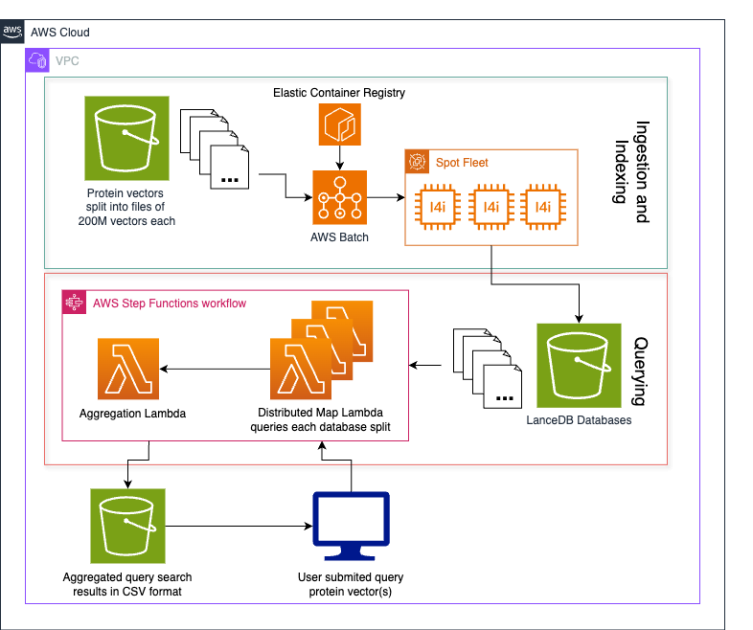
Metagenomi が LanceDB と Amazon S3 で実現した 10 億ベクトル超のスケーラブルな検索基盤
Metagenomi は LanceDB、Amazon S3、AWS Lambda を組み合わせ、35 億件のタンパク質エンベディングを低コストで保存・検索するサーバーレスソリューションを構築しました。データをバケット分割して並列インデックス化し、map-reduce 方式で検索する設計により、常時稼働サーバーなしで数十億ベクトル規模の近似最近傍検索を実現しています。

AWS 週間まとめ:NY Summit の振り返り、ハノイでのローカルゾーン、Bedrock での Grok 4.3、価格引き下げなど(2026年6月22日)
2026 年 6 月 15 日週、AWS Summit New York City では、何千人ものお客様、パ […]
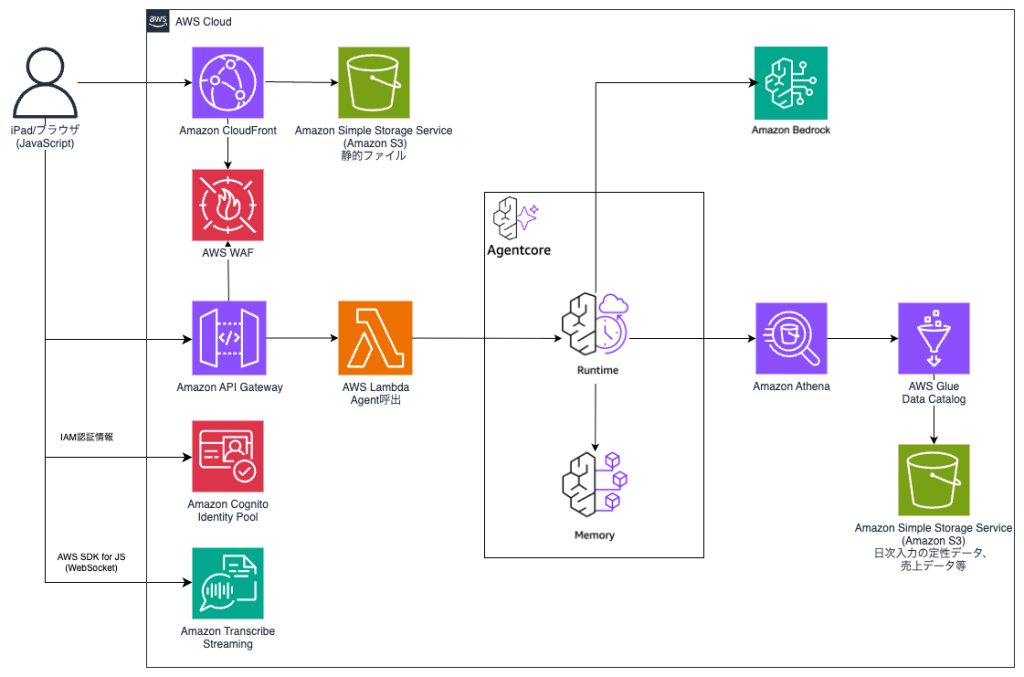
店舗の気づきを本部に届ける AI エージェント SMART のご紹介 — Amazon Bedrock AgentCore × Strands Agents によるユナイテッドアローズでの取り組み
本記事では、AWS サンプルアセットである AI エージェント SMART(Store Manager Agent for Retail Tech) についてのご紹介と、それを活用した株式会社ユナイテッドアローズ(以下、ユナイテッドアローズ)の取り組みについてご紹介します。小売業にとって、店舗の声をどう本部に届けるかは永遠のテーマです。売上数字の裏には、現場スタッフだけが感じている気づきが必ずあります。しかし店舗の日報や週報のフォーマットだけでは、その気づきを届けるのは難しいのが実情です。SMART は、店舗の気づきを AI の力で引き出し言語化して、本部に届けることを支援するために誕生しました。

「フィジカル AI 開発支援プログラム by AWS ジャパン」Community Meetup #1 を開催しました
2026 年 6 月 1 日、アマゾン ウェブ サービス ジャパン合同会社(以下、AWS ジャパン)は、「フィジカル AI 開発支援プログラム by AWS ジャパン」の第 1 回コミュニティイベント「Community Meetup #1」を、 AWS ジャパン 麻布台オフィスにて開催しました。本プログラムは 2026 年 1 月 27 日に発表し、3 月 3 日にキックオフイベントを開催しました。今回の Community Meetup は、約 6 ヶ月間の開発支援期間のなかで、採択企業同士の交流を主な目的として開いた初めてのコミュニティイベントです。

ニューヨークで開催される 2026 年の AWS Summit に関する主要なお知らせ
2026 年 6 月 17 日、ニューヨーク市で開催された AWS Summit では、AWS VP of A […]