Amazon Web Services ブログ
Category: Intermediate (200)
Amazon GuardDuty 調査エージェントのご紹介: オンデマンドの AI を活用した脅威評価
Amazon GuardDuty 調査エージェントのパブリックプレビューを発表しました。AI を活用してセキュリティ検出結果の調査を自動化し、調査時間を数時間から数分に短縮します。リスクレベル、信頼度スコア、MITRE ATT&CK 手法マッピング、推奨アクションを含む構造化された評価を提供します。本記事では、コンソールと AWS CLI による有効化と調査の実行手順、AWS MCP サーバーとの統合、AWS Security Incident Response との使い分けを解説します。

Oracle Database@AWS を読み解く: Oracle ワークロードに最適な選択肢の見極め方
2025 年 7 月に GA となった Oracle Database@AWS (ODB@AWS) が Oracle ワークロードに適しているかを判断する 5 つの質問と、ビジネス・技術・ライセンス面での利点、Amazon RDS for Oracle や EC2 との使い分けを解説します。
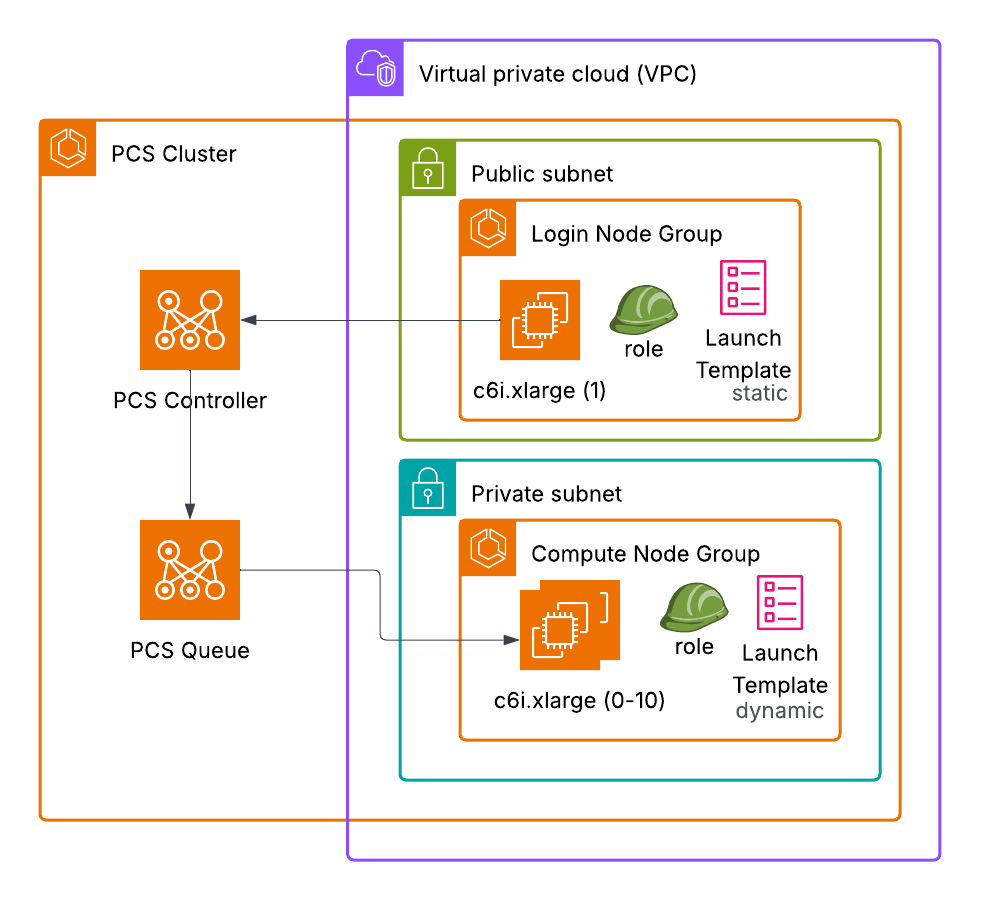
AWS Parallel Computing Service と Kiro CLI で HPC のデプロイを加速する
オンプレミスの HPC 環境からの移行を進める研究チームは、クラウドへのデプロイの複雑さに悩まされることがよく […]

Amazon Redshift RG: Graviton 搭載でより高速、より低コスト
Amazon Redshift は、Graviton プロセッサを搭載した新インスタンス RG の一般提供を開始しました。RG は RA3 と比較して最大 2.2 倍高速なパフォーマンスを 30% 低いコストで実現し、統合ベクトル化データレイクエンジンにより Iceberg クエリで最大 2.4 倍高速化します。本記事では RG の技術的特長とベンチマーク結果を紹介します。

Amazon Redshift のマルチウェアハウス機能強化でアナリティクスをスケール
Amazon Redshift のリモートテーブル DDL の改善、マテリアライズドビューの機能強化、zero-ETL および auto-copy 向けのコンカレンシースケーリング拡張により、大規模なアナリティクスワークロードを効率的にオンボードできるようになりました。金融サービスやゲーム業界の実例を交えて、マルチウェアハウスアーキテクチャの活用方法を紹介します。

Amazon Redshift Serverless と Tableau の統合を最適化する
本記事では、Tableau と Amazon Redshift Serverless の統合を最適化するための戦略を紹介します。データモデルアーキテクチャ、セキュリティ構成、パフォーマンス最適化、コスト管理、クエリ最適化の 5 つの領域について、RPU を最大限に活用しながらサブ秒レベルのインサイトを提供するためのベストプラクティスを解説します。

クラスターアップグレードを安全かつ信頼性高く管理できる Amazon EKS バージョンロールバックを発表
Amazon EKS バージョンロールバックを発表します。これは、クラスター管理者が Amazon Elastic Kubernetes Service (Amazon EKS) クラスターにおける Kubernetes バージョンのアップグレードを安全にロールバックできる新機能です。この機能により、追加のセーフティネットを備えた状態で EKS フリート全体に新しいバージョンのアップグレードを自信を持って展開できるようになりました。

Kiro とともに医療情報システムのガイドライン遵守開発に挑む
医療情報システム開発で避けて通れない数多くの業界ガイドラインに対して、AI 駆動開発でどう立ち向かうか。本記事では、ガイドラインの知識を Agent Skills、開発標準を Agent Steering として Kiro に与え、必要なときに必要な分だけコンテキストを参照させながら、人間が意思決定権を持って協働する「Kiro をチームの一員に育て上げる」アプローチを紹介します。
AWS マネジメントコンソールへのアクセスを想定するネットワークに制限
本ブログでは、企業が規制コンプライアンスのためにコンソールアクセスを企業ネットワークに制限するユースケースを取り上げ、AWS Sign-In のリソースベースポリシーと RCP を使った実装方法を紹介します。リソース許可ステートメントの作成、コンソール認可の有効化、CloudTrail による検証、Console Private Access やデータ境界フレームワークとの統合まで詳しく説明します。

Amazon ElastiCache 向け Valkey 9.1 のお知らせ
本ブログでは、Amazon ElastiCache で利用可能になった Valkey 9.1 の新機能についてご紹介します。再設計された I/O スレッディングによるスループット向上や、小さな文字列・ソート済みセットのメモリ効率改善といった性能強化に加え、データベース単位の ACL によるマルチテナント環境での分離強化、HGETDEL・MSETEX・CLUSTERSCAN などワークフローを簡素化する新コマンド、JSON 形式のログ出力による可観測性向上について学べます。大規模インメモリワークロードのコスト最適化と運用効率化を目指す方におすすめの内容です。