Amazon Web Services ブログ
Category: Management & Governance
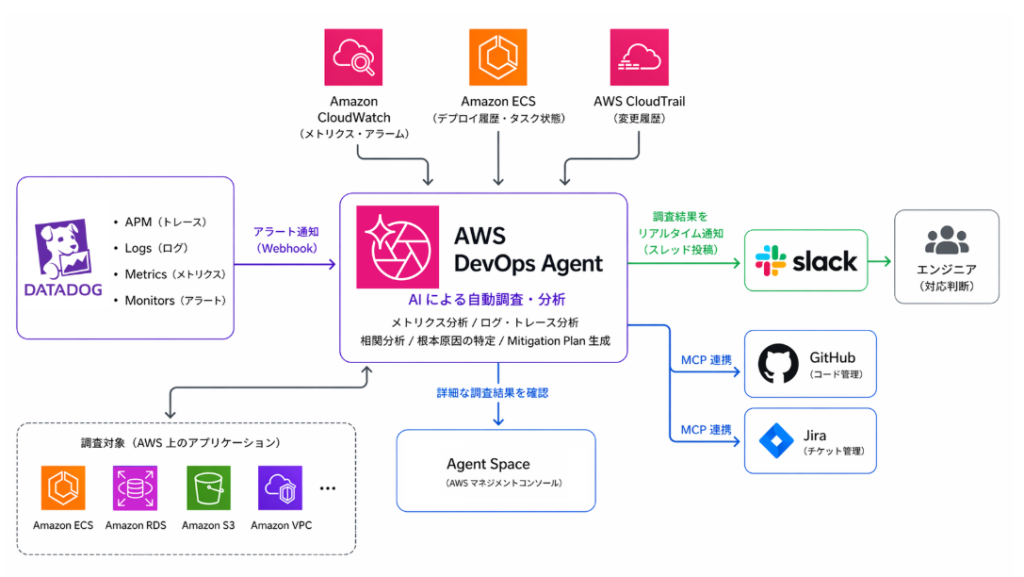
寄稿:弁護士ドットコムにおける AWS DevOps Agent の活用事例 – インシデント対応の自動化と属人化の解消
弁護士ドットコム株式会社は、『「プロフェッショナル・テック」で、次の常識をつくる。』というミッションのもと、国内最大級の法律相談ポータルサイト「弁護士ドットコム」や契約マネジメントプラットフォーム「クラウドサイン」などを運営しています。また、最近ではリーガル特化型 AI エージェント「Legal Brain エージェント」を開発し、AI を活用したリーガルサービスの進化にも取り組んでいます。PRE 部は、これらのサービスを支えるインフラの信頼性と運用効率の向上を担っています。本記事では、AWS DevOps Agent を用いたインシデント対応の自動化と運用組織のあり方の見直しを進めている事例を紹介します。

AWS Summit Japan 2026 に Chaos Kitty が対戦モードを引っさげて 4 回目の登場!
みなさんこんにちは! 猫や犬に癒されるより AI bou (相棒) に助けられる日々を送る Solution […]

2026年1月〜5月の AWS オブザーバビリティ関連リリースまとめ
AWS オブザーバビリティ関連リリースまとめの第1回へようこそ!2026年の最初の5か月間は、AWS オブザーバビリティにとって大きな変革をもたらした期間となり、 Amazon CloudWatch 、 AWS X-Ray 、 Amazon Managed Grafana 、 Amazon Managed Service for Prometheus にまたがって40を超えるリリースが行われました。この期間を特徴づける2つの大きなテーマは、統一された計装標準である OpenTelemetry 対応を強化したことと、オブザーバビリティを誰もが利用できるようにする AI 駆動のオペレーション です。EKS上でコンテナを実行している方も、複数リージョンにまたがるデータベースを管理している方も、AI 支援のワークフローを構築している方も、ここには役立つ情報があります。

AWS Weekly Roundup: AWS での Claude Opus 4.8、Kiro Powers を利用する Aurora MySQL など (2026 年 6 月 1 日)
私の前回の Week in Review の記事では、私が開催している AI-Driven Developme […]

生成 AI を活用した SRE レジリエンスジャーニーを支援する次世代 AWS Resilience Hub のご紹介
2026 年 5 月 28 日、各種機能を大幅に強化した次世代の AWS Resilience Hub を発表 […]

Amazon Quick を使用したエンタープライズ向けパッチ適用・インベントリダッシュボードの構築
このブログは AWS のスペシャリストソリューションアーキテクト Suhail Fouzan、ソリューションア […]
VPC 内のプライベートサービスに AWS DevOps Agent をセキュアに接続する方法
AWS DevOps Agent は24時間365日稼働する運用チームメンバーで、インシデント対応やアプリケーション最適化、SREタスクをAWS・マルチクラウド・オンプレミス問わず担います。MCPツールやインテグレーションで拡張し、社内レジストリやGitHub Enterprise等の内部リソースにもアクセス可能です。しかし多くのサービスはVPC内で稼働しており、パブリックインターネット経由ではアクセスできません。プライベート接続機能を使えば、Agent SpaceとVPC内のサービスをインターネットに公開せずセキュアに接続でき、MCPサーバーやGrafana、Splunk等あらゆるプライベートエンドポイントに対応します。本記事ではその仕組みとセットアップ手順を解説します。

AWS DevOps Agent によるエージェンティック AI を活用した自律的インシデント対応
このブログは、AWS DevOps Agentを使った自律的なインシデント対応について解説します。従来のSREエンジニアは、障害発生時に複数のログやツールから情報を手動で収集し、原因を特定するのに数時間かかっていました。AWS DevOps Agentは、アプリケーショントポロジーの理解、クロスアカウント調査、継続的学習機能を備えた完全マネージド型のAI運用チームメンバーです。6つの主要機能(Context、Control、Convenience、Collaboration、Continuous Learning、Cost Effective)により、単純なLLMラッパーとは異なる本格的な運用支援を実現します。このブログを読むことで、AWS DevOps Agentがどのように運用の複雑性を軽減し、インシデント対応を自動化・高速化するかを理解できます。

AWS DevOps Agent を本番環境にデプロイするためのベストプラクティス
インシデント発生時の根本原因分析は、クラウド運用において最も時間がかかる作業の一つです。AWS DevOps Agent は、自律的な調査能力により平均復旧時間 (MTTR) を数時間から数分に短縮します。本記事では、調査能力と運用効率のバランスを取る Agent Space のセットアップに関するベストプラクティスを紹介します。最適な調査精度を実現するための Agent Space の構成方法、適切なリソースアクセス範囲の決定方法、そして Infrastructure as Code を活用したデプロイの効率化について解説します。

AWS Organizations における不正なアカウント離脱を防止するための重要なセキュリティコントロール
AWS メンバーアカウントが侵害された場合、攻撃者はアカウントを組織から離脱させ、すべてのガバナンスコントロールを無効化する可能性があります。本記事では、サービスコントロールポリシー (SCP)、安全なアカウント移行、ルートアクセスの一元管理機能などの多層的なセキュリティコントロールを使用して、AWS 環境を保護する方法を解説します。