Amazon Web Services ブログ
Category: Amazon SageMaker

Amazon FSx for NetApp ONTAP が Amazon S3 と統合され、シームレスなデータアクセスが可能になりました
2025 年 12 月 2 日、Amazon Simple Storage Service (Amazon S […]

Amazon S3 クライアントを使用した ML トレーニングにおけるデータ読み込みベストプラクティスの適用
この記事では、Amazon S3 汎用バケットから直接データを読み取る ML トレーニングワークロードのスループットを最適化するための実用的な技術と推奨事項を紹介します。ここで説明するデータ読み込み最適化技術の多くは、さまざまなストレージ基盤に広く適用できます。

Amazon Nova Forge の紹介: Nova を使用して独自のフロンティアモデルを構築
組織は、生成 AI の使用をビジネスのあらゆる部分で急速に拡大しています。深い専門知識や特定のビジネスコンテキ […]

AWS Glue Data Catalog での Apache Iceberg テーブルのカタログフェデレーションの紹介
Apache Iceberg は、大規模で堅牢かつ信頼性の高い分析を求める組織にとって、オープンテーブルフォーマットの標準的な選択肢となっています。しかし、企業は異なるカタログシステムを持つ複雑なマルチベンダー環境をますます多く扱うようになっています。マルチベンダー環境で運用する組織にとって、これらのシステム間でデータを管理することは大きな課題となっています。この断片化は、特にアクセス制御とガバナンスに関して、運用上の複雑さを大幅に増加させます。Amazon Redshift、Amazon EMR、Amazon Athena、Amazon SageMaker、AWS Glue などの AWS 分析サービスを使用して AWS Glue Data Catalog 内の Iceberg テーブルを分析しているお客様は、リモートカタログのワークロードでも同じ価格性能を得たいと考えています。これらのリモートカタログを単純に移行または置き換えることは現実的ではなく、チームはシステム間でメタデータを継続的に複製する同期プロセスを実装・維持する必要があり、運用上のオーバーヘッド、コストの増加、データの不整合のリスクが生じます。

Amazon SageMaker AI の新しいサーバーレスカスタマイズにより、モデルのファインチューニングが加速します
2025 年 12 月 3 日、Amazon Nova、 DeepSeek 、 GPT-OSS 、Llama、 […]

Amazon SageMaker HyperPodでのチェックポイントなしかつ弾力的なトレーニングの紹介
2025 年 12 月 3 日、 Amazon SageMaker HyperPod における 2 つの新しい […]
株式会社アプリズムが Amazon SageMaker AI と AWS IoT Core で実現した馬の見守りシステム「aiba」の開発と運用
本ブログは 株式会社アプリズム 様と Amazon Web Services Japan 合同会社が共同で執筆 […]
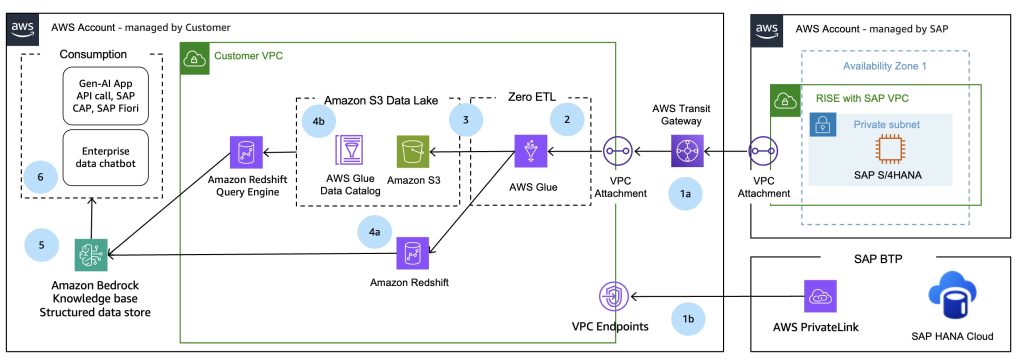
Amazon Bedrock Knowledge BasesでSAPおよびエンタープライズデータから新たな可能性を解き放つ
生成AI(Generative AI)の力とエンタープライズデータインテリジェンスを組み合わせた新しいソリューションを見てみましょう。この記事では、Amazon Bedrock Knowledge Basesが組織のSAPおよびエンタープライズデータの活用方法をどのように革新し、イノベーション、効率性、戦略的意思決定のための新たな可能性を創出しているかを探ります。自然言語クエリから自動化されたドキュメント処理、インテリジェントなインサイト生成まで、このソリューションが企業のSAP投資をAI時代の戦略的資産に変革する方法をご紹介します。

東京海上日動システムズ株式会社様の AWS 生成 AI 事例:全社生成 AI 実行基盤とエンタープライズ RAG システムの構築
東京海上日動システムズ様における全社向け生成 AI 実行基盤の構築事例を紹介しています。マルチアカウント構成による基盤設計の考え方や、RAG システムにおける技術選定と実装の工夫、コスト最適化の取り組みなど、企業での生成 AI 活用を検討される際の参考となる内容です。

Apache Iceberg V3 の deletion vectors と row lineage でデータレイク操作を高速化する
Apache Iceberg V3 では deletion vectors と row lineage が導入されました。AWS は Amazon EMR、AWS Glue、Amazon SageMaker、Amazon S3 Tables、AWS Glue Data Catalog でこの機能を提供しています。本記事では、新機能の概要、業界横断のユースケース、AWS サービスでの実装方法を紹介します。