Amazon Web Services ブログ
Category: AWS re:Invent

AI を活用したゲーム制作: 静的なコンセプトからインタラクティブなプロトタイプへ
AI を活用することで、ゲーム開発の初期段階でコンセプトをインタラクティブにし、数分でプレイ可能なプロトタイプを作成できます。AWS re:Invent 2025 で紹介する Agentic Arcade は、マルチエージェントオーケストレーション、プログラマティックアセット生成、セマンティック検索を組み合わせ、開発サイクルの早い段階で創造的な方向性を探索し検証する方法を示します。

Amazon Connect アップデートまとめ – 2025年11・12月合併号
新年あけましておめでとうございます。Amazon Connect ソリューションアーキテクトの坂田です。 20 […]

Amazon Bedrock は、新しい Mistral Large 3 モデルと Ministral 3 モデルを含む 18 のフルマネージドオープンウェイトモデルを追加します
2025 年 12 月 2 日、Google、Moonshot AI、MiniMax AI、Mistral A […]

AWS データベースのデータベース Savings Plans の紹介
Amazon Web Services (AWS) が Savings Plans を導入して以来、お客様はア […]

サーバーレス MLflow で Amazon SageMaker AI を使用して AI 開発を加速
2024 年 6 月に MLflow を搭載した Amazon SageMaker AI を発表して以来、弊社 […]

デジタル庁様がAWS re:Invent 2025 で登壇「ガバメントクラウドで実現した俊敏性とコンプライアンスのバランス」
米国ラスベガスで2025年12月1日-5日に開催された AWS re:Invent 2025 では、デジタル庁 […]

新しく強化された AWS サポートプランでは、専門家によるガイダンスに AI 機能が追加されました
2025 年 12 月 2 日、AWS サポートがお客様の支援方法を根本から転換し、事後対応型の問題解決から事 […]

AWS Lambda Durable Functions を使用して複数ステップのアプリケーションと AI ワークフローを構築
現代のアプリケーションでは、複数段階の支払い処理、AI エージェントのオーケストレーション、または人間の決定を […]

Amazon GuardDuty が Amazon EC2 と Amazon ECS に Extended Threat Detection 機能を追加
2025 年 12 月 2 日、Amazon Elastic Compute Cloud (Amazon EC […]
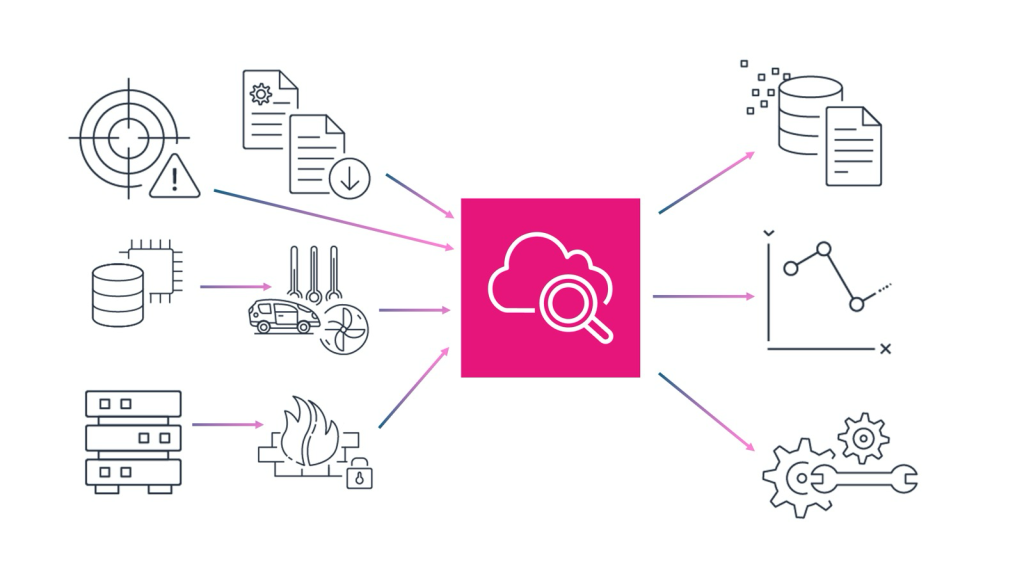
Amazon CloudWatch は、運用、セキュリティ、コンプライアンスのための統合データ管理と分析を導入します
2025 年 12 月 2 日、Amazon CloudWatch の機能を拡張して、運用、セキュリティ、コン […]