Amazon Web Services ブログ
Category: Amazon Redshift

AWS Weekly Roundup: Amazon Bedrock での NVIDIA Nemotron 3 Super、Nova Forge SDK、Amazon Corretto 26 など (2026 年 3 月 23 日)
こんにちは! 今回初めて AWS Weekly Roundup を担当する Daniel Abib です。私は […]
寄稿:東京証券取引所が挑む膨大な取引データの処理 – AWS 活用で実現した次世代データ分析基盤
本稿は、株式会社日本取引所グループ(以下「JPX」)傘下の株式会社東京証券取引所(以下「東証」)による「膨大な […]

人に依存しないCRMによりEC事業者のLTV最大化を実現 Amazon Bedrock AgentCoreを活用したAIオートパイロット型CRM開発事例
株式会社ダイレクトマーケティングエージェンシー(以下、DMA)は、2006年の創業以来、ECビジネス支援エー […]
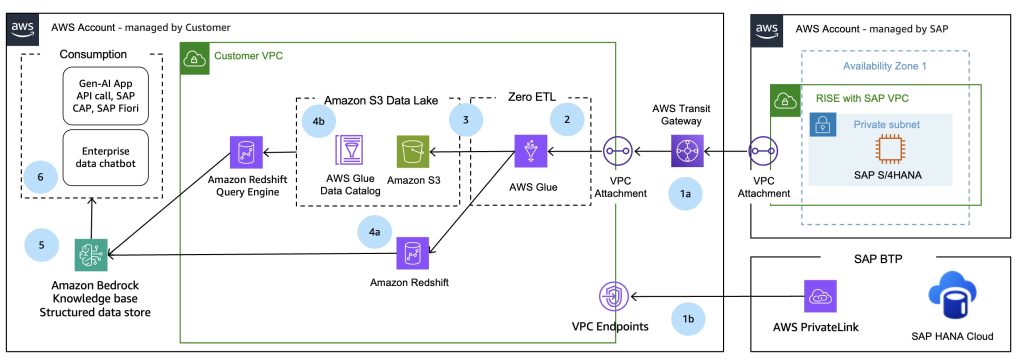
Amazon Bedrock Knowledge BasesでSAPおよびエンタープライズデータから新たな可能性を解き放つ
生成AI(Generative AI)の力とエンタープライズデータインテリジェンスを組み合わせた新しいソリューションを見てみましょう。この記事では、Amazon Bedrock Knowledge Basesが組織のSAPおよびエンタープライズデータの活用方法をどのように革新し、イノベーション、効率性、戦略的意思決定のための新たな可能性を創出しているかを探ります。自然言語クエリから自動化されたドキュメント処理、インテリジェントなインサイト生成まで、このソリューションが企業のSAP投資をAI時代の戦略的資産に変革する方法をご紹介します。

AWS の Sales Concierge で製薬企業の営業生産性と効率を飛躍的に向上
このブログは、“Boost sales team productivity and effecti […]

ANA グループ 4 万人に展開するデータマネジメント基盤の裏側
はじめに 本ブログは、全日本空輸株式会社と Amazon Web Services Japan が共同で執筆し […]

Amazon RDS for MySQL と Amazon Redshift のゼロ ETL 統合が一般公開され、ほぼリアルタイムの分析が可能に
ゼロ ETL 統合では、複数のアプリケーションやデータソースにわたるデータを統合し、総体的なインサイトを取得し […]

Amazon Redshift との Amazon Aurora MySQL ゼロ ETL 統合が一般公開されました
「データは、あらゆるアプリケーション、プロセス、ビジネス上の意思決定の中心にあります」と、AWS のデータベー […]

2023 年 3 月の AWS Black Belt オンラインセミナー資料及び動画公開のご案内
2023 年 3 月に公開された AWS Black Belt オンラインセミナーの資料及び動画についてご案内させて頂きます。
動画はオンデマンドでご視聴いただけます。

【寄稿】Amazon Redshift Serverlessへのセキュアなアクセス
この投稿はアクセンチュア株式会社 テクノロジーコンサルティング本部所属のマネージャー 竹内 誠一 氏に、Ama […]