Amazon Web Services ブログ
Amazon Redshift の新機能 — Kinesis データストリームのストリーミングインジェスト、および Managed Streaming for Apache Kafka の一般提供について
10 年前、私が AWS に入社してからわずか数か月後に、Amazon Redshift はローンチされました。長年にわたり、パフォーマンスを向上させ、使いやすくするために多くの機能が追加されてきました。Amazon Redshift では、SQL を使用して、データウェアハウス、運用データベース、データレイクにわたって構造化データと半構造化データを分析できるようになりました。最近では、データウェアハウスインフラストラクチャを管理しなくても簡単に分析を実行およびスケーリングできるように、Amazon Redshift サーバーレスが一般公開されました。
リアルタイムアプリケーションからのデータを可能な限り迅速に処理するために、お客様は Amazon Kinesis や Amazon Managed Streaming for Apache Kafka などのストリーミングエンジンを採用しています。これまでは、ストリーミングデータを Amazon Redshift データベースにロードするには、ロードする前に Amazon Simple Storage Service (Amazon S3) でデータをステージングするプロセスを設定する必要がありました。その場合、データ量にもよりますが、1 分以上の遅延が発生します。
本日、Amazon Redshift Streaming Ingestion の一般提供を開始したことをお知らせします。この新機能により、Amazon Redshift では Amazon Kinesis Data Streams と Amazon MSK から 1 秒間に数百メガバイトのデータを Amazon Redshift のマテリアライズドビューにネイティブに取り込み、数秒でクエリを実行することができます。

ストリーミングインジェストでは、マテリアライズドビューを使用してクエリパフォーマンスを最適化できるというメリットがあり、Amazon Redshift を運用分析やリアルタイムダッシュボードのデータソースとしてより効率的に使用できます。ストリーミングインジェストのもう 1 つの興味深い使用例は、ゲーマーからのリアルタイムのデータを分析して、ゲーム体験を最適化することです。この新しい統合により、IoT デバイスの分析、クリックストリーム分析、アプリケーション監視、不正検知、ライブリーダーボードの実装も簡単になります。
ここからは、実際にどのように機能するのかを見ていきましょう。
Amazon Redshift ストリーミングインジェストを設定する
Amazon Redshift のストリーミングインジェストでは、権限の管理とは別に、Amazon Redshift 内の SQL ですべてを設定することが可能です。これは、AWS マネジメントコンソールにアクセスできないビジネスユーザーや、AWS サービス間の統合を設定する専門知識がないビジネスユーザーにとって特に便利です。
ストリーミングインジェストは、次の 3 つの手順で設定できます。
- AWS Identity and Access Management (IAM) ロールを作成または更新して、使用するストリーミングプラットフォーム (Kinesis データストリームまたは Amazon MSK) へのアクセスを許可します。IAM ロールには、Amazon Redshift がそのロールを引き継ぐことを許可する信頼ポリシーが必要ですので、注意してください。
- ストリーミングサービスに接続するための外部スキーマを作成します。
- 外部スキーマのストリーミングオブジェクト (Kinesis データストリームまたは Kafka トピック) を参照するマテリアライズドビューを作成します。
その後、マテリアライズドビューにクエリを実行して、ストリームのデータを分析ワークロードで使用することができます。ストリーミングインジェストは、Amazon Redshift でプロビジョニングされたクラスターと新しいサーバーレスオプションで機能します。最大限にシンプルにするために、このウォークスルーでは Amazon Redshift サーバーレスを使用します。
環境を準備するには、Kinesis データストリームが必要です。Kinesis コンソールのナビゲーションペインで [データストリーム] を選択し、次に [データストリームの作成] を選択します。データストリーム名には my-input-stream を使用し、他のすべてのオプションはデフォルト値のままにします。数秒後、Kinesis データストリームの準備が整います。デフォルトでは、オンデマンドキャパシティモードを使用していますので、注意してください。開発環境またはテスト環境では、1 つのシャードでプロビジョニングされたキャパシティモードを選択してコストを最適化することができます。
ここで、Amazon Redshift が my-input-stream Kinesis データストリームにアクセスできるように、IAM ロールを作成します。IAM コンソールで、次のポリシーを使用してロールを作成します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"kinesis:DescribeStreamSummary",
"kinesis:GetShardIterator",
"kinesis:GetRecords",
"kinesis:DescribeStream"
],
"Resource": "arn:aws:kinesis:*:123412341234:stream/my-input-stream"
},
{
"Effect": "Allow",
"Action": [
"kinesis:ListStreams",
"kinesis:ListShards"
],
"Resource": "*"
}
]
}Amazon Redshift がそのロールを引き継ぐことを許可するために、以下の信頼ポリシーを使用します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "redshift.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}Amazon Redshift コンソールでは、ナビゲーションペインから Redshift サーバーレスを選択し、このブログ記事で行ったのと同じように、新しいワークグループと namespace を作成します。Namespace を作成する際は、権限セクションのドロップダウンメニューから [IAM ロールの関連付け] を選択します。次に、作成したロールを選択します。この選択でロールが表示されるのは、信頼ポリシーで Amazon Redshift がロールを引き受けることが許可されている場合のみですので、注意してください。その後、デフォルトのオプションを使用して namespace の作成を完了します。数分後、サーバーレスデータベースが使用可能になります。
Amazon Redshift コンソールのナビゲーションペインで [クエリエディタ v2] を選択します。リソースのリストから選択して、新しいサーバーレスデータベースに接続します。これで、SQL を使用してストリーミングインジェストを設定できます。まず、ストリーミングサービスにマップする外部スキーマを作成します。ここではシミュレートされた IoT データを例として使用するので、外部スキーマセンサーと呼びます。
CREATE EXTERNAL SCHEMA sensors
FROM KINESIS
IAM_ROLE 'arn:aws:iam::123412341234:role/redshift-streaming-ingestion';ストリーム内のデータにアクセスするために、ストリームからデータを選択するマテリアライズドビューを作成します。一般に、マテリアライズドビューには、クエリの結果に基づいて事前に計算された結果セットが含まれます。この場合、クエリはストリームから読み取っており、Amazon Redshift がストリームのコンシューマーです。
ストリーミングデータは JSON データとしてインジェストされるため、次の 2 つの選択肢があります。
- すべての JSON データを 1 つの列に残し、Amazon Redshift の機能を使用して半構造化データをクエリします。
- JSON プロパティを個別の列に抽出します。
両方のオプションの長所と短所を見てみましょう。
SELECT ステートメント内の approximate_arrival_timestamp、partition_key、shard_id、および sequence_number 列は Kinesis データストリームによって提供されます。ストリームからのレコードは kinesis_data 列にあります。refresh_time 列は Amazon Redshift によって提供されています。
JSON データを sensor_data マテリアライズドビューの 1 つの列に残すには、JSON_PARSE 関数を使用します。
CREATE MATERIALIZED VIEW sensor_data AUTO REFRESH YES AS
SELECT approximate_arrival_timestamp,
partition_key,
shard_id,
sequence_number,
refresh_time,
JSON_PARSE(kinesis_data, 'utf-8') as payload
FROM sensors."my-input-stream";
CREATE MATERIALIZED VIEW sensor_data AUTO REFRESH YES AS
SELECT approximate_arrival_timestamp,
partition_key,
shard_id,
sequence_number,
refresh_time,
JSON_PARSE(kinesis_data) as payload
FROM sensors."my-input-stream";AUTO REFRESH YES パラメータを使用したため、ストリームに新しいデータがあると、マテリアライズドビューの内容が自動的に更新されます。
JSON プロパティを sensor_data_extract マテリアライズドビューの別々の列に抽出するには、JSON_EXTRACT_PATH_TEXT 関数を使用します。
CREATE MATERIALIZED VIEW sensor_data_extract AUTO REFRESH YES AS
SELECT approximate_arrival_timestamp,
partition_key,
shard_id,
sequence_number,
refresh_time,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'sensor_id')::VARCHAR(8) as sensor_id,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'current_temperature')::DECIMAL(10,2) as current_temperature,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'status')::VARCHAR(8) as status,
JSON_EXTRACT_PATH_TEXT(FROM_VARBYTE(kinesis_data, 'utf-8'),'event_time')::CHARACTER(26) as event_time
FROM sensors."my-input-stream";Kinesis データストリームへのデータの読み込み
my-input-stream Kinesis Data Stream にデータをインプットするために、IoT センサーからのデータをシミュレートする以下の random_data_generator.py Python スクリプトを使用しています。
import datetime
import json
import random
import boto3
STREAM_NAME = "my-input-stream"
def get_random_data():
current_temperature = round(10 + random.random() * 170, 2)
if current_temperature > 160:
status = "ERROR"
elif current_temperature > 140 or random.randrange(1, 100) > 80:
status = random.choice(["WARNING","ERROR"])
else:
status = "OK"
return {
'sensor_id': random.randrange(1, 100),
'current_temperature': current_temperature,
'status': status,
'event_time': datetime.datetime.now().isoformat()
}
def send_data(stream_name, kinesis_client):
while True:
data = get_random_data()
partition_key = str(data["sensor_id"])
print(data)
kinesis_client.put_record(
StreamName=stream_name,
Data=json.dumps(data),
PartitionKey=partition_key)
if __name__ == '__main__':
kinesis_client = boto3.client('kinesis')
send_data(STREAM_NAME, kinesis_client)スクリプトを起動して、ストリームに入れられているレコードを確認します。JSON 構文を使用し、ランダムなデータを含んでいます。
Amazon Redshift からのストリーミングデータのクエリ
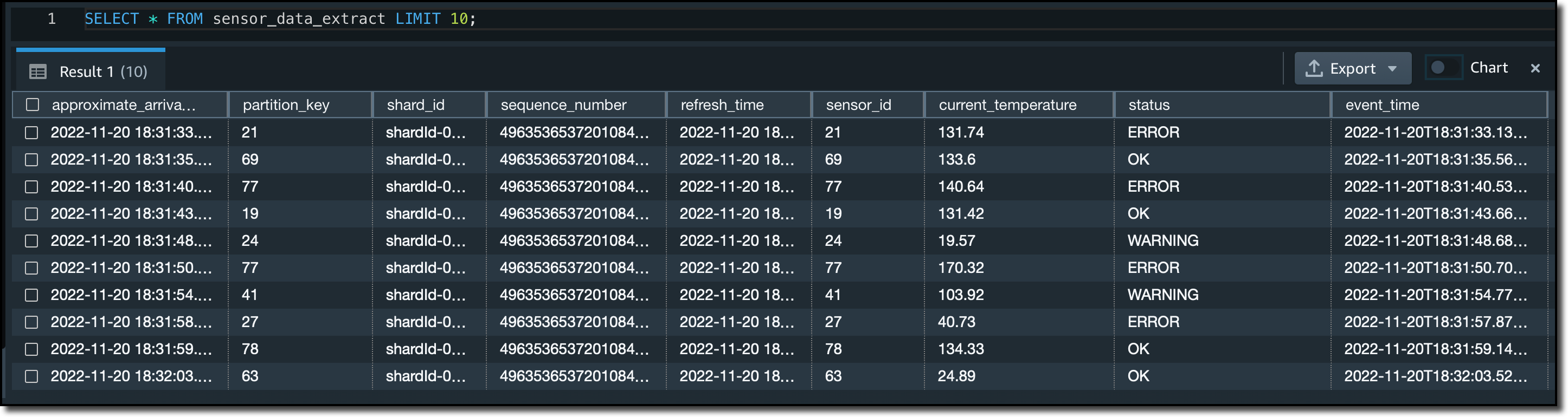
2 つのマテリアライズドビューを比較するために、それぞれから最初の 10 行を選択します。
sensor_dataマテリアライズドビューでは、ストリーム内の JSON データはペイロード列にあります。Amazon Redshift の JSON 関数を使用して、JSON 形式で保存されているデータにアクセスできます。
sensor_data_extractマテリアライズドビューでは、ストリーム内の JSON データが、sensor_id、current_temperature、status、およびevent_timeなどのさまざまな列に抽出されています。

これで、これらのビューのデータを、データウェアハウス、運用データベース、データレイク内のデータとともに、分析ワークロードで使用することができます。これらのビューのデータを Redshift ML と一緒に使用して、機械学習モデルをトレーニングしたり、予測分析を使用したりできます。マテリアライズドビューはインクリメンタル更新をサポートしているため、Amazon Redshift を Amazon Managed Grafana のデータソースとして使用するなど、これらのビューのデータはダッシュボードのデータソースとして効率的に使用できます。
可用性と料金
Kinesis データストリーム用 Amazon Redshift ストリーミングインジェストと Managed Streaming for Apache Kafka は、現在、すべての商用 AWS リージョンで一般でご利用いただけます。
Amazon Redshift ストリーミングインジェストを使用するための追加コストはありません。詳細については、「Amazon Redshift の料金」を参照してください。
データウェアハウスやデータレイクで低レイテンシーのストリーミングデータを使用するのがこれまでになく簡単になりました。この新機能で何を構築したか教えてください!
– Danilo
原文はこちらです。