Amazon Web Services ブログ
Category: Compute

Oracle Database@AWS を読み解く: Oracle ワークロードに最適な選択肢の見極め方
2025 年 7 月に GA となった Oracle Database@AWS (ODB@AWS) が Oracle ワークロードに適しているかを判断する 5 つの質問と、ビジネス・技術・ライセンス面での利点、Amazon RDS for Oracle や EC2 との使い分けを解説します。

AIで変える鉄道保全と、「クローズド」を読み解くクラウド設計 — AWS Summit Japan 2026 展示ブース開催報告
2026年6月25日〜26日、幕張メッセで開催された AWS Summit Japan 2026 にて、AWS […]

AWS Weekly Roundup: AWS Builder Center 1 周年、セキュリティハブにおけるネットワークスキャン、Loom for AWS など (2026 年 7 月 13 日)
AWS Builder Center は 2026年 7 月 6 日週、提供開始から 1 周年を迎えました。2 […]

ハイテクインターが Amazon Rekognition と Graviton プロセッサで実現した富山市の人流観測プラットフォーム
本ブログは ハイテクインター株式会社 様と Amazon Web Services Japan 合同会社が共同 […]
AWS Transform for migrations が 13 言語のローカライズに対応
AWS Transform for migrations が 13 言語のローカライズに対応しました。移行チームはコンソールの設定で表示言語を切り替えることができ、会話型インターフェースやジョブプランなどのマイグレーションワークフロー全体を母国語で利用できるようになりました。

【開催報告 & 資料公開】IT 基盤の環境変化に対応する AWS マイグレーション
こんにちは。アマゾン ウェブ サービス ジャパン合同会社 パートナーソリューションアーキテクトの深井 宣之です […]
井村屋グループ様:Amazon SageMaker Canvas を活用したチルド製品の AI 需要予測で、業務工数 90% 削減と熟練者同等の予測精度を実現
本ブログは井村屋グループ株式会社様、株式会社 Hashup 様、Amazon Web Services Jap […]

AWS Weekly Roundup: AWS での Claude Sonnet 5、AI エージェント向けの Amazon WorkSpaces、AWS サービスの可用性アップデートなど (2026 年 7 月 6 日)
数回前の号で、スタートアップと仕事をすることがどれほど活力になるかについて書きました。2026 年 6 月 2 […]

Amazon EVS への VCF 9.1 エンドツーエンド自動化デプロイ
Amazon EVS のセルフデプロイモードで VCF 9.1 を自動デプロイする 3 フェーズの自動化ツールキットを解説します。Terraform で AWS 基盤を構築し、Python (boto3) で EVS 環境とベアメタルホストをプロビジョニングし、VCF Python SDK で VCF bringup から NSX Edge Cluster 設定までを完全自動化します。
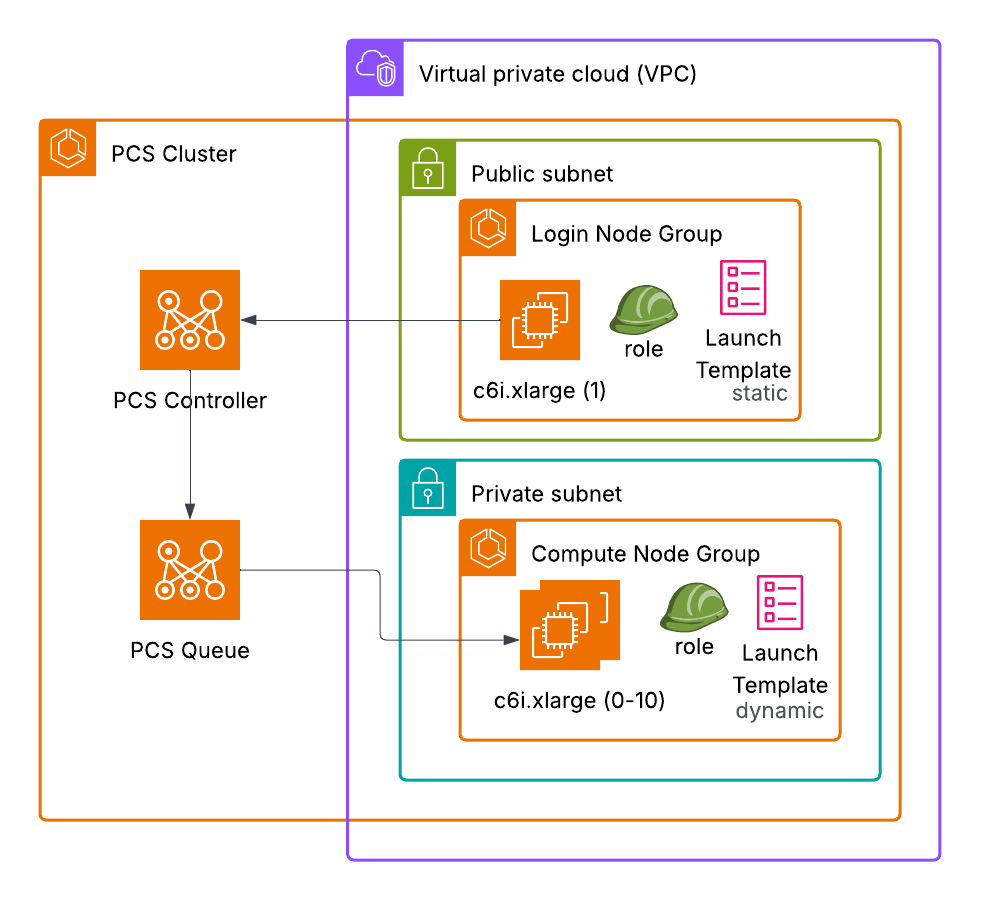
AWS Parallel Computing Service と Kiro CLI で HPC のデプロイを加速する
オンプレミスの HPC 環境からの移行を進める研究チームは、クラウドへのデプロイの複雑さに悩まされることがよく […]