Amazon Web Services ブログ
Category: Containers

[資料公開 & 開催報告] 初学者向けセミナー「これから始める AWS のコンテナサービス活用」を開催しました
2025年4月14日(火)にコンテナサービスの基礎的な内容を扱うウェビナー「これから始める AWS のコンテナサービス活用」を開催しました。本セミナーでは、なぜコンテナが必要なのか、AWS コンテナサービスのラインナップや使い分けといった基礎的な内容から、生成 AI を活用したコンテナ環境の構築・運用や ECS/EKS の新機能のご紹介まで幅広くお届けし、170名の方々にご登録いただき、131名の方々に当日ご参加いただきました。

Amazon EKS のゼロオペレーターアクセス設計を独立した第三者機関が裏付け
Amazon EKS のゼロオペレーターアクセス設計について、独立した第三者機関である NCC Group による検証結果を発表しました。この検証により、AWS 担当者がマネージド Kubernetes コントロールプレーン内の顧客コンテンツにアクセスする技術的手段が存在しないことが確認されました。AWS Nitro System ベースのコンフィデンシャルコンピューティング、限定的な操作のみ可能な管理 API、複数者による変更承認プロセス、エンドツーエンドの暗号化により、最も厳格な規制要件やデジタル主権要件を満たすセキュリティを提供します。

Amazon ECS Express Mode を使用して、インフラストラクチャを複雑化することなく、本番環境に対応したアプリケーションを構築
コンテナ化されたアプリケーションを本番環境にデプロイするには、ロードバランサー、自動スケーリングポリシー、ネッ […]

Deep Dive: Amazon ECS マネージドインスタンスのプロビジョニングと最適化
Amazon Elastic Container Service (Amazon ECS) マネージドインスタンスは、完全マネージド型のコンピューティングオプションで、インフラストラクチャ管理のオーバーヘッドを排除しながら、Amazon Elastic Compute Cloud (Amazon EC2) の幅広い機能にアクセスできます。これには、インスタンスタイプの選択、予約済み容量へのアクセス、高度なセキュリティと監視設定の活用などの柔軟性が含まれます。ECS マネージドインスタンスは Amazon Web Service (AWS) にオペレーションを委託することでお客様の迅速な開始を支援します。総所有コストを削減し、チームがイノベーションをもたらすアプリケーションの構築に専念できるようします。

株式会社タイミー様の Amazon EKS 活用事例: Amazon EKS Auto Mode × Actions Runner Controllerで実現するGitHub Actions Self-hosted Runner基盤 〜柔軟なスケーリングとセキュリティ強化を両立〜
株式会社タイミーは、「働きたい時間」と「働いてほしい時間」をマッチングするスキマバイトサービスを提供しています。
私たちは、Amazon EKS Auto Mode (EKS Auto Mode) × Actions Runner Controller (ARC) を活用し、コスト・パフォーマンス・運用性のバランスを兼ね備えた Self-hosted Runner 基盤を構築しました。
本記事では、その背景と設計方針、導入時に直面した課題と解決への取り組み、導入によって得られた効果、そして今後の展望について紹介します。
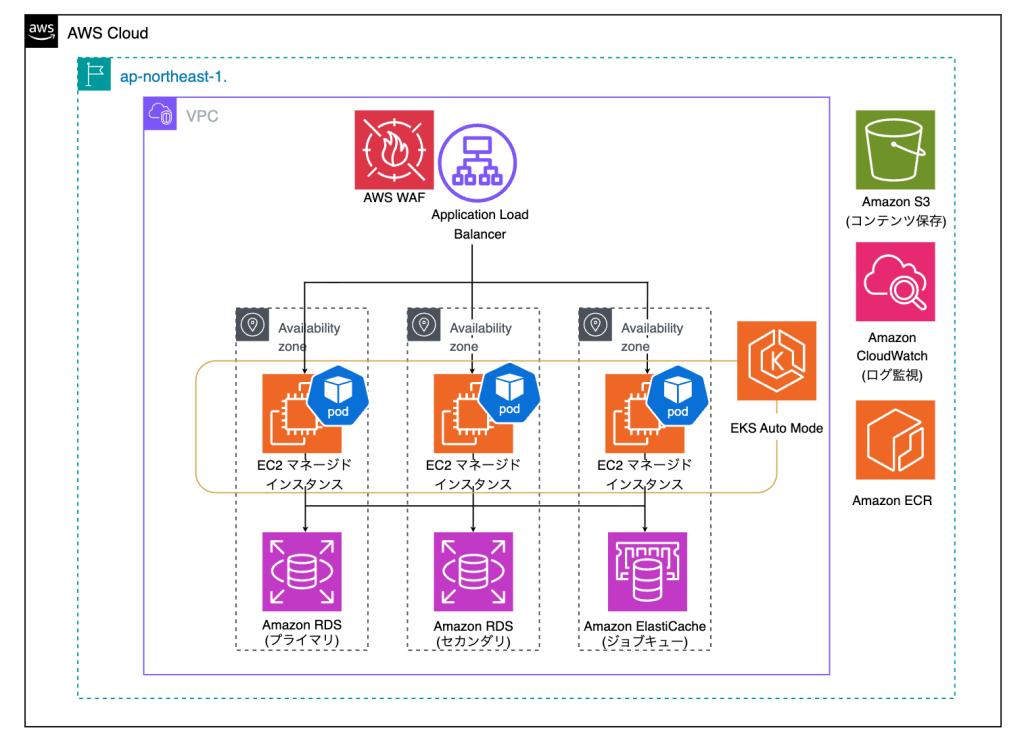
株式会社ギフティ様「giftee Reward Suite」における Amazon EKS Auto Mode の導入事例のご紹介
株式会社ギフティは「giftee Reward Suite」というキャンペーン基盤サービスを提供しており、本稿ではそのインフラ構築事例を紹介しました。同社は Amazon EKS Auto Mode を採用することで、Kubernetes クラスタ管理の簡素化、ノード管理の効率化、セキュリティの向上などの効果が挙げられ、導入当時の検討と課題も併せてご紹介します。
Amazon ECS の新しい組み込みブルー/グリーンデプロイを使用して、安全なソフトウェアリリースを加速
コンテナは開発チームがアプリケーションをパッケージ化およびデプロイする方法に革命をもたらしましたが、これらのチ […]

【開催報告 & 資料公開】Amazon EKS Auto Mode で Kubernetes の運用をシンプルにする
2025 年 5 月 29 日に「Amazon EKS Auto Mode で Kubernetes の運用をシンプルにする」というオンラインセミナーを開催しました。
本セミナーでは、Amazon EKS の新機能 Amazon EKS Auto Mode を掘り下げ、Kubernetes の運用がどのようにシンプルになるのかを紹介しました。また、実践的な内容として、EKS Auto Mode 利用時のノードの自動更新や EKS Auto Mode への移行方法などについても詳しく解説しました。

Amazon ECR イメージを実行中のコンテナにマッピングすることでコンテナのセキュリティを強化する Amazon Inspector
コンテナワークロードを実行するときは、ソフトウェア脆弱性がリソースのセキュリティリスクをどのように引き起こすか […]

AWS で GitHub Actions を使用してマルチアーキテクチャコンテナをビルドしよう
コンピューティング環境が進化するにつれ、さまざまなアーキテクチャをサポートすることが求められるようになっています。 こうした動きは、多様なハードウェアプラットフォームにおける柔軟性、効率性、パフォーマンス最適化のニーズから生まれています。 その結果、開発者や組織にとってマルチアーキテクチャに対応したコンテナイメージを構築することがますます重要になっています。この記事では GitHub Actionsおよび AWS CodeBuild を使用して、AWS 上で x86 用と AWS Graviton ベースのコンピューティング環境用の両方のネイティブコンテナイメージをビルドするソリューションをご紹介します。