Amazon Web Services ブログ
Category: Database

Oracle から Amazon Aurora DSQL へのデータ移行
AWS DMS、Amazon S3、AWS Glue、AWS Step Functions を使って、Oracle から Amazon Aurora DSQL へデータを移行する手順を解説します。自動化されたコスト効率の高い移行パイプラインを構築し、Amazon Aurora DSQL のサーバーレスアーキテクチャ特有の課題に対応します。

Amazon DynamoDB グローバルテーブルのベストプラクティス – パート 1: 運用準備
あなたがグローバルな e コマースプラットフォームを運営していると想像してみてください。北米、ヨーロッパ、アジ […]

Amazon DynamoDB グローバルテーブルのベストプラクティス – パート 3: AWS Fault Injection Service によるリージョナルレジリエンスの検証
この投稿は、Amazon DynamoDB グローバルテーブルのベストプラクティスに関するシリーズのパート 3 […]
Amazon DynamoDB グローバルテーブルのベストプラクティス – Part 2: フェイルオーバー戦略
このシリーズの パート 1 では、Amazon DynamoDB グローバルテーブルによるリージョナルレジリエ […]

AWS Weekly Roundup: BYOM for Amazon RDS for SQL Server、AWS IoT Device SDK for Swift など (2026 年 6 月 8 日)
2026 年 6 月 8 日週、AWS IoT Device SDK for Swift が一般公開されました […]

Amazon ElastiCache for Valkey の耐久性機能のお知らせ
本ブログでは、Amazon ElastiCache for Valkey の新機能である耐久性(Durability)についてご紹介します。この機能により、ElastiCache をキャッシュだけでなく永続的なデータストアとしても利用できるようになります。同期書き込みではデータ損失ゼロを実現し、非同期書き込みではマイクロ秒の書き込みレイテンシーを維持しながら最大10秒のデータ損失リスクに抑えます。Multi-AZ トランザクションログを使用したアーキテクチャ、パフォーマンス測定結果、AWS CLI を使った具体的な設定方法まで詳しく解説します。

Amazon Auroraにおけるバックアップの仕組みを理解する
Amazon Aurora のバックアップアーキテクチャの内部メカニズム、Amazon RDS バックアップとの違い、CloudWatch メトリクスによる監視方法を解説します。ワークロードパターンと保持期間がバックアップコストに与える影響をシナリオで示し、クロスリージョンバックアップの選択肢とストレージ消費量の最適化プラクティスを紹介します。
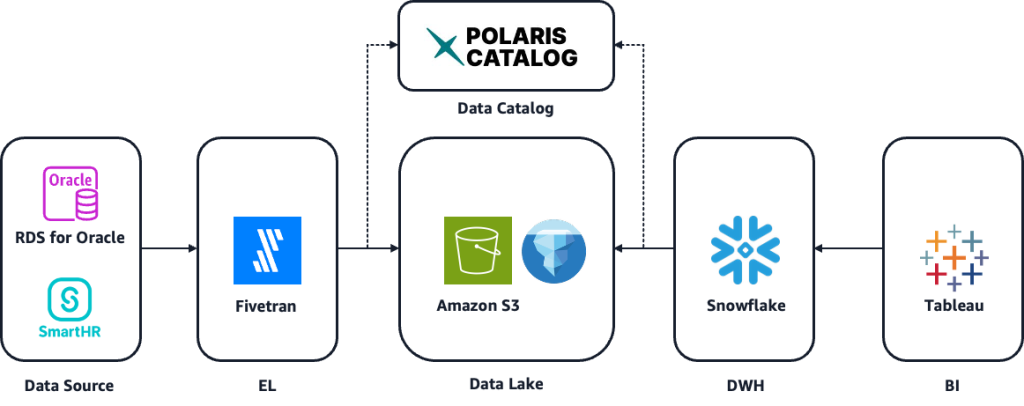
Fivetran の CDC 機能で実現するラーメン山岡家の Iceberg on AWS データパイプライン
ラーメンチェーン「山岡家」を展開する株式会社丸千代山岡家が、Fivetran の CDC(Change Data Capture)機能を活用して Amazon RDS for Oracle から Amazon S3 上の Apache Iceberg テーブルへのデータ同期を実現した事例をご紹介します。アーキテクチャの検討プロセスや Fivetran 採用の理由、約 5 分のデータ反映、月あたりの運用工数を 6 日から 0.5 日に削減、PoC から本番稼働まで約 1 ヶ月という短期導入といった導入効果を解説します。

サーバーレス関連の見逃し情報 2025 年第 4 四半期
お知らせ 2026年7月からオンラインでサーバーレスに関するワークショップを4件開催します。ぜひ、ご参加くださ […]

AWS Weekly Roundup: AWS での Claude Opus 4.8、Kiro Powers を利用する Aurora MySQL など (2026 年 6 月 1 日)
私の前回の Week in Review の記事では、私が開催している AI-Driven Developme […]