Amazon Web Services ブログ
Category: RDS for Oracle

Amazon RDS for Oracle レプリカのレプリカ遅延を診断して解消する – Part 2
本記事は Amazon RDS for Oracle リードレプリカのレプリケーション遅延を減らす 2 回シリーズの後編です。CloudWatch メトリクスとデータベースビューによる遅延の監視、待機イベント分析による根本原因の特定、そして遅延を解消するための段階的なトラブルシューティング手法を、プライマリ側とリードレプリカ側の 2 つの実践シナリオを通じて紹介します。

REDO 圧縮による Amazon RDS for Oracle レプリカのレプリケーションラグ最適化 – パート 1
本記事では、Amazon RDS for Oracle のクロスリージョンレプリカにおけるレプリケーションラグを REDO 圧縮機能で最適化する方法を説明します。REDO 圧縮の仕組み、有効化手順、実際の負荷テストによる効果を SLOB ツールを用いて検証し、圧縮有効時にラグが大幅に削減されることを示します。

Amazon RDS for Oracle でのデータマスキング
Oracle Data Masking and Subsetting Pack を Amazon RDS for Oracle で使用する方法を説明します。Oracle Enterprise Manager (OEM) でのデータマスキングのセットアップから、マスキングスクリプトの生成と実行、EventBridge と Step Functions による自動化まで、非本番環境を本番相当のデータで安全にリフレッシュする手順を紹介します。

Oracle Database@AWS を読み解く: Oracle ワークロードに最適な選択肢の見極め方
2025 年 7 月に GA となった Oracle Database@AWS (ODB@AWS) が Oracle ワークロードに適しているかを判断する 5 つの質問と、ビジネス・技術・ライセンス面での利点、Amazon RDS for Oracle や EC2 との使い分けを解説します。

Amazon RDS for Oracle の追加ストレージボリュームを使ったデータ作成と再編成のベストプラクティス
Amazon RDS for Oracle の追加ストレージボリューム機能を使い、64 TiB を超えるストレージ拡張、アクティブデータと履歴データの分離配置、一時ストレージの確保を行う方法とベストプラクティスを解説します。

セガサミーホールディングスがオンプレミスの Oracle Database を Amazon RDS for Oracle に移行し、性能と運用効率を大幅改善
セガサミーホールディングス株式会社は、エンタテインメントコンテンツ事業、遊技機事業、ゲーミング事業の 3 つの […]
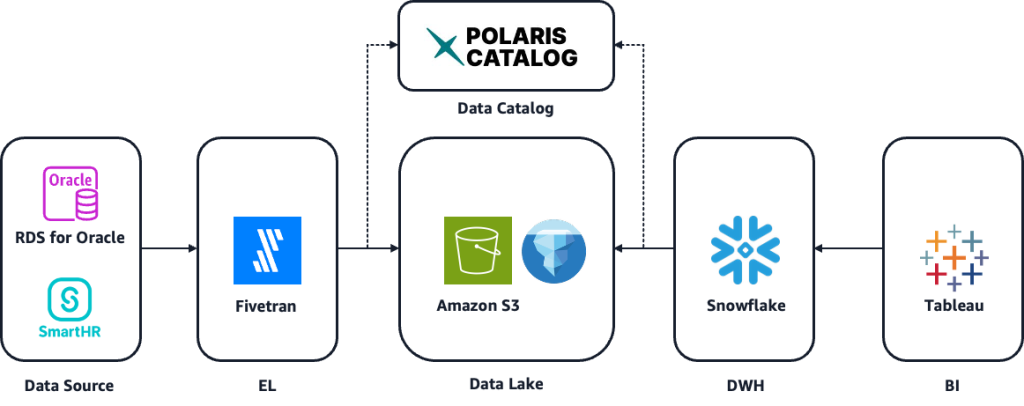
Fivetran の CDC 機能で実現するラーメン山岡家の Iceberg on AWS データパイプライン
ラーメンチェーン「山岡家」を展開する株式会社丸千代山岡家が、Fivetran の CDC(Change Data Capture)機能を活用して Amazon RDS for Oracle から Amazon S3 上の Apache Iceberg テーブルへのデータ同期を実現した事例をご紹介します。アーキテクチャの検討プロセスや Fivetran 採用の理由、約 5 分のデータ反映、月あたりの運用工数を 6 日から 0.5 日に削減、PoC から本番稼働まで約 1 ヶ月という短期導入といった導入効果を解説します。
ディップ株式会社 Exadataから Amazon RDS for Oracleへの移行でコスト56%削減を実現
ディップ株式会社は、求人情報サイト「バイトル」や「はたらこねっと」などの運営や、中小企業の労働力を改善する D […]

ニフティ株式会社、Amazon RDS for Oracle への移行によりシステム環境のランニングコストを77%削減
ニフティグループでは、Amazon RDS に移行することで、システム環境のコストを77%削減しました。また、運用・保守作業の効率化、メンテナンス時期の柔軟な選択が可能になり、システムの安定性とセキュリティも向上しました。さらに、若手エンジニアの育成機会の創出にもつながっています。

2025 年 10 月の AWS Black Belt オンラインセミナー資料及び動画公開のご案内
2025 年 10 月に公開された AWS Black Belt オンラインセミナーの資料及び動画についてご案内させて頂きます。