Amazon Web Services ブログ
Category: Database

AWS Summit Japan 2026 における Database 関連の注目セッションのご紹介
日本最大の「AWS を学ぶイベント」、AWS Summit Japan が 2026年6月25日(木)、26日 […]

ExtendDB のご紹介: プラガブルなストレージバックエンドを備えたオープンソースの DynamoDB 互換アダプター
本記事は 2026 年 05 月 20 日に公開された “Introducing ExtendDB […]

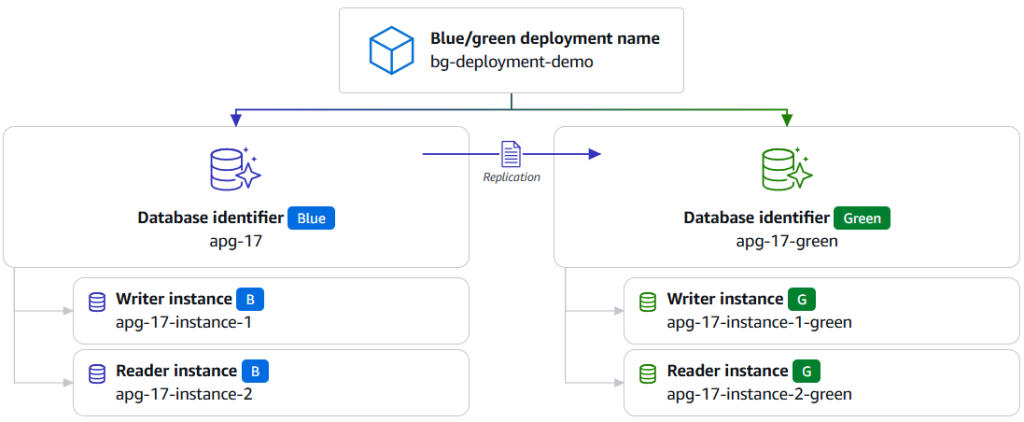
Amazon RDS ブルー/グリーン デプロイを使用した Amazon Aurora PostgreSQL アップグレードのロールバック戦略の実装
本記事は、2025 年 6 月 20 日に公開された Implement a rollback strateg […]

AWS Weekly Roundup: イスタンブールの AWS ローカルゾーン、オープンソースの ExtendDB、Kiro Web など (2026 年 5 月 25 日)
スタートアップとの仕事には、本当に刺激的な何かがあります。私は 2 年以上にわたって、このような仕事に精力的に […]

AWS Advanced JDBC Wrapper による JDBC クエリキャッシュの自動化
AWS Advanced JDBC Wrapper の Remote Query Cache Plugin を使用して、JDBC クエリ結果を Amazon ElastiCache for Valkey に自動的にキャッシュする方法を紹介します。SQL ヒントを追加するだけで、アプリケーションコードの大幅な変更なしにデータベース負荷を削減しパフォーマンスを向上できます。
テイツーが挑むリユース業界の店舗 DX – AWS で実現した POP 自動生成サービス「POP×THREE」
本ブログは、株式会社テイツー様とアマゾン ウェブ サービス ジャパン合同会社が共同で執筆いたしました。 AWS […]

Amazon Aurora DSQL の接続: ドライバー、接続文字列、ベストプラクティス
本記事では、Amazon Aurora DSQL への接続方法を解説します。ドライバーの設定、IAM ベースの認証トークン生成、接続プーリング、ライフサイクル管理のベストプラクティスに加え、一般的な接続問題のトラブルシューティングガイドを紹介します。
AWS JDBC Driver の Blue/Green デプロイメントプラグインでデータベースメンテナンスのダウンタイムをほぼゼロに
本記事では、AWS JDBC Driver の Blue/Green デプロイメントプラグインを紹介します。このプラグインは、Amazon RDS および Amazon Aurora の Blue/Green デプロイメント切り替え時に、接続ルーティングとトラフィック管理を自動化し、データベースメンテナンスのダウンタイムをほぼゼロにします。プラグインの設定方法とテスト結果を示し、従来の 30 秒超のダウンタイムを約 12 秒の一時停止に短縮できることを実証します。

Amazon Aurora DSQL での Change Data Capture 入門
Amazon Aurora DSQL は、パブリックプレビューで Change Data Capture (CDC) を発表しました。これにより、データベースの変更をほぼリアルタイムで Amazon Kinesis Data Streams にストリーミングできます。本記事では、Aurora DSQL CDC の仕組み、ストリーミングパイプラインの構成方法、変更イベントの消費方法を、CDC ストリームと Kinesis ストリームの作成から実際のイベント解析までの手順とともに説明します。
Amazon Aurora DSQL によるグローバル規模の金融トランザクション
Amazon Aurora DSQL を使用して、強い整合性と低レイテンシーを両立しながらグローバル規模の金融トランザクションを実行する方法を解説します。コアバンキング、グローバル経費管理、デジタル通貨インフラストラクチャの 3 つのユースケースを通じて、従来の 2 フェーズコミットや結果整合性のトレードオフを解消するアーキテクチャを紹介します。