Amazon Web Services ブログ
Category: AWS Glue

Amazon FSx for NetApp ONTAP が Amazon S3 と統合され、シームレスなデータアクセスが可能になりました
2025 年 12 月 2 日、Amazon Simple Storage Service (Amazon S […]
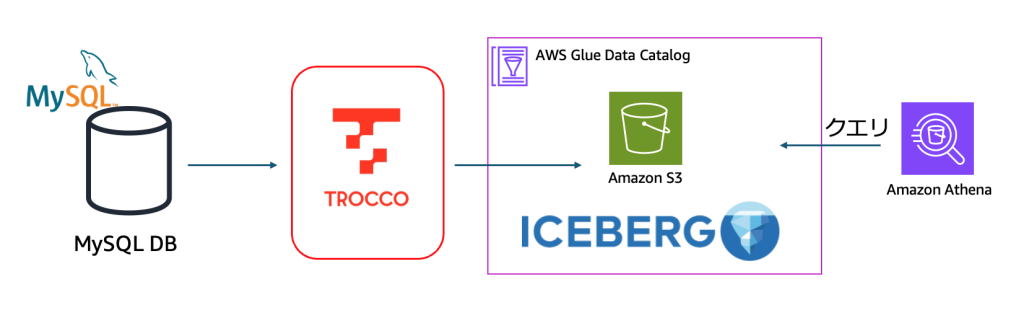
TROCCO の CDC 機能をつかった RDB と Apache Iceberg on AWS の連携
データベースの変更をリアルタイムに分析基盤へ反映したいというニーズに高まりを感じています。実際に多くのお客様から相談をいただいております。またデータベースの差分をもとに連携することが望まれる場面も多くあります。そういう場合の選択肢の一つが CDC(Change Data Capture)と呼ばれる MySQL の binlogなどの変更履歴をもとにデータを連携する手法になります。しかし、CDC での実装は、データ取得・キャッシュレイヤー・コンシューマーの実装とコンポーネントが多くなる場合も多く技術的なハードルが高く、ソースデータベースのスキーマの変更をターゲットの分析基盤に滞りなく連携する必要があるなど運用負荷も大きいワークロードになります。
CDC のターゲットの選択肢の1つとして、Iceberg を利用することで多様なエンジンから利用することができ、ソーススキーマの変更にも柔軟に対応ができるコスト効率の良い、DB のデータをソースにしたデータレイクハウスを構築することができます。
本記事では、AWS パートナーである primeNumber 社が提供するデータ統合プラットフォーム「TROCCO」の CDC 機能を使って、MySQL から AWS 上の Apache Iceberg テーブルへのリアルタイムレプリケーションを実現する方法をご紹介します。実際に検証した内容をもとに、セットアップから運用まで詳しく解説していきます。

AWS Glue zero-ETLによるSAPデータの取り込みとレプリケーション
AWS Glue zero-ETLは、SAP BW、ABAP、CDSビューなどのODP対応・非対応データソースからのデータ取り込みとレプリケーションを実現するサービスです。抽出されたデータはAmazon Redshift、Amazon SageMaker lakehouseアーキテクチャ、Amazon S3 Tablesに書き込まれ、Amazon QやAmazon Quick Suiteと組み合わせることで、自然言語クエリによるSAPデータ分析、AIエージェントの自動化、企業データ全体にわたるコンテキストインサイトの生成が可能になります。

AWS Glue Data Catalog での Apache Iceberg テーブルのカタログフェデレーションの紹介
Apache Iceberg は、大規模で堅牢かつ信頼性の高い分析を求める組織にとって、オープンテーブルフォーマットの標準的な選択肢となっています。しかし、企業は異なるカタログシステムを持つ複雑なマルチベンダー環境をますます多く扱うようになっています。マルチベンダー環境で運用する組織にとって、これらのシステム間でデータを管理することは大きな課題となっています。この断片化は、特にアクセス制御とガバナンスに関して、運用上の複雑さを大幅に増加させます。Amazon Redshift、Amazon EMR、Amazon Athena、Amazon SageMaker、AWS Glue などの AWS 分析サービスを使用して AWS Glue Data Catalog 内の Iceberg テーブルを分析しているお客様は、リモートカタログのワークロードでも同じ価格性能を得たいと考えています。これらのリモートカタログを単純に移行または置き換えることは現実的ではなく、チームはシステム間でメタデータを継続的に複製する同期プロセスを実装・維持する必要があり、運用上のオーバーヘッド、コストの増加、データの不整合のリスクが生じます。

Apache Iceberg V3 の deletion vectors と row lineage でデータレイク操作を高速化する
Apache Iceberg V3 では deletion vectors と row lineage が導入されました。AWS は Amazon EMR、AWS Glue、Amazon SageMaker、Amazon S3 Tables、AWS Glue Data Catalog でこの機能を提供しています。本記事では、新機能の概要、業界横断のユースケース、AWS サービスでの実装方法を紹介します。
Amazon SageMaker レイクハウスアーキテクチャによる Amazon S3 上の Apache Iceberg テーブルの最適化設定の自動化
本記事は、2025 年 8 月 8 日に公開された The Amazon SageMaker lakehous […]
Zero-ETL: AWS によるデータ統合の課題への取り組み
このブログ記事では、Amazon Web Services (AWS) の Zero-ETL を活用することで、データ統合を簡素化すると同時に、パフォーマンスの向上やコストの最適化も実現する方法を紹介します。
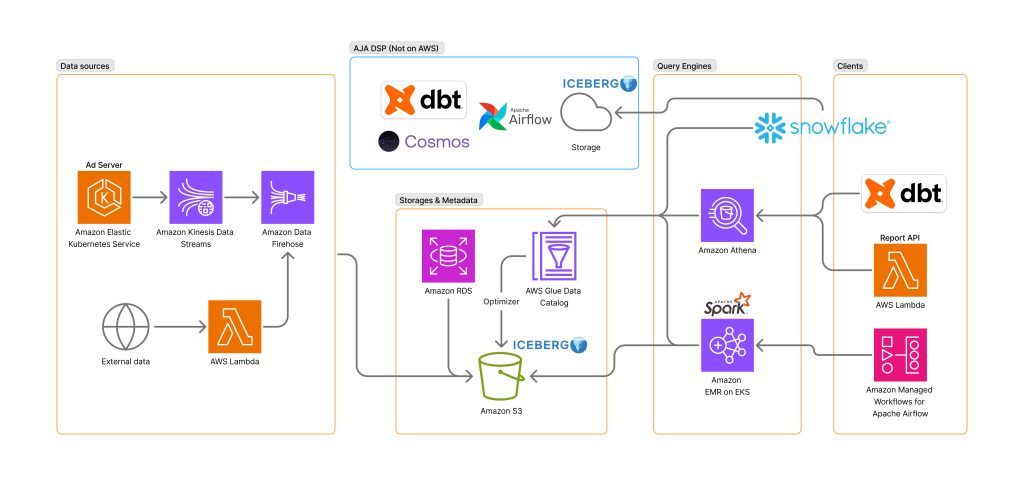
AJA SSP が Apache Iceberg と AWS Glue Data Catalog でペタバイトスケールのデータ基盤の柔軟なクエリエンジンの選択とクエリの高速化を実現
※ この記事はお客様に寄稿いただき、AWS が加筆・修正したものとなっています。 株式会社 AJA は、株式会 […]
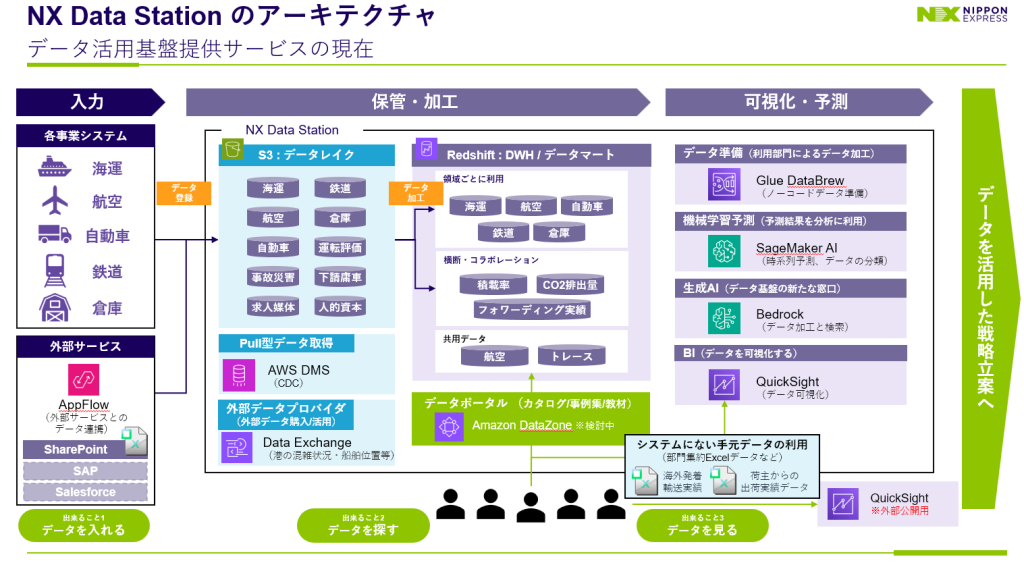
物流業界のチャレンジを支えるデータ活用 – Nippon Express の事例から
物流業界において、特にデータを活用した改善は、物流DXとして総合物流施策大綱でも長年にわたり強く推奨されてきました。このような状況を受けて多くの物流企業がデータ活用を経営戦略の重要項目として位置付けているものの、実態としては有効な施策が打ち出せずにいるケースが多く見受けられます。
本記事ではそういった課題に悩まれる物流事業担当者向けに、データ活用の成功モデルとして日本通運株式会社(以下Nippon Express)のデータ分析基盤「NX Data Station」を解説します。同社は既存リソースを最大限に活用しながら、コスト効果の高いデータ分析基盤を構築し、データを基に業務効率化と意思決定の質向上を実現しています。
記事は2025年7月15日に開催された Amazon SageMaker Roadshow でのNX情報システム および キヤノンITソリューションズ のセッション内容をもとに記載しています。

【開催報告 & 資料公開】Apache Iceberg on AWS ミートアップ開催報告
2025 年 5 月 14 日に「Apache Iceberg on AWS ミートアップ ~話題のIcebergをAWSで徹底活用~」と題したイベントを開催しました。ご参加いただきました皆様には、改めて御礼申し上げます。
本セミナーでは、AWS における Iceberg の活用についてさまざまな角度からご紹介しました。Iceberg 活用の全体像に加えて、マネージドな Iceberg のストレージである Amazon S3 Tables Bucket、既存データレイクからの移行における考え方、リアルタイムデータ処理を実現するストリーミングワークロードの実装方法、更には機械学習における活用まで、幅広いトピックをご紹介しました。本ブログでは、その内容を簡単にご紹介しつつ、発表資料を公開致します。
すでに Iceberg を活用されている方も、これからはじめる方も是非ご確認下さい!