Amazon Web Services ブログ
AWS Glue データカタログが Apache Iceberg テーブルの自動コンパクションをサポートするようになった
11月14日、AWS Glue データカタログ新機能として、Apache Iceberg 形式のトランザクションテーブルの自動コンパクションが利用可能になりました。これにより、トランザクションデータレイクテーブルのパフォーマンスを常に維持できます。
データレイクは当初、膨大な量の生データ、非構造化データ、または半構造化データを低コストで保存することを主な目的として設計され、一般的にビッグデータやアナリティクスのユースケースと関連付けられていました。時間の経過とともに、組織がデータレイクを単なるレポーティング以上の用途に使用する可能性を認識し、データ整合性を確保するためにトランザクション機能を含める必要が出てきたため、データレイクに可能なユースケースの数は進化してきました。
データレイクは、データ品質、ガバナンス、コンプライアンスにおいても極めて重要な役割を果たします。特に、データレイクが保存する重要なビジネスデータの量は増加しており、更新や削除が必要になることも多いです。データ主導型の組織は、バックエンドの分析システムを顧客のアプリケーションとほぼリアルタイムで同期させる必要もあります。このシナリオでは、データの整合性を損なうことなく同時書き込みと同時読み取りをサポートするために、データレイクにトランザクション機能が必要です。最後に、データレイクは統合ポイントとして機能するようになり、さまざまなソース間で安全で信頼性の高いデータ移動を行うためのトランザクションが必要になります。
データレイクのテーブルでトランザクションセマンティクスをサポートするために、組織は Apache Iceberg のようなオープンなテーブルフォーマット (OTF) を採用しました。既存のデータレイクのテーブルを Parquet や Avro フォーマットから OTF フォーマットに変換すること、各トランザクションが Amazon Simple Storage Service (Amazon S3) 上で新しいファイルを生成するため大量の小さなファイルを管理すること、オブジェクトとメタデータのバージョニングを大規模に管理することなどです。組織は通常、これらの課題に対処するために独自のデータパイプラインを構築して管理しているため、インフラストラクチャに関する作業がさらに差別化されていません。コードを書いたり、Spark クラスターをデプロイしてコードを実行したり、クラスターをスケーリングしたり、エラーを管理したりする必要があります。
顧客と話す中で、最も困難な側面は、テーブルへの各トランザクション書き込みによって生成される個々の小さなファイルを数個の大きなファイルにコンパクションすることであることが分かりました。ファイルが大きいほど読み取りとスキャンが速くなり、分析ジョブとクエリの実行が速くなります。コンパクションは、サイズの大きいファイルのテーブルストレージを最適化します。テーブルのストレージを多数の小さなファイルから、少数の大きなファイルに変更します。メタデータのオーバーヘッドが減り、S3 へのネットワークラウンドトリップが減り、パフォーマンスが向上します。コンピュートに対して課金されるエンジンを使用する場合、クエリーの実行に必要なコンピュート容量が少なくて済むため、パフォーマンスの向上は利用コストにとっても有益です。
しかし、Iceberg テーブルをコンパクト化して最適化するためのカスタムパイプラインを構築するには、時間とコストがかかります。プランニングの管理、インフラストラクチャのプロビジョニング、コンパクションジョブのスケジュールと監視を行う必要があります。これが、本日、自動コンパクションを開始する理由です。
仕組みを見てみましょう
Iceberg テーブルの自動コンパクションを有効にして監視する方法を示すために、私は AWS マネジメントコンソールの AWS Lake Formation ページまたは AWS Glue ページから始めます。Iceberg 形式のテーブルを含む既存のデータベースがあります。数日の間にこのテーブル上でトランザクションを実行し、テーブルは基礎となる S3 バケット上の小さなファイルに断片化し始めます。

コンパクションを有効にしたいテーブルを選択し、「コンパクションを有効にする」を選択します。
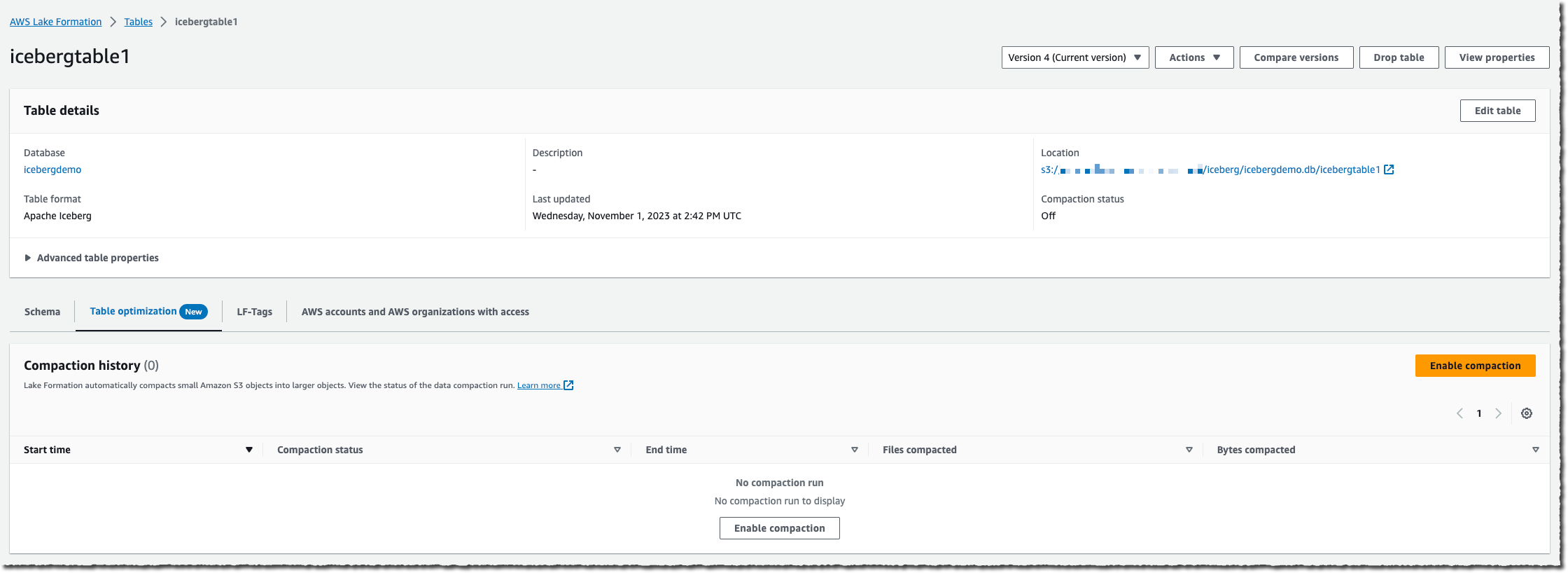
AWS Glue テーブル、S3 バケット、および CloudWatch ログストリームにアクセスするためのアクセス権限を Lake Formation サービスに渡すには、IAM ロールが必要です。新しい IAM ロールを作成するか、既存の IAM ロールを選択します。既存のロールには、テーブルに対して lakeformation:GetDataAccess と glue:UpdateTable のパーミッションが必要です。また、「arn:aws:logs:*:your_account_id:log-group:/aws-lakeformation-acceleration/compaction/logs:*」にlogs:CreateLogGroup、logs:CreateLogStream、logs:PutLogEvents が必要です。ロールトラステッドパーミッションサービス名は glue.amazonaws.com に設定する必要があります。
次に、「コンパクションをオンにする」を選択します。そしてその通りです! コンパクションは自動的に行われるため、お客様側で管理する必要はありません。
サービスはテーブルの変化率の測定を開始します。Iceberg テーブルは複数のパーティションを持つことができるため、サービスはパーティションごとにこの変更率を計算し、この変更率がしきい値を超えたパーティションをコンパクトにするために管理されたジョブをスケジュールします。
テーブルの変更回数が多くなると、コンソールの「最適化」タブにある「コンパクション履歴」を見ることができるようになります。
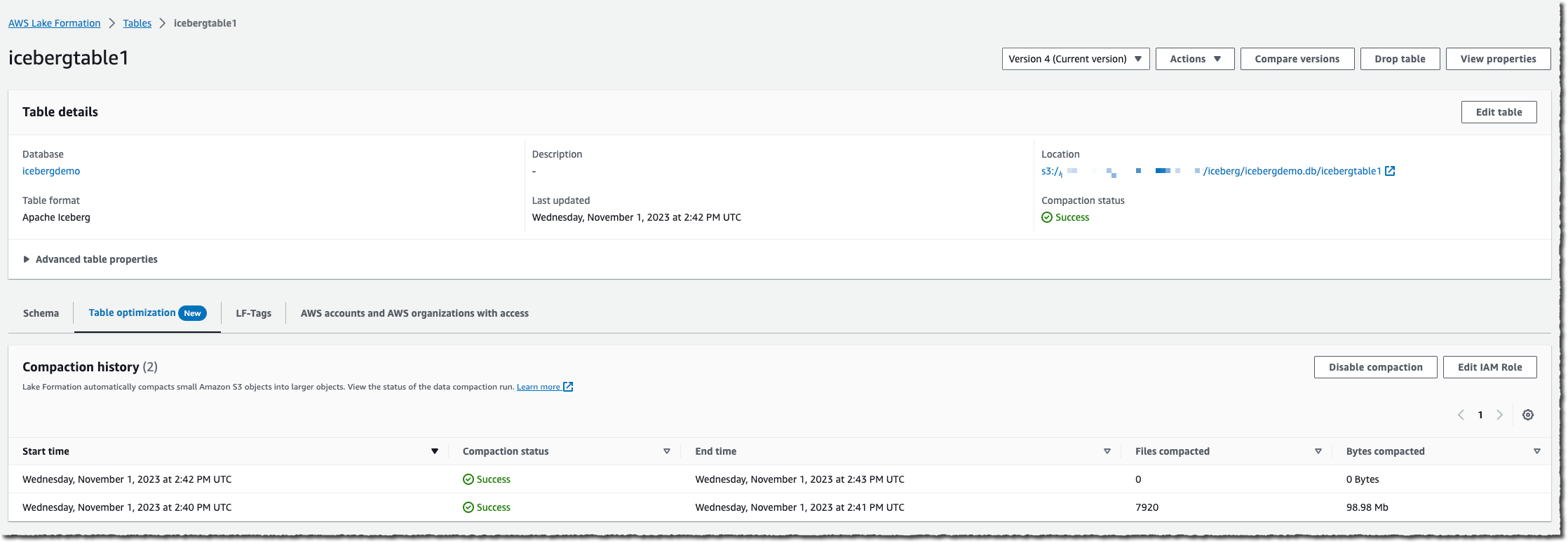
また、S3 バケット上のファイル数 (NumberOfObjects メトリックを使用) または 2 つの新しい Lake Formation メトリック (numberOfBytesCompacted または numberOfFilesCompacted) のいずれかを観察することによって、プロセス全体を監視することもできます。
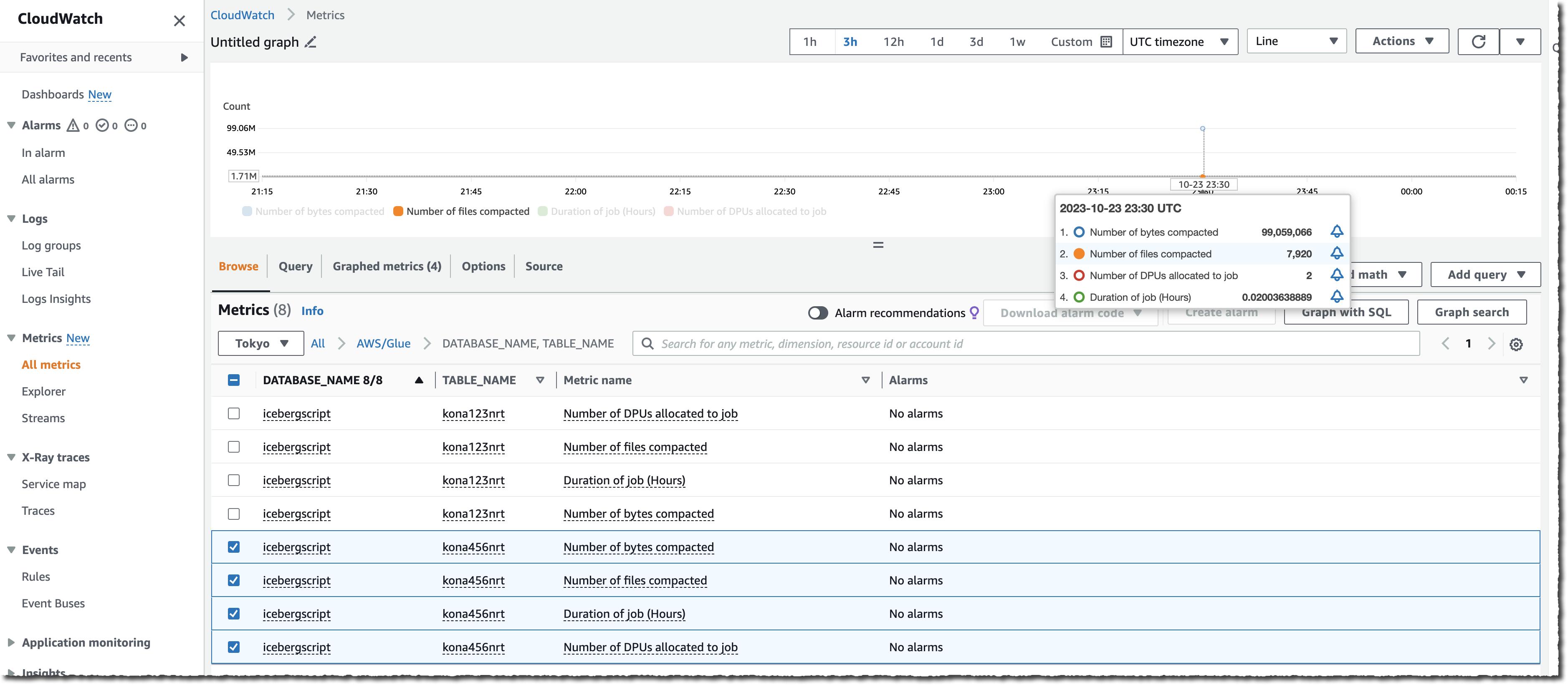
AWS コンソールに加えて、CreateTableOptimizer、BatchGetTableOptimizer、UpdateTableOptimizer、DeleteTableOptimizer、GetTableOptimizer、ListTableOptimizerRuns のようなこの新しい機能を公開する 6 つの新しい API があります。これらの API は、AWS SDK と AWS コマンドラインインターフェイス (AWS CLI) で利用可能です。いつものように、これらの新しい API にアクセスするには、SDK または CLI を最新バージョンに更新することを忘れないでください。
留意点
本日、この新機能を公開したので、他にもいくつかお伝えしたい点があります。
- コンパクションでは、削除したファイルはマージされません。データが削除されたテーブルは圧縮されますが、削除ファイルが関連付けられているデータファイルはスキップされます。
- VPC エンドポイント経由で VPC から排他的にアクセスするように設定された S3 バケットはサポートされていません。
- Apache Parquet を使ってデータを保存している Apache Iceberg テーブルはコンパクトにできます。
- コンパクションは、デフォルトのサーバ側暗号化 (SSE-S3) または KMS 管理鍵によるサーバ側暗号化 (SSE-KMS) で暗号化されたバケットで動作する
可用性
この新機能は、AWS Glue データカタログが利用可能なすべての AWS リージョンで本日より利用可能です。
価格設定指標はデータ処理ユニット (DPU) であり、4 つの vCPU の計算能力と 16 GB のメモリで構成される処理能力の相対的な指標です。DPU あたりの課金は、1 時間あたりの秒単位で、最低 1 分かかります。
今こそ、既存のコンパクションデータパイプラインを廃止し、この新しい完全に管理された機能に切り替える時です。
原文はこちらです。