Amazon Web Services ブログ
異常検出にビルトイン Amazon SageMaker Random Cut Forest アルゴリズムを使用する
本日、Amazon SageMaker 向けの最新ビルトインアルゴリズムとして、Random Cut Forest (RCF) のサポートを開始しました。RCF は監視を伴わない学習アルゴリズムで、データセット内の異常なデータポイントや外れ値を検出します。このブログ記事では異常検出に関する問題について紹介するとともに、Amazon SageMaker RCF アルゴリズムについて説明し、実世界のデータセットを使った Amazon SageMaker RCF の使用法を実演します。
異常検出は極めて重要です
たとえば、いくつもの街の区画で長期間にわたり交通量のデータを収集してきたとします。交通量が急増した場合、その背後にあるのが何らかの事故なのか、一般的なラッシュアワーなのかを予測することはできますか?交通量の急増が 1 区画だけで起きているのか、複数の区画で起きているのかは重要ですか? また、1 つのクラスターにあるサーバー間にネットワークのストリームがあるとします。そのインフラストラクチャが目下 DDoS 攻撃を受けている最中なのか、またはネットワークアクティビティの増加が良好な状態であるかを自動的に見極めることはできますか?
異常とは、 よく系統立てられた、またはパターン化されたデータから逸脱する観測結果を意味します。たとえば、異常は時系列データ上の想定外の急増、周期性のある中断、または分類不能なデータポイントを示します。データセットにそうした異常なデータが含まれる場合、「通常」データはシンプルなモデルで記述されることから、機械学習タスクの複雑性を急激に増大させる可能性があります。
Amazon SageMaker Random Cut Forest アルゴリズム
Amazon SageMaker Random Cut Forest (RCF) アルゴリズムはデータセット内の異常なデータポイントを検出するための監視を伴わないアルゴリズムです。特に、Amazon SageMaker の RCF アルゴリズムは 1 件の異常スコアと各データポイントを関連付けます。異常スコアの値が低ければ、データポイントが「通常」であることを意味し、スコアの値が高ければ異常があることを意味します。「低い」と「高い」の定義はアプリケーションによって異なりますが、慣例から平均スコアから 3 つの値が逸脱していた場合、異常と見なされます。
Amazon SageMaker の RCF アルゴリズムの処理ではまず、トレーニングデータからランダムなサンプルを取得することから始めます。トレーニングデータが 1 台のマシンに入りきらない可能性がある場合は、レザボアサンプリングと呼ばれる手法で、データストリームから効果的にサンプルを抽出します。その後、ランダムカットフォレストの各構成要素ツリーにサブサンプルが配分されます。各サブサンプルはそれぞれの葉が単独のデータを含む 1 つのバウンディングボックスを表すように分割されるまでランダムにバイナリツリーへと分割されていきます。入力データポイントへ割り当てられた異常スコアは、そのフォレストの平均的な深度に対し、逆比例します。詳細については、SageMaker RCF のドキュメンテーションページをご覧ください。基となるアルゴリズムは本ブログ記事の最後に掲載されている参照セクションで説明されている作業をベースにしています。
ハンズオン例: タクシーの利用客数データからニューヨーク市のイベントを検出する
ニューヨーク市のタクシー利用者数、6 か月間分で構成されるサンプルデータセットで Amazon SageMaker RCF のデモをご覧いただきます。これらのデータは Numenta Anomaly Benchmark (NAB) New York City Taxi dataset で一般公開されています。このあとに示すコードサンプルでは、SageMaker RCF モデルをトレーニングし、乗客数データの異常を検出するためにそのモデルを使用します。詳細については、予備ノートをご覧ください。
Amazon S3 でデータを取得、検査、保存する
最初に NAB データセットを取得し、グラフ化します。これらのデータはニューヨーク市における約 6 か月間のタクシー利用者数で、それぞれのデータポイントは 30 分間の時間枠のタクシー利用者数ボリュームを示しています。

私たちが予想したとおり、タクシーの利用者数はほぼ周期的です。日中、特に一般的な通勤時間帯の利用量が高く、深夜の利用料が低くなっています。また、週末より平日のタクシー利用者数が多いという、週次の周期性も確認できました。グラフを詳細に見ていくと、複数の異常データポイントが簡単に確認できました。結局のところ、人間というのは極めて視覚に依存した生き物で、何万年もの進化のあいだ、卓越したパターン検出能力を発達させてきました。特に、このような異常はタクシー利用者数の急増や激減、または特徴的な周期性の動きが中断されるときに起こります。これらの一部は有名なイベントに対応しています。たとえば、t=5954 はニューヨークシティマラソン、t=8833 は大晦日、t=10090 は暴風雪に見舞われたときを示しています。
他の多くの Amazon SageMaker アルゴリズムと同様、トレーニングは RecordIO Protobuf 形式にエンコーディングされたデータで最もよく機能します。次の例では CSV 形式のデータを変換し、そのデータを Amazon S3 バケットへプッシュしています。
モデルのトレーニング
このデータセットで SageMaker Random Cut Forest モデルのトレーニングを行う前に、まず、Amazon SageMaker Random Cut Forest アルゴリズム用の Amazon Elastic Container Registry (ECR) Docker コンテナ、トレーニングデータの場所、アルゴリズムを実行するインスタンスタイプなど、トレーニングジョブのパラメーターを指定する必要があります。また、アルゴリズム固有のハイパーパラメーターも指定します。Amazon SageMaker RCF アルゴリズムの 2 つの主要なハイパーパラメーターは、num_trees と num_samples_per_treeです。
ハイパーパラメーター、num_trees は、RCF モデルで使用されるツリーの数を設定します。各ツリーは入力トレーニングデータのサブサンプルから別々のモデルを学習し、ツリーの深さに反比例する指定のデータポイントの異常スコアを出力します。全体の RCF モデルによってデータポイントに割り当てられた異常スコアは、構成要素ツリーごとに計算、報告された平均スコアと等しくなります。ハイパーパラメーター、num_samples_per_tree は、 ランダムにトレーニングされたポイントがいくつ各ツリーに送信されるかを指定します。ここで num_samples_per_tree の値として適切なのは、データセットの異常値の想定される割合に近い逆の値です。詳細については、Amazon SageMaker RCF – How it Works をご覧ください。
次のコードは 50 本のツリーを使用し、各ツリーに 200 個のデータポイントを送信することで、タクシーデータに SageMaker RCF モデルを適合させます。
異常スコアを予測する
次に、このトレーニング済みモデルを使用して、各トレーニングデータポイント用に異常スコアをコンピューティングしていきます。その他の Amazon SageMaker アルゴリズムと同様に、先に作成したモデルを使用して推論エンドポイントを作成することから始めましょう。
次に、各ポイントに関連付けられた異常スコアを取得するためにトレーニングセット全体で推論を実行します。私たちは異常の分類にシンプルで標準的な手法を使います。平均スコアの 3 つの標準的な逸脱の外にあるすべての異常スコアは異常と見なされます。より強固な手法もありますが、このデモではこの手法で十分です。
最後に、異常と見なされるデータポイントをハイライトしてタクシーの利用者数データのスコアを図式化します。

上記の図から、SageMaker RCF アルゴリズムが既知の異常値をいくつか検出していることがわかります: ニューヨークシティマラソン – t=5954、大晦日 – t=8833、暴風雪 – t=10090。しかし、使用できるデータポイントの量が少ないことから、長期的な行動における粒度の細かい変化を特定するモデルの性質の結果として、異常スコアの予測でいくつかの乱れを拾ってみましょう。
事前処理戦略: 重複を検証することで精度を改善
多くの機械学習タスクでは、精度とパフォーマンスを改善するために、データを事前処理するのが一般的です。異常検出アルゴリズムでは、shingling (重複する可能性の検出) は標準的な技法で、隣接する長さ s のサブシーケンスを 1 次元のベクターへと変換することにより、1 次元のデータを s 次元のデータへと変換します。利点は周期性のある中断をより良く検出するほか、オリジナルの異常スコアで小さなスケールのノイズをフィルターできる点にあります。もし、重複を検証するためのサイズが小さすぎる場合、このブログ記事の前半で見たタクシー利用者数の図からもわかるように、ランダムカットフォレストはデータに含まれる小さな断片により影響を受けやすくなる点に注意してください。しかし、重複を検証するためのサイズが大きすぎる場合、より小さなスケールの異常値は検出されません。SageMaker RCF ハイパーパラメーター、num_trees と num_samples_per_tree のように、重複を検出するためのサイズの最適値は問題によって異なります。
次の図では、1 次元のデータストリームを 4 次元の重複検証データへと変換したときの推移を示したものです。重複を検出するための処理を施した最初のデータポイントには 4 つのデータポイントが含まれ、順に、2つ目の処理を施したデータポイントには次の 4 つのデータポイントが含まれます。

NYC のタクシー利用者数データに含まれる各データポイントは 30 分ごとの周期性のある利用客数を示しています。毎日の利用者数に周期性があることを想定するのは妥当で、普通の日にはタクシーの利用者数は若干の差はあるもののほぼ同じです。つまり、月曜日の利用客数は火曜日と同じということです。要するに、このデータを 48 の重複検出用サイズに切り出すのには意味があります。 (24 時間 = 48 データポイント * 0.5 時間/データポイント。) NYC のタクシー利用者数データの重複を検出するために次の関数を使用します。
以下の図では、この推移を本来のデータセットに適用し、新しいトレーニングと推論ジョブを Amazon SageMaker 上で実行したあと、結果となる異常スコアを図に示します。

重複を検出するための処理を施すアプローチの方が、t=10090 に見られる暴風雪時の利用者数の劇的な落ち込みといった、大きなスケールの異常を特定するジョブに適しています。ラベル付きのテストデータセットがある場合は、SageMaker RCF は精度、リコール、F1 スコアなど、多数の精度基準を出力できます。これらの基準を分析することにより、num_trees と num_samples_per_tree の最適な値を判別し、これらの精度スコアを最大化します。
ベンチマーク
Amazon SageMaker RCF は機能の数、データセットのサイズ、インスタンスの数に応じて適切にスケーリングします。本記事の後半では、SageMaker RCF のパフォーマンス、精度、スケーリングのベンチマークについてご紹介します。これらのベンチマークは「通常」のデータを示す 2 つのガウス分布データクラスターと、2 つの通常クラスターの間に該当する「異常」データを示す小さなガウス分布データクラスターからなる合成データセット上で実行されます。各データセットにおよそ 0.5% 分の異常データポイントが含まれます。それぞれの試みは、ml.m4.xlarge インスタンスタイプ上で実行されます。
パフォーマンス
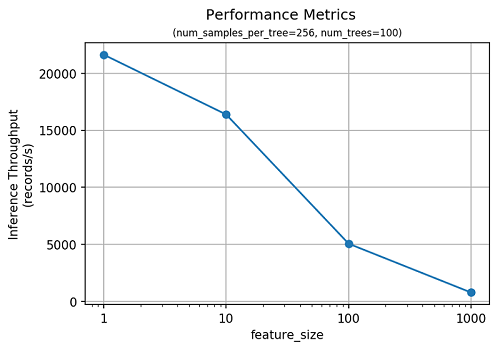
可変の特徴次元サイズを持つデータセット上で SageMaker RCF を測定しました。次の図では、RCF モデルのトレーニングに要する合計時間について説明します。それぞれの試みで使用するのはnum_trees=100 と num_samples_per_tree=256です。トレーニング時間はデータセットの機能のサイズによって直線的にスケーリングします。

SageMaker RCF はまた、異常の予測でも効果的です。次の図では、特徴次元の機能に応じた推論のスループットについて説明します。
正確さ
異常検出の分野では異常検出アルゴリズムの精度を判定するために、いくつかの標準測定が使用されます。精度は正しく検出された異常と、アルゴリズムによって異常に分類されたポイント数の比率です。リコールは正しく検出された異常の数と既知の異常の合計の比率です。F1 は精度とリコールの調和平均です。次の図では、10 次元の合成データセットに関する精度のメトリクスを示しています。これには次のハイパーパラメーターの機能として、1 億個のレコードが含まれます:num_samples_per_tree。先にも示した通り、num_samples_per_treeの逆の値は、データセットの異常の割合に近付けます。
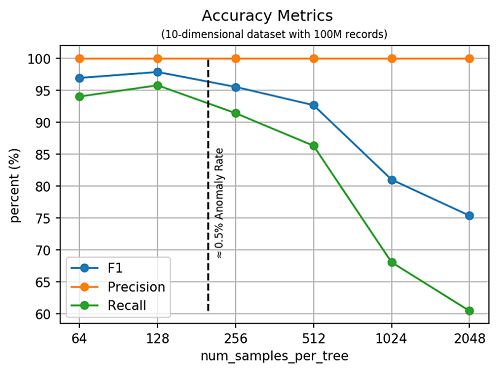
ここでは num_samples_per_tree の最大値の F1 スコアに到達する点に注意してください。これは合成データセットの既知の異常の割合に該当します。SageMaker RCF の精度を Scikit-learn の Isolation Forest (IF) アルゴリズムと比較してみました。小さなデータセットでは 2 つのアルゴリズムは似たような精度を示します。1 万件のレコードをもつ 10 次元のデータセットでは、両方のアルゴリズムが 99.6% の F1 スコアに到達しました。しかし、Scikit-learn IF は私たちの研究で使用したデータセットより大規模なデータセットでは実行できませんでした。
スケーリング
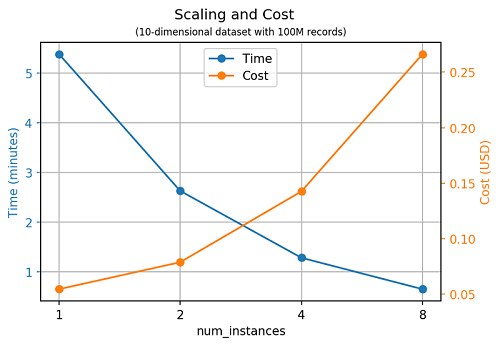
SageMaker RCF はインスタンスの数に応じてほぼ完璧にスケーリングします。ほぼ 2 倍のインスタンスの数がモデルのトレーニングに必要な時間の量を半分にします。
まとめ
Amazon SageMaker は大規模の機械学習モデルのトレーニングとデプロイにまつわる問題に、完全マネージド型のエンドツーエンドソリューションを提供します。Amazon SageMaker RCF アルゴリズムを使用することで、異常検出に Amazon SageMaker を使用できるようになります。このブログ記事で示した例では、小さな 1 次元の時系列データデータセットを使用しています。しかし、このアルゴリズムは特に、大規模な大次元のデータセットの異常検出に適しています。AWS AI アルゴリズムチームでは、Amazon SageMaker RCF アルゴリズムの革新的な使用例やおすすめ、改善点など皆様の声をお待ちしています。
参照
[1] Sudipto Guha, Nina Mishra, Gourav Roy, and Okke Schrijvers. “Robust random cut forest based anomaly detection on streams.” In International Conference on Machine Learning, pp. 2712-2721. 2016.
[2] Byung-Hoon Park, George Ostrouchov, Nagiza F. Samatova, and Al Geist. “Reservoir-based random sampling with replacement from data stream.” In Proceedings of the 2004 SIAM International Conference on Data Mining, pp. 492-496. Society for Industrial and Applied Mathematics, 2004.
今回のブログ投稿者について
 Chris Swierczewski は AWS AI アルゴリズムチームの応用科学者で、Amazon SageMaker の学習アルゴリズムの研究と開発を担っています。 Amazon に合流する前には Chris はワシントン大学博士課程にて応用数学を研究していました。彼は妻と二人の愛犬、リバーとともに、ハイキング、バックパックの旅、キャンプにでかけるのが好きです。
Chris Swierczewski は AWS AI アルゴリズムチームの応用科学者で、Amazon SageMaker の学習アルゴリズムの研究と開発を担っています。 Amazon に合流する前には Chris はワシントン大学博士課程にて応用数学を研究していました。彼は妻と二人の愛犬、リバーとともに、ハイキング、バックパックの旅、キャンプにでかけるのが好きです。
 Julio Delgado Mangas は AWS AI アルゴリズムチームのソフトウェア開発エンジニアです。 彼は、Amazon CloudWatch や Amazon QuickSight SPICE エンジンなどの AWS サービスに貢献しました。Amazon に合流する以前は、研究エンジニアとして人間の脳に関するプロジェクトに携わっていました。
Julio Delgado Mangas は AWS AI アルゴリズムチームのソフトウェア開発エンジニアです。 彼は、Amazon CloudWatch や Amazon QuickSight SPICE エンジンなどの AWS サービスに貢献しました。Amazon に合流する以前は、研究エンジニアとして人間の脳に関するプロジェクトに携わっていました。
 Madhav Jha は AWS AI アルゴリズムチームの応用科学者で、スケーラブルな機械学習アルゴリズムを開発するために、サブリニアアルゴリズムにおける彼の経歴を生かしています。彼はコーディングを好む、論理コンピューター科学者です。スタートアップやテクノロジーについてコーヒーを飲みながらおしゃべりするのが大好きです。
Madhav Jha は AWS AI アルゴリズムチームの応用科学者で、スケーラブルな機械学習アルゴリズムを開発するために、サブリニアアルゴリズムにおける彼の経歴を生かしています。彼はコーディングを好む、論理コンピューター科学者です。スタートアップやテクノロジーについてコーヒーを飲みながらおしゃべりするのが大好きです。
 Luka Krajcar は AWS AI アルゴリズムチームのソフトウェア開発エンジニアです。ザグレブ大学の電子工学およびコンピューティング学部でコンピューター科学の修士号を取得しました。余暇には読書やランニング、ビデオゲームなどを楽しみます。
Luka Krajcar は AWS AI アルゴリズムチームのソフトウェア開発エンジニアです。ザグレブ大学の電子工学およびコンピューティング学部でコンピューター科学の修士号を取得しました。余暇には読書やランニング、ビデオゲームなどを楽しみます。