- AWS Builder Center›
- builders.flash
ゆけ ! Amazon Redshift 警察 ~第二部 家のマシンで機械学習のワークロードを AWS のコンテナサービスで動かしてみるの巻
2022-01-05 | Author : 呉 和仁, 林 政利
プロローグ (作者対談)
林「あけましておめでとうございます。さて、4 ヶ月も空いちゃいましたが、今年も警察活動の続編を・・・って、あれ ? 前回 とタイトル変わっていませんか ?」
呉「気づくの早くないですか ?」
林「質問を質問で返すなあーっ !!」
呉「(どこかの漫画の第 4 部で見たセリフだぞ ?) いや、そんなつもりは・・・! 社内の先輩から圧力 ケ…ゲフンゲフン、いや、要望がありまして、ElastiCache 以外もやらないといけなくなってしまったのです。」
林「アットホームな職場ですね。」
呉「ええ、アットホームな職場です。なので、今回のタイトルはこれでなにとぞ。」
林「仕方ないですね。前回フィクションの中での呉さんが第一部で学習に使う画像生成の部分は外部から引数で受け取るようにしてたので、検出対象が変わっても引数変えれば動くはずですもんね。」
呉「え、ええ。多分。動くはずです。多分。おそらく。きっと。そうなんじゃないかな。」
林「というわけで、今回の第二部では 9 月に行われた AWS Dev Day で我々が登壇した 『Amazon ECS Anywhere と機械学習 ~ ハイブリッド環境でのモデルの構築と推論 ~』の内容を Redshift になおして動かす内容です。」
呉「前回はコンテナイメージを作ってコンテナを動かしましたが、それを AWS からオンプレのコンピューティングリソースに対して動けー ! と命じる内容ですね。」
林「はい、どうすれば実現できるのか、そうするとどんなメリットがあるのか、あたりをきっとフィクションの中の林さんが語ってくれるはずです。」
呉「それではフィクションの中の林さんと呉さんにおまかせしましょう。」
ご注意
本記事で紹介する AWS サービスを起動する際には、料金がかかります。builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
第 3 章 : 大量にある自宅の GPU の正しい使い方の模索
呉「あ・・・ありのまま 今 起こった事を話すぜ ! GPU 作っている会社の株価が上がると聞いて買ったと思ったのだが、誤って GPU を大量に買ってしまっていた・・・! な、何を言っているのかわからねーと思うが俺にもわからなかった・・・。この GPU どうしてくれようか。なんとか有効利用せねば。」
一攫千金を狙い、 GPU を作っている会社の株を買うつもりが、誤って GPU そのものを大量に買い付けてしまいました。
呉「そういえば林さんも株と間違えて GPU 買ったのかな ? 自宅で GPU 使って機械学習してたもんな。ん・・・機械学習か ! 私は機械学習を完全に理解している (※) し、この GPU は機械学習に使おう !」
※チュートリアルを完了できたという意
機械学習という用途を見つけて一安心です。
呉「Elasti“c”Cache は日々の活動でほぼ駆逐できたので、そろそろ Amazon Redshift 警察でもやるか。」
日々の活動の結果、目測範囲でしか確認していないにも関わらず ElastiCache の矯正は完了したと勝手にみなし、新たに取り締まろうとするのでした。
呉「それにしても Amazon Red“S”hift といい、“AWS” Redshift といい、いろいろあるなぁ。まずは大文字の S から撲滅してみるか。前回林さんに教えてもらった “コンテナ” を忘れずに使うぞ。まずは画像の作成だ」
また、得意になってコードを書き始めましたが、ここでふと思い出しました。
呉「そういえば 前回を思い出すと そもそも機械学習で CUDA 使うのインストール作業が大変な上、コンテナだとさらにやること多かったな・・・。ここは 1 つ CPU で動くコードを書いて林さんに聞いちゃおう。そしてあわよくばやってもらおう。ふひひ」
呉は Ownership のかけらもありませんでしたが、とりあえずコードを書きはじめました。
Dockerfile
呉「まずは学習データを作成する環境とコードからだ。Dockerfile を作ってと・・・」
FROM python:3.9-slim-buster
RUN apt-get -y update && \
apt-get -y upgrade && \
apt-get -y install wget cabextract xfonts-utils && \
wget http://ftp.jp.debian.org/debian/pool/contrib/m/msttcorefonts/ttf-mscorefonts-installer_3.8_all.deb (http://ftp.de.debian.org/debian/pool/contrib/m/msttcorefonts/ttf-mscorefonts-installer_3.8_all.deb) && \
dpkg -i ttf-mscorefonts-installer_3.8_all.deb && \
apt-get -y install fonts-takao \
fonts-ipafont \
fonts-ipaexfont
WORKDIR /workspace
COPY requirements.txt /workspace
RUN pip3 install -r requirements.txt
ENV PYTHONUNBUFFERED=TRUErequirements.txt
呉「あとはインストールするモジュールも requirements.txt にまとめてと・・・」
Pillow==8.3.1
numpy==1.21.2
matplotlib==3.4.3コンテナイメージビルド
呉「よし、コンテナイメージをビルドするぞっと。」
$ docker build -t amazon-redshift-police-generate-image:1 . # ターン!!
Sending build context to Docker daemon 4.096kB
…(中略)…
Successfully built 0123456789ab
Successfully tagged amazon-redshift-police-generate-image:1generate_image.py
呉「やった、なんとかできたぜ。Docker 完全に理解した !」(レベルアップのファンファーレが脳内に響く) 呉「さて、続いて画像生成コードだ。前回のをほぼ流用するぞ。」
from random import randint, seed
from PIL import Image,ImageDraw,ImageFont
from os import makedirs, path, listdir
from glob import glob
import argparse
import numpy as np
import matplotlib.font_manager as fm
seed(1234) # 結果を再現できるようにするために乱数のシードを固定
def main(output_dir,check_name_list):
system_font_list = fm.findSystemFonts()
system_font_list = [font.replace('\\','/') for font in system_font_list]
# 文字化けするfontを除外
NG_FONT_LIST = ['BSSYM7.TTF','holomdl2.ttf','marlett.ttf','MTEXTRA.TTF','OUTLOOK.TTF','REFSPCL.TTF','segmdl2.ttf','symbol.ttf','TSPECIAL1.TTF','webdings.ttf','wingding.ttf','WINGDNG2.TTF','WINGDNG3.TTF','Webdings.ttf']
font_list = []
for font in system_font_list:
if font.split('/')[-1] not in NG_FONT_LIST:
font_list.append(font)
print(f'found fonts: {len(font_list)}')
print(font_list)
tmp_img_dir = './img/'
makedirs(tmp_img_dir, exist_ok=True)
seed(1234) # 結果を再現できるようにするために乱数のシードを固定
pixel_size = (700,50)
for text in check_name_list:
for i in range(5):
for font_path in font_list:
font = ImageFont.truetype(font_path, randint(20,30))
font = ImageFont.truetype(font_path, 30)
img = Image.new('L', (pixel_size[0],pixel_size[1]),(255))
d = ImageDraw.Draw(img)
d.text((0, 0), text, font=font, fill=(0))
# 描画部分だけ切り出し
img_array = np.array(img)
w,h=0,0
for j in range(pixel_size[0]-1,-1,-1):
if not (np.all(img_array[:,j]==255)):
w = j+1
break
for j in range(pixel_size[1]-1,-1,-1):
if not (np.all(img_array[j,:]==255)):
h = j+1
break
img_array = img_array[0:h,0:w]
max_pad_h = pixel_size[1] - img_array.shape[0]
max_pad_w = pixel_size[0] - img_array.shape[1]
pad_h = randint(0,max_pad_h)
pad_w = randint(0,max_pad_w)
# 真っ白なキャンバスを作成
canvas_array = np.ones((pixel_size[1],pixel_size[0]),dtype=np.uint8)*255
# 文字をランダムに移植
canvas_array[pad_h:pad_h+img_array.shape[0],pad_w:pad_w+img_array.shape[1]] = img_array
img = Image.fromarray(canvas_array)
file_path = tmp_img_dir + text.replace(' ','') + '_' +font_path.split('/')[-1] + str(i) + '.png'
img.save(file_path)
img_file_list = sorted(glob('./img/*.png'))
train_X = np.zeros((len(img_file_list),pixel_size[1],pixel_size[0]),dtype=np.uint8)
train_y = np.zeros((len(img_file_list)),dtype=np.float32)
for i,img_file in enumerate(img_file_list):
img = Image.open(img_file)
img_array = np.array(img)
train_X[i,:,:] = img_array
if check_name_list[1].replace(' ','') in img_file:
train_y[i] = 1
train_X = ((train_X-127.5)/127.5).astype(np.float32)
makedirs(output_dir, exist_ok=True)
train_X_path = path.join(output_dir,'train_X.npy')
train_y_path = path.join(output_dir,'train_y.npy')
print(f'train_x save: {train_X_path}')
np.save(train_X_path,train_X)
print(f'train_x save: {train_y_path}')
np.save(train_y_path,train_y)
if __name__=='__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--output-dir', type=str, default='/workspace/data')
parser.add_argument('--check-names', type=str,default="Amazon ElastiCache/Amazon ElasticCache")
args, _ = parser.parse_known_args()
check_name_list = args.check_names.split('/')
print(check_name_list)
main(args.output_dir,check_name_list)実行
呉「最後に実行だっ !」
$ docker run --rm -v $(pwd):/workspace amazon-redshift-police-generate-image:1 python3 generate_image.py --check-names "Amazon Redshift/Amazon RedShift" # ターン!!!確認
表記の比較
 (verdanaz フォントで正しい表記)
(Mono フォントで誤った表記)
(verdanaz フォントで正しい表記)
(Mono フォントで誤った表記)
学習用コンテナ作成
呉「よし、問題なく動いているな。あとはこれで学習だ。学習用のコンテナから作ろう。また Dockerfile をだな・・・」
FROM python:3.9-slim-buster
RUN apt-get -y update && \
apt-get -y upgrade
WORKDIR /workspace
COPY requirements.txt /workspace
RUN pip3 install -r requirements.txt
ENV PYTHONUNBUFFERED=TRUErequirements.txt
呉「あとは TensorFlow の準備だ。」
tensorflow==2.6.2トレーニングイメージのビルド
呉「よし、トレーニング用のイメージをビルドするぞ。」
$ docker build -t amazon-redshift-police-train-image:1 .
Sending build context to Docker daemon 3.584kB
…(中略)…
Successfully built 0123456789ab
Successfully tagged amazon-redshift-police-train-image:1train.py
呉「ビルドも一発で通ったな。やはり完全に理解している。あとはトレーニングコードを用意して・・・」
import numpy as np, argparse, os
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, PReLU, Dense, BatchNormalization, MaxPool2D, Flatten
from tensorflow.keras.optimizers import Adam
def main(args, train_X, train_y):
inputs = Input(shape=(50,700,1))
x = Conv2D(64, (3,3),padding='same')(inputs)
x = BatchNormalization()(x)
x = PReLU()(x)
x = MaxPool2D(pool_size=(2, 2))(x)
x = Conv2D(64, (3,3),padding='same')(x)
x = BatchNormalization()(x)
x = PReLU()(x)
x = MaxPool2D(pool_size=(2, 2))(x)
x = Conv2D(64, (3,3),padding='same')(x)
x = BatchNormalization()(x)
x = PReLU()(x)
x = MaxPool2D(pool_size=(2, 2))(x)
x = Conv2D(64, (3,3),padding='same')(x)
x = BatchNormalization()(x)
x = PReLU()(x)
x = MaxPool2D(pool_size=(2, 2))(x)
x = Conv2D(64, (3,3),padding='same')(x)
x = BatchNormalization()(x)
x = PReLU()(x)
x = MaxPool2D(pool_size=(2, 2))(x)
x = Flatten()(x)
x = Dense(128)(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs=inputs, outputs=x)
model.summary()
model.compile(optimizer=Adam(learning_rate=0.0001),metrics=['accuracy'],loss="binary_crossentropy")
model.fit(train_X,train_y,batch_size=16,epochs=args.epochs)
save_model_path = os.path.join(args.sm_model_dir, '000000001')
os.makedirs(args.sm_model_dir, exist_ok=True)
model.save(save_model_path)
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--sm-model-dir', type=str)
parser.add_argument('--train', type=str)
parser.add_argument('--epochs', type=int, default=1)
return parser.parse_known_args()
def load_training_data(base_dir):
"""Load MNIST training data"""
print(os.path.join(base_dir, 'train_X.npy'))
train_X = np.load(os.path.join(base_dir, 'train_X.npy'))
train_y = np.load(os.path.join(base_dir, 'train_y.npy'))
return train_X, train_y
if __name__=='__main__':
argv = argparse.ArgumentParser()
args, unknown = parse_args()
print(args.train)
print(os.listdir(args.train))
train_X, train_y = load_training_data(args.train)
main(args, train_X, train_y)
exit()学習の実行
呉「学習の実行だ ! あとで GPU で動かすからとりあえず動作確認だな。Epoch を 1 で動かして動作するか確認だけして、あとは林さんに GPU で動かすところは任せちゃおう」
$ docker run --rm -v $(pwd):/workspace amazon-redshift-police-train-image:1 python3 train.py --sm-model-dir "model" --train "data" --epochs 20 # ターン!!!
…(中略)…
Epoch 20/2044/44 [==============================] - 58s 1s/step - loss: 0.8272 - accuracy: 0.5186確認
呉「こちらも前回のをほぼ流用したから一発で動いたな。簡単簡単。あとは GPU でうごかしてちゃんと学習すればいけるはず。大丈夫だと思うけど念の為モデルが動くかテストしておくか。前回はテストの画像を別途作ったけど、どうせ動くから学習データでの動作確認だけにしちゃおう。」 なんと、データサイエンティストの端くれにも関わらず過学習の放置や評価データの作成をサボるだけでなくついにテストデータすら用意しなくなってしまいました。 呉「コンテナに入って確認しようかな。」 呉「よし、間違えてはいるもののとりあえず問題なく動いているぞ。よしあとは林さんに手をスリスリしながら GPU で動かしてもらおう。そういえば Epoch がいくつならちゃんと動くのかもしりたいし、なんなら Amazon Redshift 以外にも使えるようにしたいな。なーに、林さんならいい感じにやってくれるさ。ちょうどいいところに林さんがいた。呼んじゃおう。おーいハヤシモーン ! 助けてくれー !」 まるで猫型ロボットを呼びつけるかのように林さんを呼ぶ呉であった・・・。
$ docker run -it -v $(pwd):/workspace amazon-redshift-police-train-image:1 bash
root@0123456789ab:/workspace# python3
>>> import tensorflow as tf
>>> import numpy as np
>>> train_X = np.load('data/train_X.npy')
>>> train_y = np.load('data/train_y.npy')
>>> model = tf.keras.models.load_model('./model/000000001/')
>>> for i in range(train_X.shape[0]):
... pred_y = 0 if model.predict(train_X[i:i+1,:,:]) < 0.5 else 1
... if pred_y==train_y[i]:
... print('OK')
... else:
... print('NG')
...
OK
OK
NG
…中略…
NG第 4 章 : Amazon Elastic Container Service (Amazon ECS) でオンプレミスにあるコンピュータにジョブをばらまく
林「そういえば機械学習スペシャリストの呉さんは GPU 作っている会社の株を大量に買い付けて一攫千金だと聞きましたが、今度いっしょにお寿司行ってもいいですか ?」
呉「(間違って株じゃなくて GPU を買ってしまったことなど言えない・・・!) ええ、もちろんです。なんなら宇宙に寿司でもデリバリーしましょうか ? そしたらちゃんと “宇宙で寿司なう” ってつぶやいてくださいよ ? ところで配当で大量に GPU のマシンを買ったんですが、せっかくなのでこれを有効活用して Amazon RedShift 撲滅プロジェクトを進めているんですね。」
呉は嘘に嘘を重ねる悪手を選んでしまいました。
林「なるほど、Redshift 撲滅プロジェクト (アナリティクスにトラウマでもあるのかな ?)」
呉「いや、 Redshift は撲滅しないんですが、ほら、前回の Amazon ElastiCache 警察のかくかくしかじか。」
林「完全に理解した、このコードを呉さんの GPU で実行すればお寿司をもらえるということですね。」
呉「全然違います。」
林「そういえば、 Amazon ECS ってオンプレミスのマシンを登録してコンテナ実行できる Anywhere っていう機能 があるんですよね。ここにちょうど、私のラズパイを登録した ECS クラスターがあります ! 上記のコードもコンテナになっているし、ここに呉さんの GPU 激積みマシンも登録すれば AWS のコンソールでポチポチするだけで実行できるし仮想通貨も掘れますよ !」
呉「AWS コンソールでポチポチするだけで、私の部屋にあるこのマシンで機械学習も実行できるし仮想通貨も掘れるんですね ! すばらしい ! ではお願いします !!」
林「はい ! ちょっと準備するのでお寿司のお店を選びながらお待ちください。」
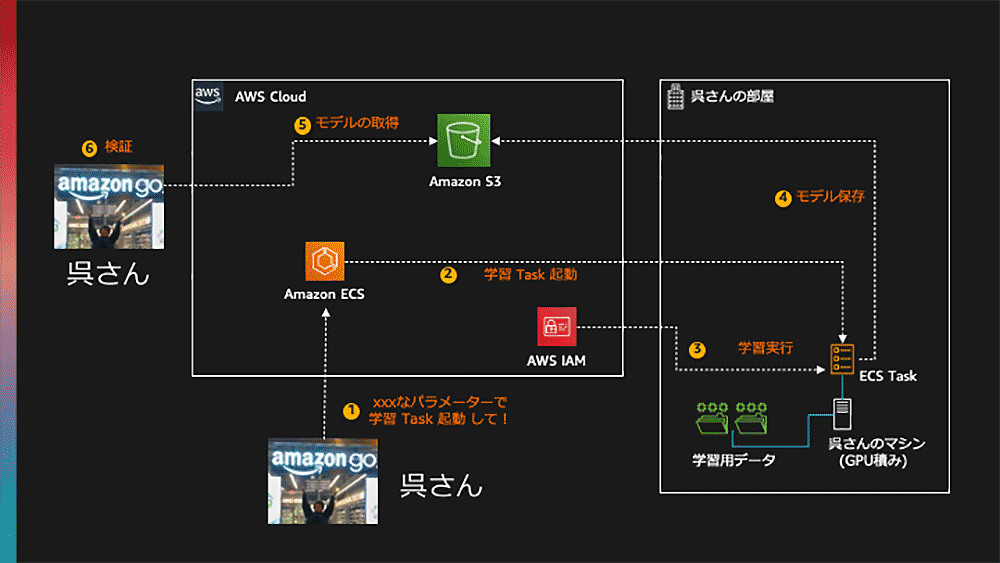
というわけで、呉さんのマシンでマイニン・・・、じゃない Redshift 警察の学習コードを実行できるようにしてみましょう。ざっくり以下のような環境を構築することになりそうです。
作成する環境
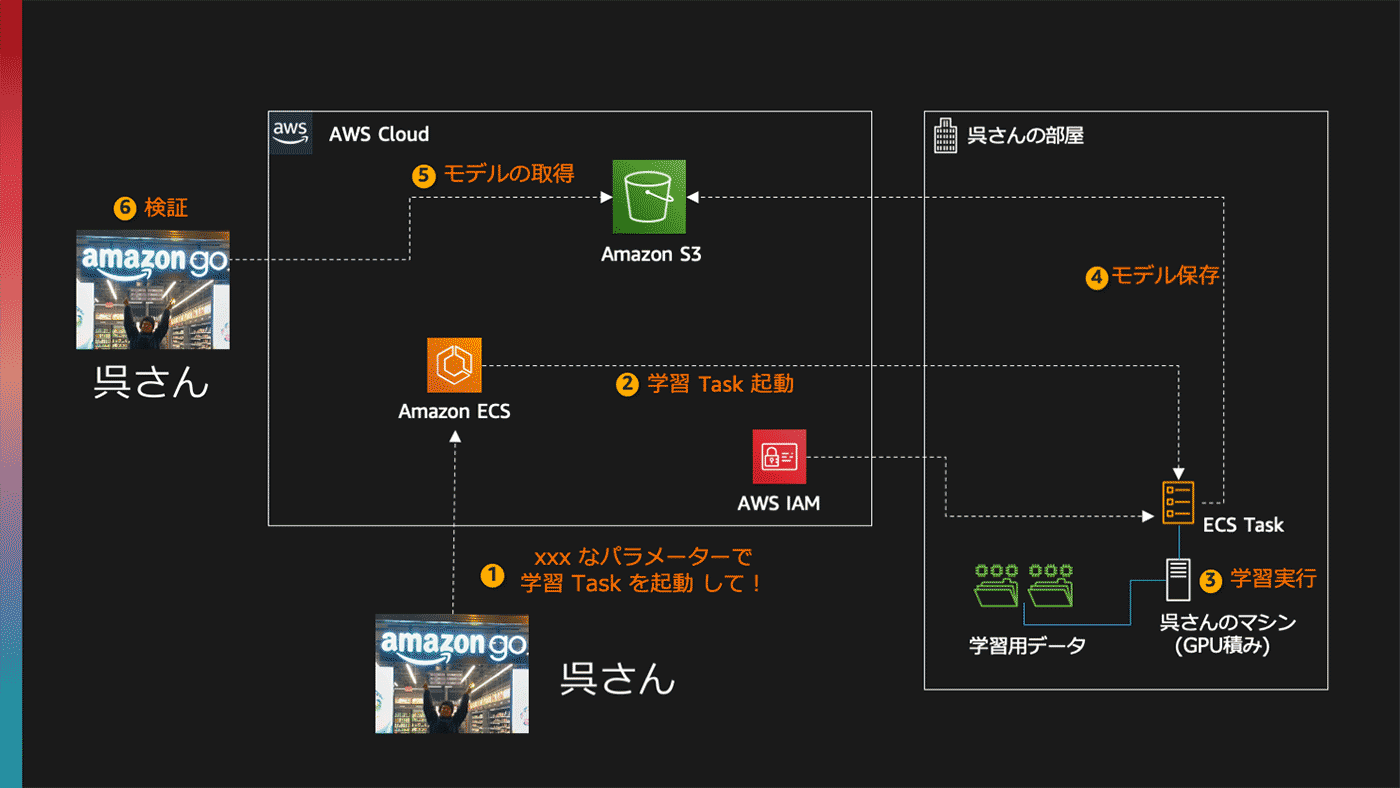
マシンの登録
まず、ECS に GPU 激積みマシンを登録しましょう。 ECS の管理コンソールから「Externalインスタンスの登録」を選ぶと、マシンを ECS に登録するためのコードが表示されます。
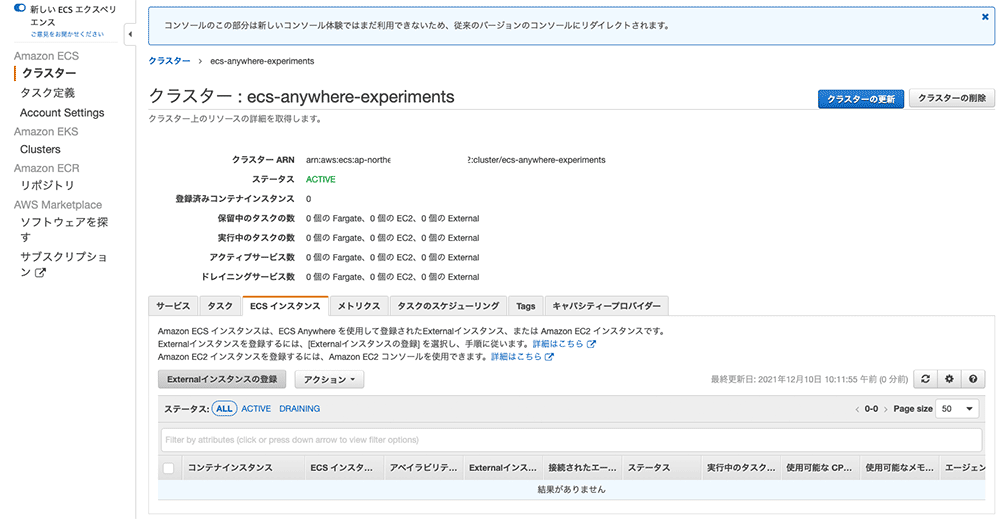
登録方法
今回は、GPU マシンを登録するので、最後に、 --enable-gpu オプションを付ける必要があります。ここだけ注意点ですね。
curl --proto "https" -o "/tmp/ecs-anywhere-install.sh" "https://amazon-ecs-agent.s3.amazonaws.com/ecs-anywhere-install-latest.sh" && \ bash /tmp/ecs-anywhere-install.sh \ --region "ap-northeast-1" \ --cluster "ecs-anywhere-experiments" \ --activation-id "xxxx" --activation-code "xxx" \ --enable-gpu登録確認
このコマンドを、呉さんの GPU マシンで実行するだけで、ECS のクラスターに外部インスタンスとして登録されます。
ここまでの作業により、ECS でタスクを起動することで呉さんのマシンでコンテナが実行されるようになりました。
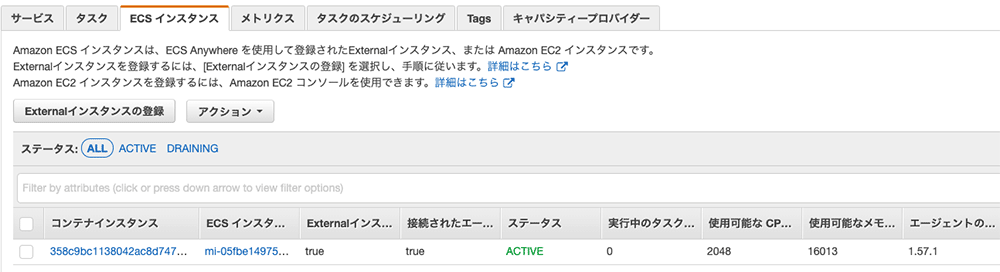
Dockerfile の修正
さて、今回は、GPU でコードを実行するので、CUDA などもろもろ設定された TensorFlow の公式イメージを使おうと思います。なので、呉さんの Dockerfile を以下のように修正しました。
FROM tensorflow/tensorflow:latest-gpu
WORKDIR /workspace
COPY src /workspace
ENV PYTHONUNBUFFERED=TRUEレジストリ登録
コンテナをビルドして、レジストリに登録します。
# Docker イメージのビルド
$ docker build -t amazon-redshift-police-train-image .
# ECR レジストリに ログイン
$ aws ecr get-login-password --region ap-northeast-1 | docker login \
--username AWS \
--password-stdin <AWS_ACCOUNT_ID>.dkr.ecr.ap-northeast-1.amazonaws.com
$ aws ecr create-repository --repository-name amazon-redshift-police-train-image
$ docker tag amazon-redshift-police-train-image:latest \
<AWS_ACCOUNT_ID>.dkr.ecr.ap-northeast-1.amazonaws.com/amazon-redshift-police-train-image:latest
$ docker push <AWS_ACCOUNT_ID>.dkr.ecr.ap-northeast-1.amazonaws.com/amazon-redshift-police-train-image:latestデータ場所の確認
このコンテナが学習用のデータを読み込めるようにしないといけないですね。データをコンテナに入れるとイメージのサイズも大きくなるし、面倒なので、コンテナが起動する呉さんのマシンにデータを置いてもらって、そのディレクトリをコンテナにマウントして使いましょう。マウントの設定は後のステップで実行するので、ここではデータの場所だけ確認しておきます。
ちなみに、 ECS の外部インスタンスは、 AWS Systems Manager (SSM) のマネージドインスタンスとしても登録されるので、追加の料金が必要になりますが、SSH のポートを空けずとも AWS のマネージメントコンソールや AWS CLI を使ってセキュアに接続 することができます。
確認コマンド
コマンド / コード
$ aws ssm start-session --target mi-xxxxx # ECS に登録した呉さんのマシン
# 学習データの場所を確認
$ ls /opt/ml/train-data | head -n 10
train_X.npy
train_y.npy
AmazonRedshift_Andale_Mono.ttf1.png
AmazonRedshift_Andale_Mono.ttf2.png
AmazonRedshift_Andale_Mono.ttf3.png
AmazonRedshift_Andale_Mono.ttf4.png
AmazonRedshift_andalemo.ttf0.png
AmazonRedshift_andalemo.ttf1.png
AmazonRedshift_andalemo.ttf2.png
AmazonRedshift_andalemo.ttf3.png
AmazonRedshift_andalemo.ttf4.pngタスク定義の登録

タスク定義
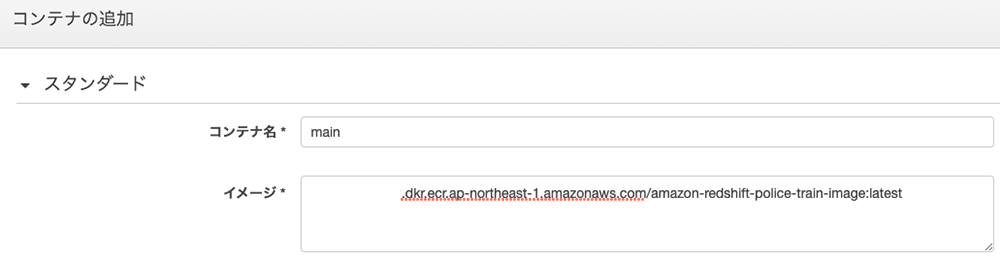
実行
ここで鍵になるのは、GPU を指定することです。これで、起動したタスクが GPU のある呉さんのマシンにスケジュールされるようになります。
ひとまずコンテナに入って学習処理を実行してみたいので、単に tail -f /dev/null してコンテナを立ち上げっぱなしにするだけのコマンドを入れています。
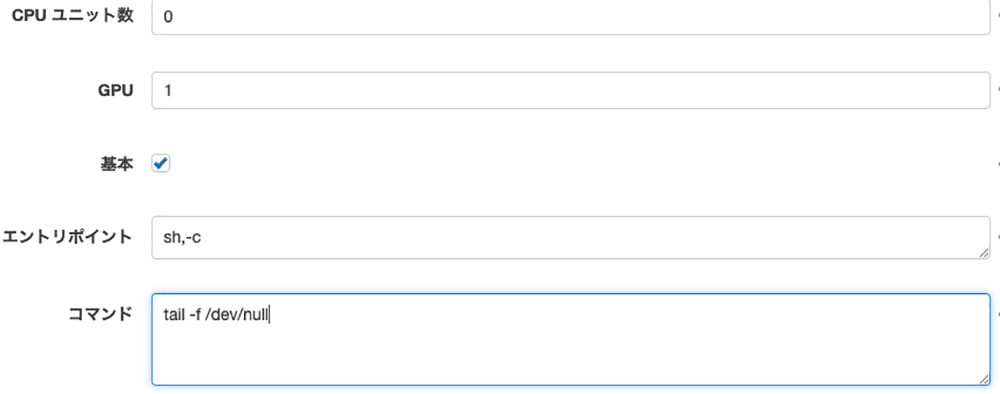
ログ設定
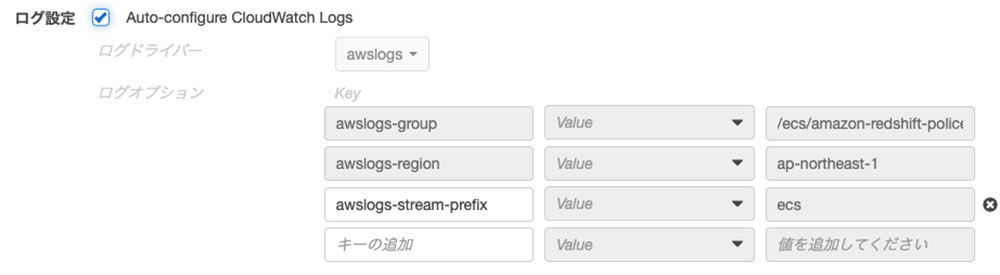
ボリューム追加
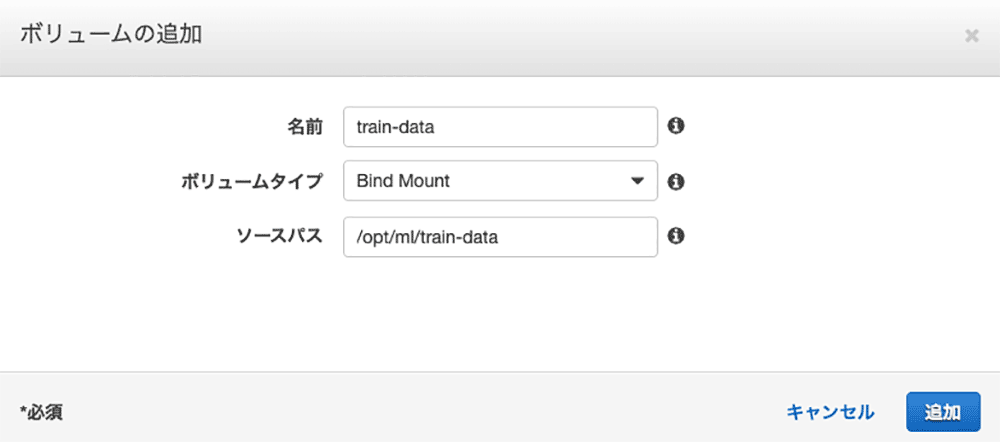
マウント
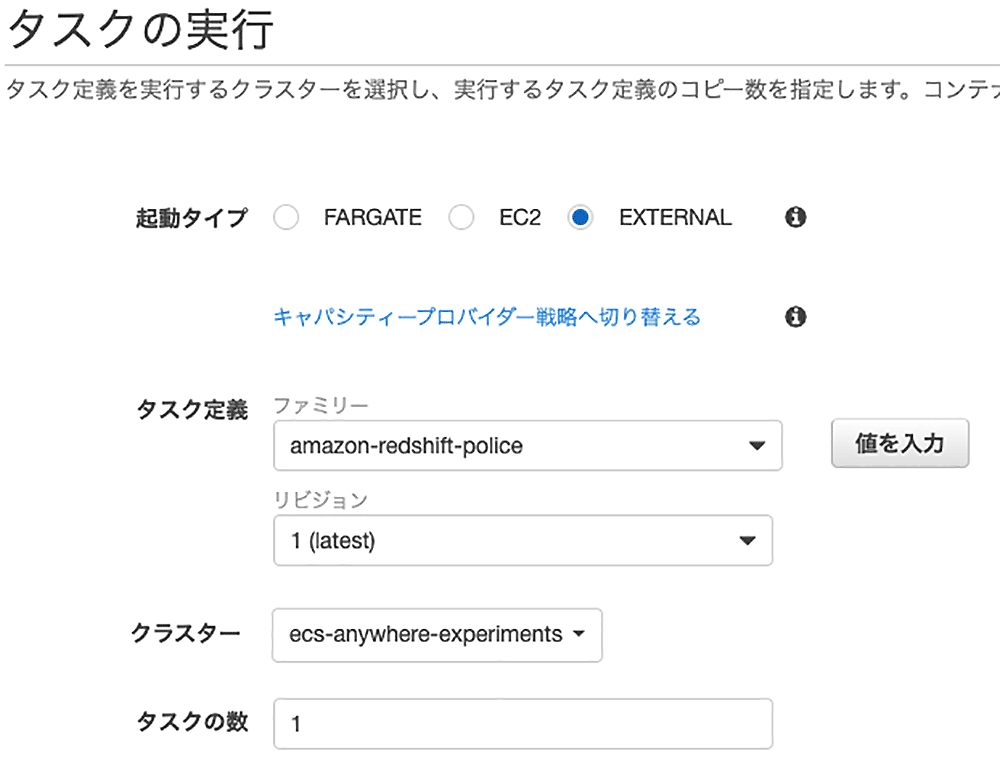
タスクを起動
タスク定義ができました ! このタスクを ECS から起動すれば、呉さんのマシンで学習用のコンテナが起動するはずです !さっそく、クラスターの画面からタスクを起動してみましょう。
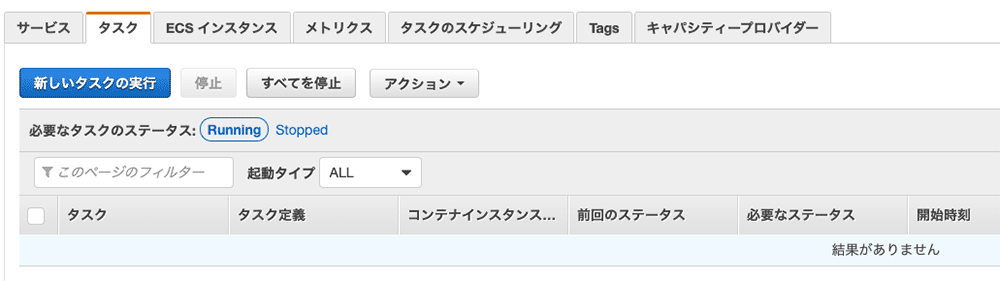
ステータス確認
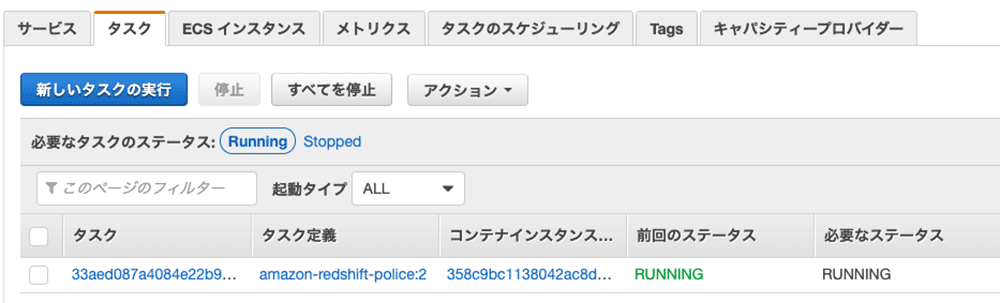
起動確認
確認コマンド
コマンド / コード
# SSH で Session Manager を利用する設定
$ vim ~/.ssh/config
...
host i-* mi-*
ProxyCommand sh -c "aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p'"
$ ssh mi-xxxxx # ECS に登録した呉さんのマシン
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0eb234dc5c1d <ACCOUNT_ID>.dkr.ecr.ap-northeast-1.amazonaws.com/amazon-redshift-police-train-image:latest "sh -c 'tail -f /dev…" 5 hours ago Up 5 hours ecs-amazon-redshift-police-2-main-e8f5c1b8dc8692c4be01
89be63ca2f8b amazon/amazon-ecs-agent:latest "/agent" 10 hours ago Up 10 hours (healthy) ecs-agentGPU 確認
無事、ECS からコンテナが起動していますね。GPU は無事、認識しているでしょうか ?
# 最後に起動したコンテナのIDを取得
$ container_id=$(docker ps -l -q)
# コンテナに入る
$ docker exec -it $container_id bash
# ECSでデプロイしたコンテナからGPUが認識されているか確認
# https://www.tensorflow.org/guide/gpu?hl=ja
root@xxxx:/workspace# python
Python 3.8.10 (default, Sep 28 2021, 16:10:42)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow as tf
>>> print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
2021-12-12 09:37:59.533492: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:939] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-12-12 09:37:59.538847: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:939] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-12-12 09:37:59.539152: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:939] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
Num GPUs Available: 1学習コードを実行
無事、認識されているようですね。ここで、そのまま呉さんの学習コードを実行してみましょう。
root@xxx:/workspace# python train.py --sm-model-dir /opt/ml/model --train /opt/ml/train-data --epochs 2
/opt/ml/train-data
['train_y.npy', 'train_X.npy']
/opt/ml/train-data/train_X.npy
2021-12-12 10:20:48.438579: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:939] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-12-12 10:20:48.443341: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:939] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-12-12 10:20:48.443664: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:939] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-12-12 10:20:48.444110: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-12-12 10:20:48.444390: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:939] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-12-12 10:20:48.444680: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:939] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-12-12 10:20:48.444971: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:939] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-12-12 10:20:48.890222: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:939] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-12-12 10:20:48.890716: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:939] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-12-12 10:20:48.890982: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:939] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-12-12 10:20:48.891209: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1525] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 2645 MB memory: -> device: 0, name: NVIDIA GeForce GTX 1650, pci bus id: 0000:03:00.0, compute capability: 7.5
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 50, 700, 1)] 0
conv2d (Conv2D) (None, 50, 700, 64) 640
....
2021-12-12 10:20:51.770278: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.04GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2021-12-12 10:20:51.793564: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.54GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2021-12-12 10:20:51.793696: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.54GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
43/44 [============================>.] - ETA: 0s - loss: 0.8287 - accuracy: 0.50732021-12-12 10:20:57.418992: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.41GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2021-12-12 10:20:57.419309: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.41GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2021-12-12 10:20:57.704713: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.04GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2021-12-12 10:20:57.704974: W tensorflow/core/common_runtime/bfc_allocator.cc:275] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.04GiB with freed_by_count=0. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
44/44 [==============================] - 9s 137ms/step - loss: 0.8250 - accuracy: 0.5114
Epoch 2/2
44/44 [==============================] - 5s 123ms/step - loss: 0.6399 - accuracy: 0.6443
2021-12-12 10:21:11.146102: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.モデルを保存
アクセス権限を付与
ECS Anywhere は、オンプレミスで実行しているコンテナに AWS の IAM ロールをアタッチするという機能 が使えるので、それを活用することにします。 さっそく、実行中のタスクのタスクロールに S3 へのアクセス権限を付与しましょう。以下のようなポリシーを作って、タスクロールにアタッチしてみました。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::amazon-redshift-police"
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": "arn:aws:s3:::amazon-redshift-police/*"
}
]
}モデルをアップロード
これで、コンテナからモデルを S3 にアップロードできるはず・・・
root@xx:/workspace# tar czf amazon-redshift-police-model.tar.gz -C /opt/ml/model .
root@xx:/workspace# aws s3 cp ./amazon-redshift-police-model.tar.gz s3://amazon-redshift-police-model
bash: aws: command not foundDeep Learning 用コンテナイメージ
って、そういえば TensorFlow 公式イメージには awscli が入っていないんだった・・・。
ここで、AWS からリリースされている Deep Learning 用のコンテナイメージ の出番です。このコンテナイメージなら TensorFlow もセットアップされているし、AWS CLI も入っていますので今回の用途には便利ですね。
Dockerfileを修正して・・・
Dockerfile の修正
コマンド / コード
# FROM tensorflow/tensorflow:latest-gpu
# 以下から最新のイメージを取得
# https://github.com/aws/deep-learning-containers/blob/master/available_images.md#general-framework-containers-ec2-ecs-eks--sm-support
FROM 763104351884.dkr.ecr.ap-northeast-1.amazonaws.com/tensorflow-training:2.6.2-gpu-py38-cu112-ubuntu20.04
WORKDIR /workspace
COPY src /workspace
ENV PYTHONUNBUFFERED=TRUEPush
で、Push と。
# Deep Learning コンテナの ECR レジストリにログインしておく
$ aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin 763104351884.dkr.ecr.ap-northeast-1.amazonaws.com
# Docker イメージのビルド
$ docker build -t amazon-redshift-police-train-image .
$ docker tag amazon-redshift-police-train-image:latest \
<AWS_ACCOUNT_ID>.dkr.ecr.ap-northeast-1.amazonaws.com/amazon-redshift-police-train-image:latest
$ docker push <AWS_ACCOUNT_ID>.dkr.ecr.ap-northeast-1.amazonaws.com/amazon-redshift-police-train-image:latest再度起動
これで、レジストリのコンテナイメージが更新されましたので、一度 ECS からタスクを落としてもう一回起動してみます。今度は問題なく動作するでしょうか・・・
$ container_id=$(docker ps -l -q)
$ docker exec -it $container_id bash
# ECSでデプロイしたコンテナからGPUが認識されているか確認
# https://www.tensorflow.org/guide/gpu?hl=ja
root@xxxx:/workspace# python
>>> import tensorflow as tf
>>> print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
...
Num GPUs Available: 1
>>> exit()
root@xxxx:/workspace# python train.py --sm-model-dir /opt/ml/model --train /opt/ml/train-data --epochs 2
...
44/44 [==============================] - 13s 215ms/step - loss: 0.8800 - accuracy: 0.4943
Epoch 2/2
44/44 [==============================] - 6s 133ms/step - loss: 0.6099 - accuracy: 0.6700
2021-12-12 11:47:42.795666: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
INFO:tensorflow:Assets written to: /opt/ml/model/000000001/assets
root@xx:/workspace# tar czf amazon-redshift-police-model.tar.gz -C /opt/ml/model .
root@xx:/workspace# aws s3 cp ./amazon-redshift-police-model.tar.gz s3://amazon-redshift-police-model
upload: ./amazon-redshift-police-model.tar.gz to s3://amazon-redshift-police/amazon-redshift-police-model.tar.gz実行
よしよし、これで GPU でモデルを学習して、S3に アップロードすることができましたね! 良い感じのEpoch とかはよくわからんので、パラメーター指定してバッチ起動できるようにして、後は呉さんにお願いしてやってもらいましょう。 ECS の run-task コマンドでタスクを起動するようにして、さらに実行するコマンドを上書きできるようにするとよさそうですね。run-task コマンドは overrides パラメーターでタスク定義の実行パラメーターを上書きできるので、これでやってみましょう。
# タスク定義の上書き内容をJSONで指定する
# 今回は、コンテナで実行するコマンドを、 tail -f /dev/null ではなく、学習コードを実行してS3に保存するコードに上書きする
$ vim override.json
{
"containerOverrides": [
{
"name": "main",
"command": [
"python train.py --sm-model-dir /opt/ml/model --train /opt/ml/train-data --epochs 2 && tar czf amazon-redshift-police-model.tar.gz -C /opt/ml/model . && aws s3 cp ./amazon-redshift-police-model.tar.gz s3://amazon-redshift-police"
]
}
]
}
# 上記のJSONを指定してタスクを起動する
$ task_arn=arn:aws:ecs:ap-northeast-1:<ACCOUND_ID>:task-definition/amazon-redshift-police:xx
$ aws ecs run-task --cluster ecs-anywhere-experiments \
--task-definition $task_arn \
--launch-type EXTERNAL \
--overrides "file://override.json"
{
"tasks": [
{
"attachments": [],
"attributes": [
{
"name": "ecs.cpu-architecture",
...
# モデルがS3にアップロードされているか確認する
$ aws s3 ls s3://amazon-redshift-police
2021-12-09 15:35:10 27190018 amazon-redshift-police-model.tar.gz実行できるようになりました !
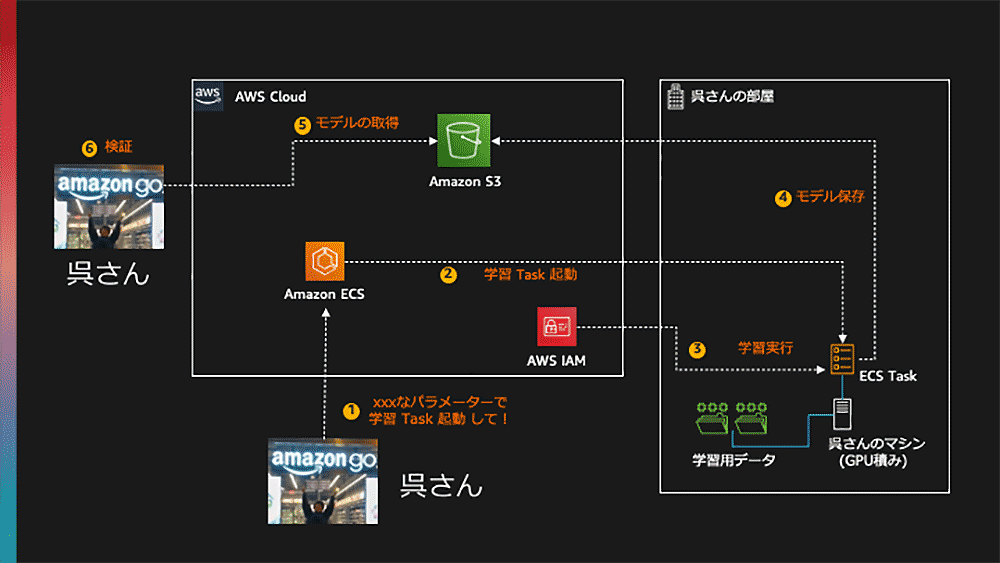
成功後の 二人の会話
林「と、いうわけで、今や AWS CLI を叩くだけで学習コードが呉さんの GPU マシンで走るようになったわけです。」
呉「マジですか、例えば epoch を変えて検証したい場合はどうするのがいいです ?」
林「override.json ファイルを書き換えて aws ecs run-task するだけですね(ドヤァ… モデルは S3 にアップロードされるので、そのモデルで検証しても良いし、 override.json の中で検証コードいれてもいいかもしれないです)」
呉「ふむふむ、そして、Redshift でない別の文字列でやりたい場合も、コンテナイメージのコードを修正して、 override.json の実行コマンドでパラメーターを渡してやれば対応できそうですね !」
林「例え南の島でワーケーションしてても、 AWS のコンソールとか AWS CLI でタスクを実行さえすれば、部屋にある GPU マシンで機械学習が実行される・・・素晴らしい・・・」
呉「この冬の暖房としても役に立ちそうですね!AWS CLI がエアコンのリモコンになる日が来るとは・・・! 入タイマーとしても切タイマーとしても使えそうです。」
林「(・・・何言ってんだろこの人)」
エピローグ
呉「こんな感じで、ECS Anywhere を使って機械学習を実行してみたわけですが、まとめるとどんなメリットがありそうでしょうか ?」
林「そうですねー機械学習で一番大きいのは、ECS が、GPU リソースが空いているマシンにコンテナを自動的にスケジュールしてくれることかなと思いました。呉さん、配当でもらった膨大な GPU マシンがあるわけですが、どこのマシンで GPU が空いているのがチェックしてコンテナを割り当てるような仕組みは結構面倒ですからね。」
呉「(無配当・・・! 圧倒的無配当・・・! 株など買っていなかった・・・!) なるほどーあと、今回みてみると、AWS との連携がスムーズというのもありましたね。」
林「オンプレミスのコンテナに、 AWS の IAM で権限を設定できるのは便利なポイントですね。今回だと S3 へのアップロードも IAM で設定できましたし、何気に CloudWatch Logs へのコンテナログの送信も行えていたんですよね。」
呉「他にも、SSH などでオンプレミスのマシンに入る必要がない、というのもいいですね。AWS のコンソールや CLI でタスクを実行する環境さえあれば、どこにいてもオンプレミスのマシンでワークロードを実行できる、というのは権限管理の面でもセキュアだし、利便性も高いと思いました !」
林「最後に Amazon Redshift という新しいネタをふってくれた 大薗さん が、次は AWS Glue で、と言ってこないか心配ですが、今回はこの辺で。」
林・呉「今年もよろしくおねがいします。ありがとうございましたー。」
筆者プロフィール

呉 和仁
アマゾン ウェブ サービス ジャパン合同会社
機械学習ソリューションアーキテクト。 IoT の DWH 開発、データサイエンティスト兼業務コンサルタントを経て現職。
プログラマの三大美徳である怠惰だけを極めてしまい、モデル構築を怠けられる AWS の AI サービスをこよなく愛す。

林 政利
アマゾン ウェブ サービス ジャパン合同会社
コンテナスペシャリスト ソリューションアーキテクト フリーランスや Web 系企業で業務システムや Web サービスの開発、インフラ運用に従事。近年はベンダーでコンテナ技術の普及に努めており、現在、AWS Japan で Amazon ECS や Amazon EKS でのコンテナ運用や開発プロセス構築を中心にソリューションアーキテクトとして活動中。
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages