- AWS Builder Center
- builders.flash
オンプレミスで動くアプリケーションを SaaS へ移行させる際のよもやま話 ~前編 : SaaS 移行の事始め
2022-05-02 | Author : 関根 正夫 (株式会社網屋)
はじめに
こんにちは。株式会社網屋でソフトウェア開発を行っている関根と申します。
本稿では、オンプレミスで動く弊社のスタンドアローンなアプリケーションをSaaS (AWS) 版として移行させた際に、私たちが開発においてどのような変遷をたどったのか、またその時に躓いた点をお送りしたいと思っております。
今回 SaaS 移行のターゲットになったのは、弊社製品の「ALog ConVerter」になります。お勉強という軽いオーダーから始まった今回のプロジェクトだったのですが、気がつくと本格的な開発に突入していました。多分これをご覧の開発者の皆さんも、こんな性急なプロジェクトのご経験があるとは思いますが、「これから自社ソフトウェアを SaaS へ移行したい」と命題を抱えた皆様に何かしらかの助力になればと思います。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
最初の一歩
ALog ConVerter はオンプレミス環境で WindowsService としてサーバーで常駐・動作する Windows のプログラムです。本製品では、Windows サーバー上から他のサーバーやプロセスで発生した監査ログを収集・変換し、その結果を用いてユーザーに検索・レポート発行する機能を提供します。
本製品の SaaS 化に向けて最初に検討に上がったのは、「Windows サーバーインスタンスをクラウド上で起動し、本プログラムをインストール常駐した状態で提供する」という、いわゆる「サイロモデル」のアプローチでした。
しかし、「未来を見据えた場合にオペレーション負荷が大きいこと、加えてコストが高止まりになる」という観点から、本件ではこの「単純なサイロ化」のアプローチに難色がありました。
脱「単純なサイロモデル」を考える
とはいえ、サイロモデルには「隔離」の点でメリットもありました。
ここでいう「隔離」とは、
-
データの隔離
複数のテナント間における「データ」の隔離を行うこと。本製品の場合は、各テナントから収集した監査ログの保存などがこれにあたります。セキュリティインシデントの発生を防ぐ事、データストレージの利用量などをテナントで分離する事等が目的にあげられます。 -
プロセスの隔離
ノイジーネイバーにみられる、「各テナントにおけるプロセス負荷のばらつき」から発される問題を分離します。また各テナントのプロセスが分離することにより、課金などの処理を行う際の各テナントの集計が容易になるとも考えました。
このような「サイロモデル」におけるメリットも享受したいという所から、私たちはオンプレミス版の構造を整理し、クラウド上でどのような構成にしていけばよいのか ? という所から考えはじめました。
オンプレミス版の本アプリケーションはざっくりと以下のコンポーネントで構成されています。
-
Web サーバー
従前の Web アプリケーションに見られる一般的な形をしており、本体が起動すると同時に Web サーバーとして動作をします。そして、その内部では下記ビジネスロジックをホストしています。 -
ビジネスロジック (WebAPI)
本記事では所謂 WebAPI (アプリケーション層) を総じてビジネスロジックと称します。これは後述の「バッチタスク」との色分けを行う為です。主に永続層へのデータの読書き、あるいはバッチタスクを動作させるためのトリガーや軽微な前・後処理などが該当します。 -
永続層 (アプリケーション設定ストア)
アプリケーション動作時に必要な設定群、あるいはアプリケーションログ (ユーザー操作・プロセス動作・統計情報) などを保存する層を指します。この層で扱うデータ群はビジネスロジックで読み書きされ、バッチタスクの中で実行コンテキスト (バッチの設定入力) として扱われたりします。 -
バッチタスク (収集、変換、レポート作成処理等)
ALog ConVerter では上記ビジネスロジックとは別に、コンカレントにバックグラウンドで動作するプロセスとして、バッチタスクが存在します。厳密にはこれもビジネスロジックの一つではあるのですが、上記に挙げるビジネスロジックのようにプレゼンテーション層とのつなぎとして動作する軽微なロジックとは異なり、収集・変換・レポート作成処理等に見られる、処理に時間がかかり、処理データ量も多いプロセスを指します。この部分が製品のプロセスマジョリティとなっています。 -
ログ検索エンジン
上記バッチタスクと比類して、収集した監査ログの検索・レポート作成を行う事に特化された検索エンジンです。これも上記のビジネスロジックとは異なるインスタンスとして動作します。本エンジンはビジネスロジックやバッチタスクから利用されます。 -
データストレージ (監査ログファイル群)
各サーバーやサービスから取得した監査ログ、あるいはサービスの出力結果等を保存する層になります。広義的には永続層ですが、本記事では上記永続層とは意味合いが異なりより純な「データストレージ」としての役割を指します。
オンプレミス版では、これらコンポーネントは 1 つのサーバーマシンで混然一体となって動作しています。SaaS 版で重要だったのは、この構成中のどのコンポーネントが「マルチテナント化において分離が必要なのか ?」という点でした。そこで私達は以下のように、処理内容・処理量で大まかに 2 つのブロックに分離するようにしました。
-
処理内容が軽い・データ量が少ない
-
WebAPI で処理される簡易な処理
-
永続層へのアプリケーションパラメータの書き込み
-
-
処理内容が重い・データ量が多い
-
バッチタスク (収集処理、変換処理、レポート作成処理等)
-
ログ検索エンジン (検索処理、レポート作成処理の内部集計処理)
-
データストレージ (監査ログファイル群・サービスの出力結果)
-
「処理内容が重い・データ量が重い」部分に関しては、複数アカウント (テナント) にて実行時間・処理量が違う為「プロセスの分離」をする必要性、またユーザーからお預かりする機密対象のデータとそのデータの保存量の大小を勘案し「データの分離」をする必要性があったからです。その他のいわゆる Web サービスの部分などの「処理内容が軽い・データ量が少ない」部分に関してはプールモデルを採用しプロセスの集約を行う事で、そのメンテナンスも簡便になると踏んだのです。

上記の分離における管理・企業のプロセスに対して、AWS のアカウントを割り当てています。この利点は、各 AWS サービスのクォータ (利用制限) をアカウント毎で緩和しやすい事 (もしプールモデルであればシステム全体で 1 アカウントのクォータが適応されてしまうため)、データ分離における「システム的・セキュリティ的境界線」をイメージしやすくなる事が挙げられます。
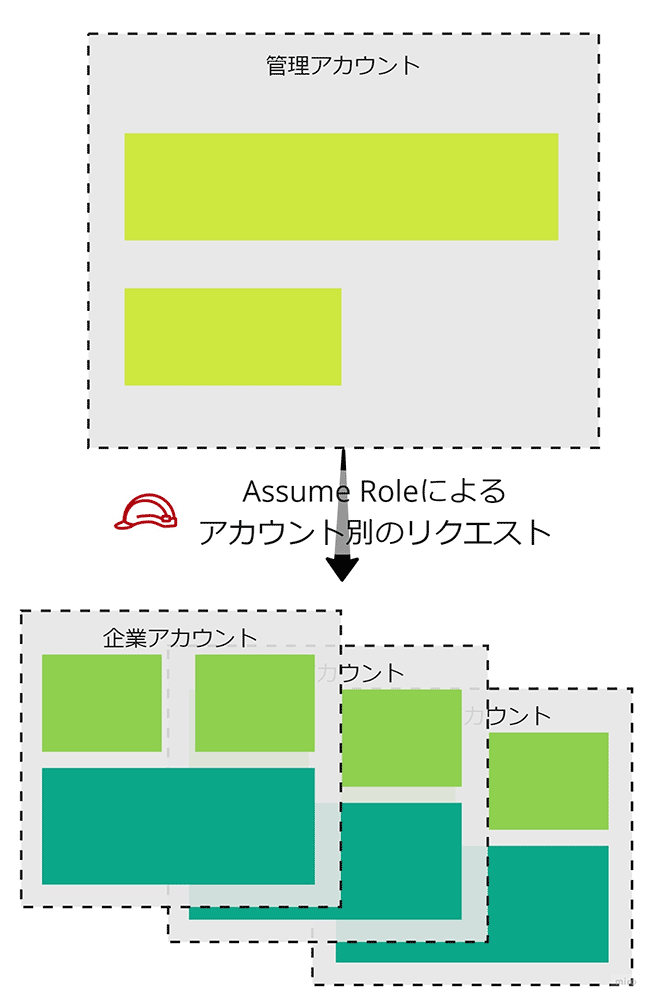
今回私たちは、プールモデルでプロセスを共通化した部分を「管理アカウント」とし、サイロモデルのように各テナント部分を「企業アカウント」とデザインをしました。
実際の AWS への対応
「どのコンポーネント」をサイロ化し、どの部分をプールモデルにするのか決定後、AWS が提供する数多なサービスを、これらの処理ブロックに合わせてどう選択するか検討を始めました。私たちはその当時、AWS が全く分からずの状況でスタートした事もあり、SaaS におけるサーバーリソースの運用管理に関して知見を持ち合わせておりませんでした。
また今後、サービス規模が大きくスケールしている未来を考え、極力「サーバーレスなサービスを軸に構築を考えよう」と、処理は以下のようなサービスによる構成で賄おうと考えました。
| 部位 | AWS サービス | 説明 |
| ビジネスロジック | Amazon ECS | Web ホスティングを行うため、必要に応じてインスタンスの増減などが発生するので ECS を利用 |
| 永続層 | Amazon RDS (Aurora) | 従来のプログラムからのクエリの移行やトランザクションを考え、RDS (Aurora) を利用 |
| バッチタスク | AWS Lambda | タスクそのものの起動を行うため WebAPI とは別にコンカレントに動作する並行プロセス群として利用 |
| 検索エンジン | Amazon Athena | 大量データの検索・集計が必要であり、スケールする必然があったので、Athenaを利用 |
| データストレージ | Amazon S3 | Lambda や ECS タスク Athena の入力データのソース源として、大容量の監査ログやレポートの出力など取り扱う必要があったので S3 を利用。 |
実は無限には使えないリソース
社内 α 版に向けて上記のようなサービス構成で作成をしていると、様々な場所で問題が発生しました。特にその中でも顕著に印象に残ったのは以下の 2 つでした。
Amazon RDS から Amazon DynamoDB へ
当初、トランザクションの有無や、クエリの移行のしやすさから RDS を永続層に採用しようとしていました。しかし、サーバーレスを中心とした多量のサービスプロセスが発行されるサービス設計にした場合、従来の RDB では永続層の読み取りキャパシティが耐えきれなくなる問題が発生しました。
具体的には、例えば変換処理の並列度を 100 とか 200 とかいうオーダーで同時発生させたときに、変換処理用のパラメータの同時読み込みが多量発生するなど、当初予想していた Read キャパシティーよりも早く上限を打っていたのです。RDS 自身の設定で Read キャパシティーを増やす事も可能なのですが、今後もこの類の処理はスケールする事が求められる為、私たちは永続層のインフラとして Amazon DynamoDB を再選定する事にしました。もちろんこの決定は容易ではなく、従来のトランザクションに付随する問題は DynamoDB の特性を活かした方法へ昇華する必要があります。しかし、今回置き換えた部分は、主にアプリケーションパラメータに見られる「1 データ量は少ないが、大量の読み込みを迫られる」事が予想されるため、今後スケールさせる事を考えると RDS に比べ話が進めやすいと判断したのです。
AWS Lambda から Amazon ECS / AWS Fargate へ
Webサーバーによるビジネスロジックバッチタスクを Lambda で作成したのですが、意外と Lambda にも制約が多い事に気が付き始めます。特に以下のような制約において、苦慮する事となりました。
-
実行時間の制約
Lambda には実行時間の制約があります (この原稿を書いている時点で 15 分)。 私たちのログ変換処理では、コンテキストの詳細な解析なども行うため、ログの大きさによってはこの 15 分をゆうに超えるケースも存在し、これが原因でタイムアウトを起こすこともしばしばありました。 -
メモリの制約
Lambda では実行時利用できるメモリ (10GB) に上限があります。 変換処理などは高速化の為、収集したログに応じて積極的にメモリを使う作りになっており、これもまた足かせとなりました。 -
ストレージ領域の制約
本プロジェクトの初期の段階で Lambda ではデフォルトで 512 MB の容量しかありませんでした。これを超える「一時的なファイル」などを作りたい場合には Amazon EFS などのストレージサービスを別途使わなければなりません (本稿を書いている時点で、10 GB に拡張できるようになったようです。AWS は日々進化していますね)。
このような制約があったため、Lambda で作っていたバッチタスクを Amazon ECS / AWS Fargate 化することで問題回避しました。また、Fargate 化することにより、管理アカウント上にある Amazon ECR をうまく使う事で「アカウントをまたいだプログラムのデプロイが一極集中で簡単になる」という良い副作用の恩恵を受けることになります (コンテナイメージを管理アカウント配下で管理し、そのイメージを複数の企業アカウントで取得実行するといった具合です)。

クロスアカウントにおける処理のやりとり
上記のように構成や使う AWS のサービスとのマッピングが決まってくると、これらを有機的に動作させる方法が必要となりました。
先にもお話したとおりで、管理側と企業側でアカウントが分離しているため、各処理フローの中では適宜「クロスアカウント」における処理委譲の様を設計する事となります。端的に、「管理アカウント」と「企業アカウント」をまたがった処理はそれらの処理を「AssumeRole」を前提とした Role の移譲によって実現しました。
バッチタスク (ECS) や検索エンジン (Athena) の操作は AssuleRole により権限の制約が行われるため、バッチタスク単位での権限範囲が明確になりました。
まとめ
弊社がオンプレミスで動作するアプリケーションを、どうやって SaaS 化していったかの経緯をお話してきました。その変遷においてのポイントは
- アプリケーションのコンポーネント単位で、サイロモデルが適しているか、プールモデルが適しているかを分別し、両モデルの混載するモデルを考察
- 上記分離に伴い、アカウントを適宜分けていく構造にした
- コンポーネントには、そのコンポーネントが持つ「性格・性質」に合わせて、適切な AWS のサービスを選択する事が重要
- アカウントの分離による、各アカウント間の処理連携を AssumeRole を前提とした作りとした
となります。
本稿がこれからオンプレミスで動作しているプログラムを AWS へ移行していく方々の開発の一助になると幸いです。
筆者プロフィール
関根 正夫
株式会社網屋 開発部
下は不揮発性メモリのドライバ・ロジック半導体の設計・レイアウトから、上は OS やサーバーバックエンドのプログラムまで、手広く「開発」に携わってきました。近年はもっぱら弊社セキュリティ製品のコア部分に従事。
好奇心が強く興味の対象は尽きないのですが、最近の趣味はコーヒーを淹れる事、飲みあるく事です。
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages