- AWS Builder Center›
- builders.flash
Java × サーバーレスは SaaS バックエンドとして通用するのか ? ~ スタートアップの実戦記録 ~
2023-10-03 | Author : 近藤 徳行 (株式会社Conoris Technologies, CTO / CPO)
はじめに
様々な分野の技術革新が日々起き続けていますが、中でもサーバーレス技術の進歩は目覚ましいものがあります。しかし、残念ながら Java 言語に関して言えば、その言語特性からこのサーバーレスの波に一歩乗り遅れている感が否めませんでした。Java × サーバーレスの構成を試みたが、うまくいかなったという方も多いのではないでしょうか ?
ですが AWS re:Invent 2022 の SnapStart の発表 で状況は大きく変わり、用途こそ検証する必要性はあるもののいわゆる Web アプリケーションとしては低コストで運用が可能であるということを自社のサービスを運用することで日々感じています。
本稿では、自身がセキュリティチェックシート業務支援 SaaS「Conoris」の一人目エンジニアとして Java サーバーレスの構成を採用し、苦心しながら開発・運用してきた経験から、Java × サーバーレスの問題がなぜ発生し、それに対してコミュニティ、企業がどのような解決策を生み出したかと、利用してきた中でのメリットデメリット、実運用上のポイントをご紹介いたします。
1. なぜサーバーレスなのか?
2021 年秋より一人目の従業員としてスタートアップ企業、ConorisTechnologies に参画し開発を開始しました。以下は当時の情報をもとに判断した内容となっております。
まず、事業自体の見通しとして市場が存在するかどうかわからないという前提がありました。セキュリティチェックシート支援業務というソリューション自体をお客さまに買っていただけるのかわからない、あるいはビジネスが成立するかは私見としては五分五分というのが率直な思いでした。しかし、CEO の予見として、時間はかかるもののやがては市場に見出されるであろうという可能性についても感じていました。このタイミングでエンジニアとして考えなければいけないことは IT リソースの利用費用です。
特に初期段階でユーザーからさほど利用されていない状況であっても一定の利用費用が常にかかり続けるというコスト構造はスタートアップ企業にとって手痛い出費です。たとえ仮に素晴らしいサービスが完成したとしても、いざ市場が活性化した時に会社が資金切れにより潰れてしまっていては元も子もありません。市場が未成熟な分野においては市場が成立するその時まで、可能な限り利用費用を抑え、1 日でも長く会社を存続しチャレンジし続ける状況を作ることが重要です。
次に、セキュリティチェック業務の繁忙期というものも正直わかっていませんでしたし、とても好調でサービスがすごく利用される、ということも考えられます。そんな時に大きく構成を変えず、また自動的にスケーリングする仕組みこそが我々のビジネスに必要であると考えました。
その考え方に合致するソリューションこそがサーバーレス技術でした。起動した時間に応じて従量課金とされるため、ユーザーの利用が少ない時には使用料を抑えることができます。また反対にユーザーの利用量が増えた際には、マネージドサービスとして自動的にスケールアウト / インしてくれます[1] 。
このような背景から、利用費用、オートスケーリングの観点から大きなメリットを感じ、サーバーレス技術を採用、AWS Lambda の利用を開始しました。
どうして Java なのか
問題解決領域上、どうしても利用したい OSS がありました。よりサーバーレスに適した言語への移植プロジェクトも存在しましたが、やはり OSS はコミュニティであり、歴史的な経緯から言語との依存が強くあります。そのため Java を選択しました。
そのため Java × サーバーレスにて新規事業を行うというチャレンジが始まりました。
2. Java × サーバーレスの問題点
2-1. AWS Lambda の動きのおさらい
AWS Lambda では起動する処理を関数という単位で管理します。関数は実行可能な形式のソースコードを持ち、Java であれば 1 つの jar ファイルが関数の基本の形となります。関数が起動されると、マイクロ VM が割り当てられ、あらかじめ関数として用意しておいた jar ファイルがマイクロ VM にデプロイされたのち、処理が起動される形となります。
こちらの図が Lambda のライフサイクル になります。
関数が起動されるとマイクロ VM が起動し INIT 処理が実施されます。INIT 処理中に jar (zip) がマイクロ VM にダウンロードされます。クラスロードを含む INIT 処理が完了すると処理が実施されます。この INIT 処理から始まる一連の起動を Cold Start と呼びます。
起動されたマイクロ VM はその後、しばらく待機し続けます。現状この待機時間には課金されません。一定期間経つと自動的にマイクロ VM は終了 (SHUTDOWN) します。次回起動の際には Cold Start で起動し、INIT 処理から実行されます。
では、処理自体は完了し、待機している状態、つまり SHUTDOWN の前に関数が再度起動された場合はどうなるでしょうか ? 既に起動されているマイクロ VM (インスタンス) がある場合は再利用され、INIT 処理をスキップすることができます。つまりソースコードのダウンロードやクラスロードはスキップされて実行されるため Cold Start に比べて高速に動作します。これを Warm Start と呼びます。
最後に関数で処理が実行されている場合に、同じ関数の処理の起動依頼が来るとどうなるでしょうか ? この場合は Auto Scale し、別のマイクロ VM が割り当てられ、Cold Start から処理が始まります。

2-2. Java の AWS Lambda 関数の設計
ここでいわゆる Web アプリケーションのような用途で、ユーザーのブラウザなどのアクセスから Lambda を起動し、レスポンスのデータで画面を描画するようなアプリケーションのサーバーサイドのロジックを AWS Lambda で実装してみると想定し、その設計について考えてみたいと思います。
2-2. Java の AWS Lambda 関数の設計
ここでいわゆる Web アプリケーションのような用途で、ユーザーのブラウザなどのアクセスから Lambda を起動し、レスポンスのデータで画面を描画するようなアプリケーションのサーバーサイドのロジックを AWS Lambda で実装してみると想定し、その設計について考えてみたいと思います。
_Page_04_Image_0001.8a9272bb5354a613243d9d6955b34fef846440ba.jpg)
アーキテクチャ概要図 [2]
図中央の Lambda 部分が今回の対象範囲
設計における考え方
まず、関数をどのような単位で分割するかというのが一つの設計のポイントになります。一般論として関数の数が多い方が管理工数がかかり、関数の数が少ない方が管理工数が少ない、というのはご理解いただけるかと思います。また関数が増えるとビルド数が増えるということ、また関数として AWS Lambda にアップロードするということを考えるとこれも関数の数だけ実施する必要があり CI/CD 工数に影響します [3] 。 また凝集性の考え方が適用できるため、1 つの関数に集約するとメンテナンス工数が下がる反面、一度の修正で他のコードへの影響が大きくなるとも言えます。
次に、上記の AWS Lambda のライフサイクルを考慮すると、なるべく Warm Start として起動する回数が多くなること = Cold Start で起動する回数を少なくするような構成とすることが望ましいです。つまり、1 人のユーザーが操作する一連の操作時の関数のアクセスはなるべく 1 つの関数としてまとめた方が Warm Start として起動しやすく、UX として有利です。
しかし、全ての操作を 1 つの関数で行おうとして、たくさんのライブラリを読み込んだ結果、大きな jar サイズとなった際には、Cold Start の INIT 処理での Class の読み込みなどに時間がかかり遅くなってしまいます。仮に全てを 1 つの関数に集約した場合に、UX を考えた場合、本来その外部ライブラリが必要ない操作であるにも関わらずレスポンスが遅い、となるとサービス提供者としてはなんだか勿体無いですよね。
そこで弊社ケースでは大きなライブラリを必要とする関数 (重めの関数) とそうでない関数 (普通の関数) を分割することでこのバランスを取ることにしました。普通の関数ではいわゆる一般的な DB への永続化や読み出しを実行し、重めの関数では普通の関数の処理に加え外部の大きなライブラリを利用した処理を実施します。
仮に今ユーザー 1 名が操作すると仮定した場合ですが、こうすることで二つの関数を初回に行き来する際には Cold Start が発生しますが、一定時間内に次々と処理する場合は、ほぼ Warm Start で動作する構成となります [4] 。
2-3. Java × Lambda を動かしてみる
理論や設計の方針が固まったところででは実際のところ Java の Lambda が遅いのか、また Cold Start と Warm Start でどれくらい差があるのかということを実際の動作結果を見ながら確認していきたいと思います。
まずは上述の普通の関数です。処理時間が大きく二つ、3 秒程度のものと 500 msec 以下の集合に分かれているのが見えます。3 秒以上かかっているのが Cold Start によるもの、500 msec のものが Warm Start だと考えられます。
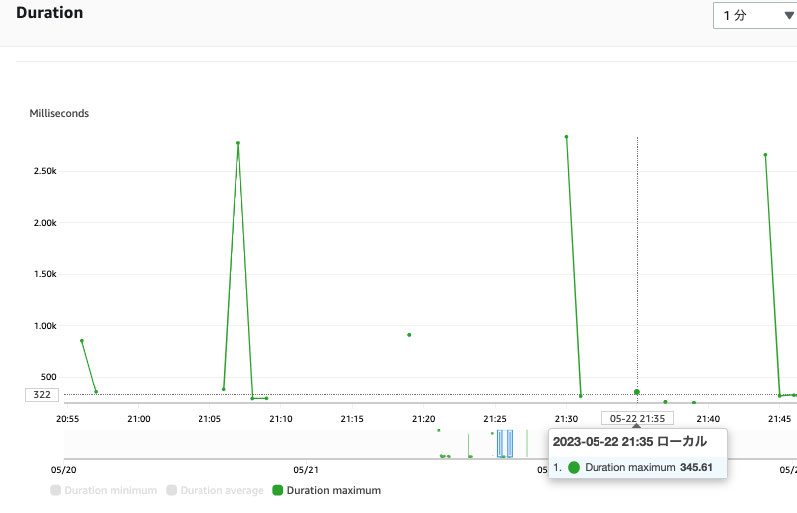
重めの関数の動作結果
次に上述の重めの関数を見ていきたいと思います。こちらも 2 グループ分かれ、Warm Start だと 2 秒前後、しかし Cold Start だと 15 秒を超えていますね。この結果を見てもわかる通り、特に Cold Start が発生した場合にはいわゆる Web アプリケーションの利用としては厳しいものがあります。
2-4. Java がなぜ Lambda と相性が良くないのか
先の結果を見ても、明確に Cold Start が遅いということがわかります。Cold Start と Warm Start の主な違いは上述の通り、INIT 処理があるかないかというところになります。そこから考えられる理由は JVM の起動およびクラスの読み込みに時間がかかり、前述の INIT 処理の時間が他の言語に比べて遅いからということになります。また Java には虎の子の HotSpotVM (実行時の JIT コンパイル) による高速化がありますが、サーバーレスの仕組み上、処理自体がしばらくすると終わってしまいます。これが Java とサーバーレスの相性が良くないと言われている部分です。
この問題に対して様々なソリューションが開発されました。その中で弊社が採用していったソリューションについて実例をもとにご紹介させていただきます。
3. 解決策
3-1. Provisioned Concurrency + CloudWatch
AWS Lambda の Provisioned Concurrency という機能を利用します。こちらの機能によりインスタンスを予め待機させておくことで Warm Start を同等の効果を狙うという方法になります。しかしこれでは待機させておくインスタンスを上回るリクエストが来た時には Cold Start が発生してしまいます。
そこで Cloud Watch によりインスタンスの負荷状況を監視し、使用率が高い場合には待機させるインスタンスを増加させるように設定しました。具体的には Provisioned Concurrency で待機インスタンスを 3 とし、CloudWatch で当時最頻だった 15 分に 1 回 [5] メトリクスを監視し、使用率が 60% を超える場合に待機インスタンスを増加させるようにしました。
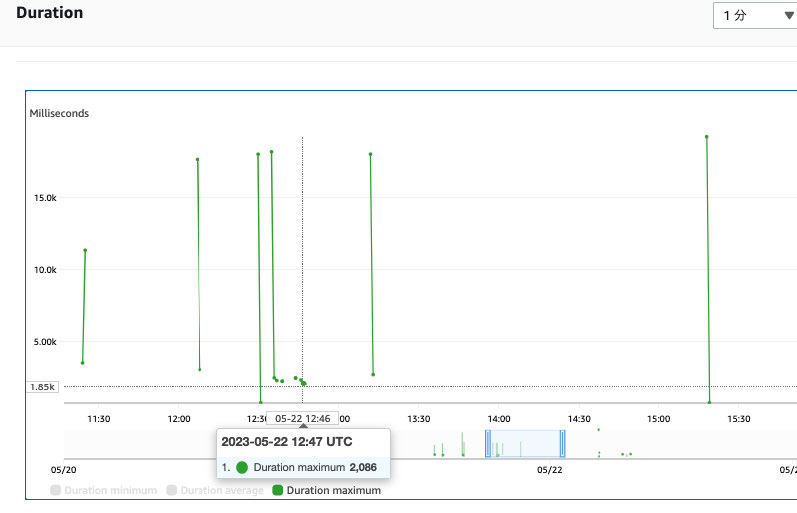
重めの関数 関数処理時間の 1 時間あたり最大値
検証結果
結果として、そこまで利用されない状況下では、多くの場合で Cold Start を防げていたものの、週に 1 回程度 Cold Start と思しき処理が起きていたことがわかります。これはおそらく 15 分に一回の監視による増加に間に合わない程度のリクエストが急にきたと言うことが想像できます。このソリューション自体が構造上、いわば階段上にスケーリングをするため、急なリクエストの増加に対応し切るには、より多くのインスタンスの待機が必要であったり、あるいはスケーリングをスタートさせる使用率を低く設定することで回避できたかもしれません。しかしながらそうなると利用費用の問題が発生します。
Provisioned Concurrency は有償で、待機しているインスタンス毎に課金が発生します。したがって待機インスタンスを増やすほど、利用費用がかかります。利用費用を抑えるために採用したサーバーレスで待機時間に利用費用がかかってしまうとサーバーレスにすることのジレンマに陥ってしまいます。
3-2. GraalVM native-image
Cold Start 問題を解決するための Oracle 社の GraalVM プロジェクト のソリューションが GraalVM native-image になります。ソリューションの説明の前に Java のコンパイラについて再度確認します。
|
コンパイラの種類 |
From |
To |
静的/動的 |
|
Java コンパイラ |
java ファイル |
class ファイル
|
静的 |
|
動的コンパイラ (JIT) |
java バイトコード |
Native コード |
動的 (メモリ上) |
|
Native コンパイラ |
java ファイル |
Native コード実行ファイル |
静的 |
一部改変。元アイデア こちら の記事より
Java コンパイラは開発者のみなさまお馴染みのコンパイラですね。開発の際にコンパイルすると、java ソースファイルが class ファイルに変換されます。class ファイルに変換することで JVM が実行可能なバイトコード形式になるコンパイラです。これらは一度コンパイルされると、次にコンパイルされるまで変更されませんね。そのためこちらは静的なコンパイルと呼べます。
次は運用担当者の方がお馴染みの動的コンパイラ (JIT)。普段の開発では特別意識することはありませんが、サーバーが起動してしばらくすると速度が高速化した経験はありませんでしょうか ? これは HotSpotVM と呼ばれるもので、Java バイトコードを内部的に各OSごとに実行可能な Native ファイルを必要な部分にコンパイルしてくれる結果、処理が高速化する内容になります。こちらは JVM 実行中に行われる動的なコンパイルになります。
さて、AWS Lambda で Java 利用時の初回起動が遅い理由の一つは JVM の起動速度が遅いことというのがありました。つまりそもそも JVM を利用しなければ非常に高速な起動が期待できます。GraalVM native-image では Native コンパイラを用いて AOT (Ahead-Of-Time) コンパイルすることで、Java コードから予め各 OS で実行可能な Native コードを生成 [6] することができます。これにより Java コードが Native コードに変換されていることに伴い実行速度の高速化が期待できます。また AWS Lambda 上で JVM が不要となりボトルネックとなっていた INIT 処理自体の短縮が期待できます。結果として Cold Start であろうとも圧倒的な速度が期待できます。
素晴らしいソリューションなのですが一つ問題があります。原理上、このままでは Runtime で Class を解決する Reflection を利用することができません。もちろん、回避方法はあり、AOT コンパイルの時点で Reflection する Class をあらかじめ指定するという方法を取ることでこの問題を解消することになります。具体的には json ファイルやコードベースでヘルパークラスを用いて、Reflection 対象の Class を指定することができます。これにより AOT コンパイルの際にあらかじめ Reflection する対象を Native コンパイルしておくことが可能になり、Reflection を利用したコードが実行可能となります。
ではこれを運用ベースで実装するとどうなるでしょうか ? 自分で書いたコードに関してはどの部分で Reflection を利用しているかを明確に知ることができるため、事前定義をしておくことは比較的容易でしょう。しかしながら外部ライブラリの Reflection はどうでしょうか ? 難しいですね [7] 。
またパッケージ名や依存している別のライブラリというのも考慮しなければいけません。もしも事前定義が正しくできていなければクラスが存在しないとしてランタイムエラーになってしまいます。
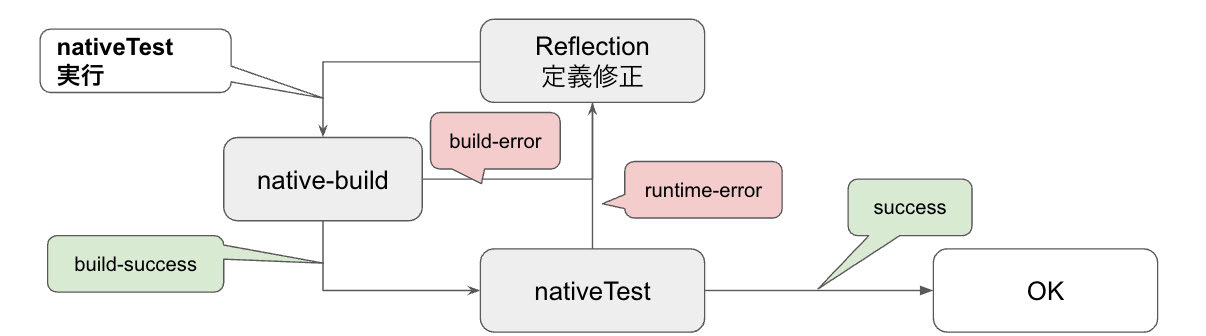
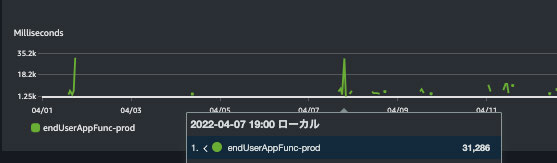
検証結果
さてその結果はどうなったでしょうか。Cold Start 時の速度を見てみると数秒程度で処理が完了しており、運用上致命的な状況を回避できるようになりました [10] 。したがって、AWS Lambda の Cold Start でも処理速度が早ければ問題を解消できる例と言えそうです。これによりサーバーレスで運用できるというレベルには達してきました。平均値を見ると普通の関数では 1 秒以下で返せることが多くなってきました。上述の通り、2 つの関数のサイズの差は 20 MB 程度であったため、ファイルのサイズの違いのよる影響にしては大きく開きがあるように思えます。これは重めの関数内で外部ライブラリの初期化処理を実施しており、それが影響を与えているのではないかと考えられます。
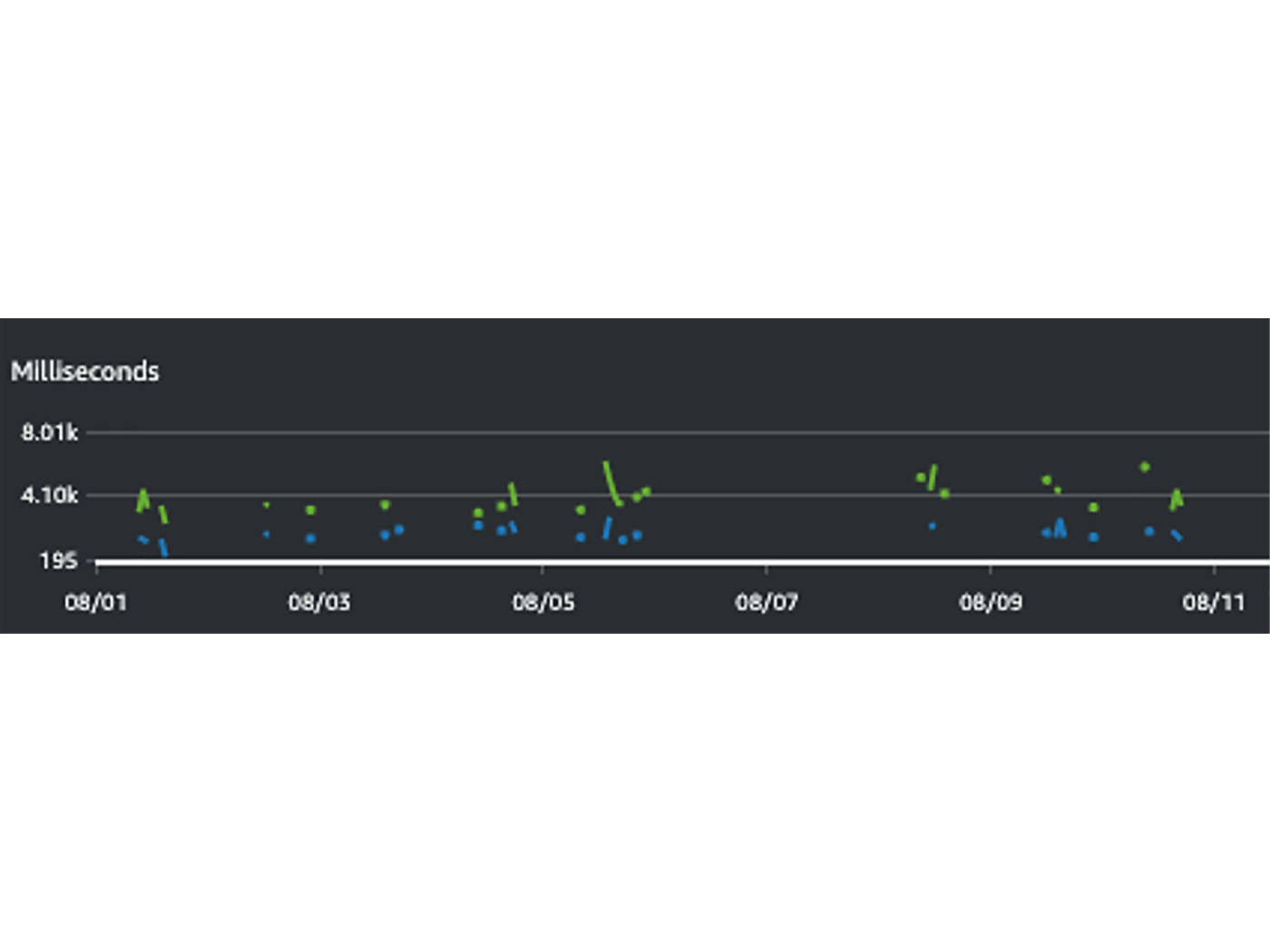
普通の関数(青)/重めの関数(緑) 関数処理時間の1時間あたり最大値
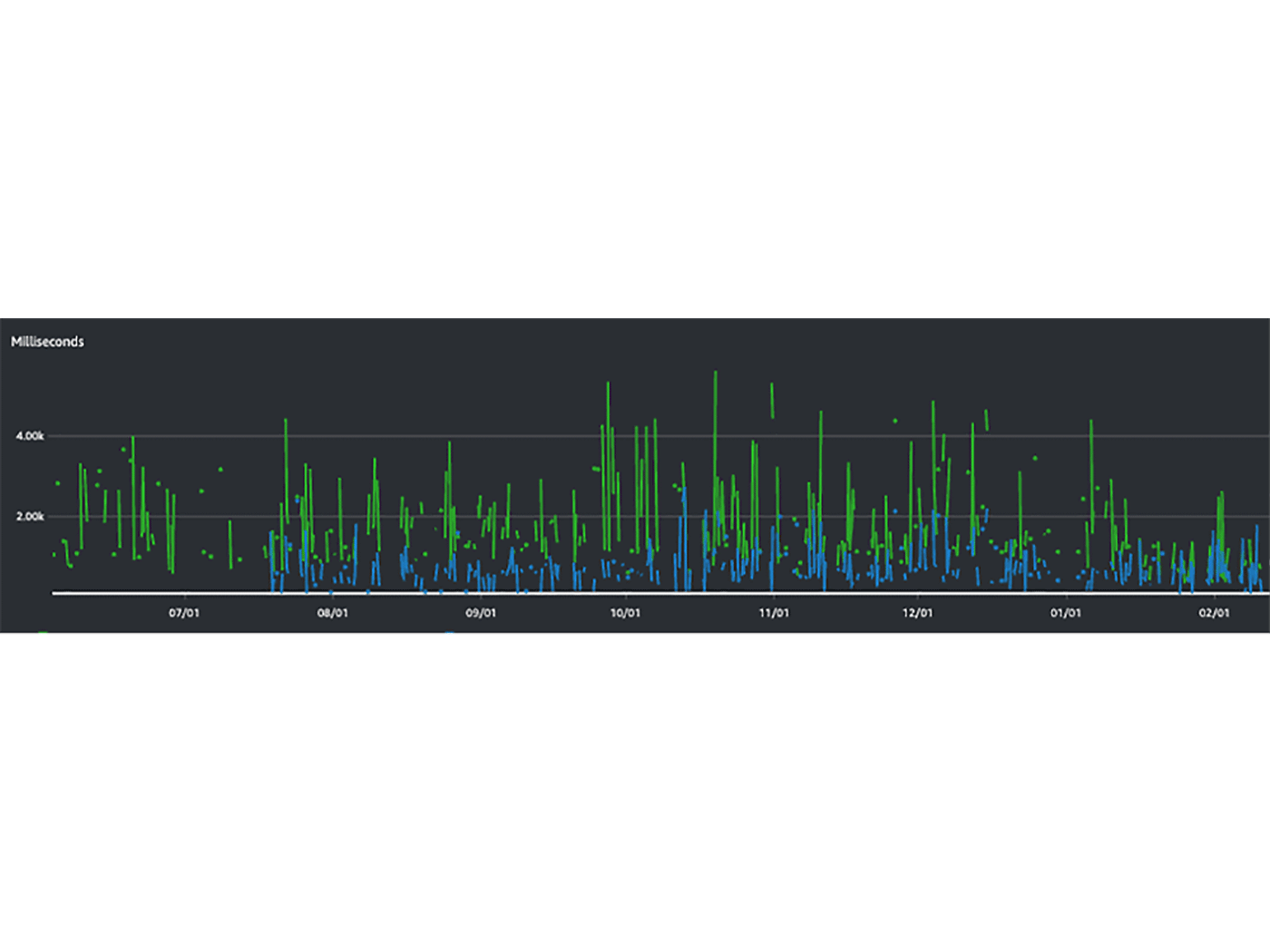
普通の関数(青)/重めの関数(緑) 関数処理時間の 6 時間あたり平均値
利用費用
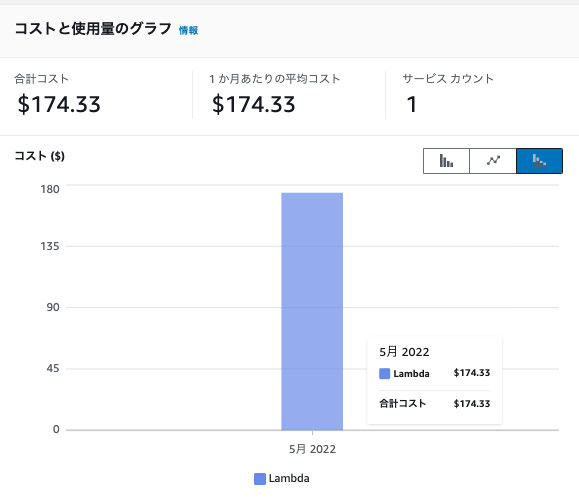
次に利用費用についてみていきます。
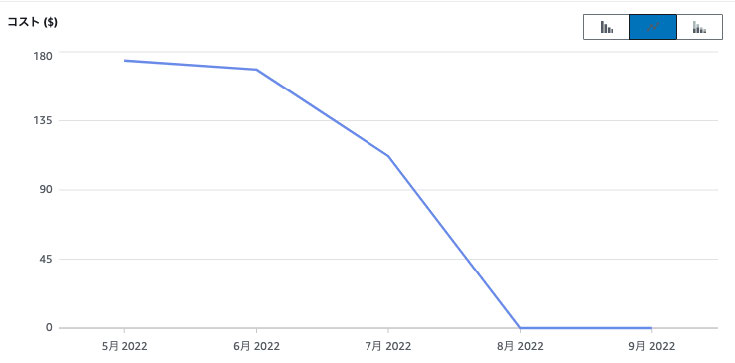
7 月中ばに native-image に入れ替えたのですが、なんと利用費用がほぼ 0 になりました。これは Lambda がまったく動いていないというわけではなく、従量課金分が無料枠内に収まった結果、0 という数字が出ています。目指していたサーバーレスのコスト構造に到達した瞬間です。強調したいのが先ほど記載した 4 月時点よりも利用ユーザー数は増えている、ということです。利用が増えているにも関わらず、アーキテクチャの変更により利用費用が激減しているということがお分かりいただけるかと思います。
GraalVM native-image の課題
GraalVM native-image は素晴らしいソリューションでサーバーレスの運用上の問題がほぼ解決しました。何より、思い描いていた Java × サーバーレスの利用費用にすることができました。反面、継続的な開発プロセス全般を考えると課題も残りました。
- 開発難易度が高いこと
native-build や native-build のエラーと付き合わなければならないのですが、なかなか原因を想像することは難しかったです。一言で言うならば普段の Java の開発で見たことのない類のエラーメッセージが出ます。実際にはほぼビルドオプションの工夫であるとか、Reflection 定義の変更で解消できましたが、これを将来的にチームメンバー全員に強いるのは厳しいのではないかと感じました。 - ビルドが重いこと
これは原理上仕方のないことなのですが AOT コンパイルを実施するためにビルドに時間がかかってしまいます。この部分は GraalVM のバージョンが上がるごとに改善している部分ではありますがやはりローカルの開発環境で 1 関数のビルドに数分かかるのは開発プロセスとして厳しいものがあります。 - Lambda のサイズ上限 [11]
Reflection する対象クラスを増やしていくと、naitve-build で生成される実行ファイルの大きさがどんどん大きくなっていきます。あまり普段意識していなかったのですが Lambda の関数のサイズ上限は解凍後のサイズが 250 MB となっています。そのためとあるライブラリを頑張って足したところ、重めの関数はサイズオーバーのためアップロードできなくなってしまいました [12] 。もちろん先述の通り、1 つの jar に複数の機能を持たせているが故の問題ではありますが、一度起きてしまうと関数分割戦略の見直しが必要となるかもしれません。 - 他のソリューションの利用
既存の監視やプロファイラなどは JVM 依存で設計されています。つまり native-image にしてしまうとそれらを直接使うことができなくなります。もちろん時間と共に充実していく可能性もあり、今後も注視していきたいです。
3-3. SnapStart
そんな中、2022 年 11 月の re:Invent で発表されたのが SnapStart です。Coordinated Restore at Checkpoint (CRaC) を実装した仕組み [13] で、起動中の JVM プロセスの状態を snapshot として保存し、Cold Start 時にその snapshot から再実行する仕組みになります。特に INIT 処理などを snapshot 取得前に実行することにより、実処理で初期化処理をスキップできるため、大幅な速度改善が見込めます。個人的なイメージですがゲームのセーブデータに近いでしょうか。セーブってできるんだ、途中から始められるんだ ! みたいな感動があります。
そして実務上非常に嬉しいのが前述の native-image 実装時に発生していた開発プロセスの課題がないのに速度が期待できると言うことになります。
利用に際する設定自体もほぼ Lambda コンソールでの設定の変更だけになります (AWS Cloud Formation の記載にも対応しています)。ただ、Lambda のエイリアスの利用が必須になるため、常に Latest として外部から呼び出していた関数に関してはエイリアスとして適用することが必要になります。
(画像は Starting up faster with AWS Lambda SnapStart より)

利用ケースの説明
弊社利用ケースでは大きい外部ライブラリの初期化処理自体を beforeCheckPoint で実施するようにしました。これにより先の通り、特にメモリ上にインスタンスを作るような処理、例えば DI のような処理が snapshot として保存でき、その状態からスタートできるということになります。注意点としてはこの初期化処理中に DB にアクセスしたりといった外部と接続した状態をメモリ内に格納してしまうと復元時にエラーとなってしまいます。そういった内容は必ず切断し、restoreCheckPoint などで復元時に必要に応じて再接続するなどの工夫が必要です [14] 。
※画像の説明
重めの関数 (native-image) ) (緑) / 重めの関数 (snapstart) (黄)
処理時間の 1 時間あたり最大値
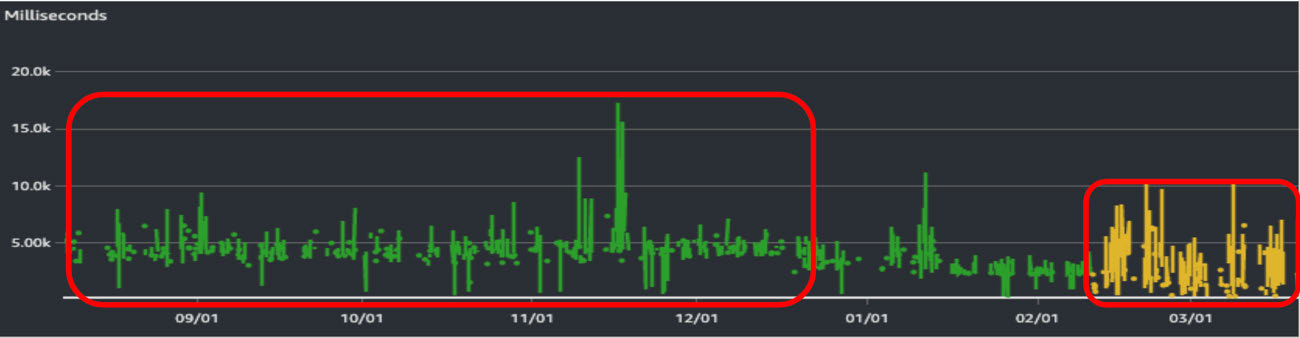
SnapStart の初期処理
まずは Cold Start から確認したいところですが、サービスもどんどん機能追加した結果、純粋に処理 (DB アクセス) 自体が遅い、というものもこのメトリクスに入ってくるようになってしまっています。また赤枠以外の期間に関しては運用上の必要性から Lambda のメモリを 3 GB に指定してしまった結果、比較対象として妥当ではない期間になります [15] 。
注目していただきたいのは、下限の部分です。Native-image では一貫して 4-5 秒程度かかっていたのが、SnapStart では 2 秒以下というものも多く見られます。これは native-image では外部ライブラリの初期化処理を実施しているが、SnapStart ではこの初期化処理自体を Skip できていることによるものだと考えられます。
※画像の説明
重めの関数 (native-image) (緑) /重めの関数 (snapstart) (黄)
処理時間の 1 時間あたり平均値
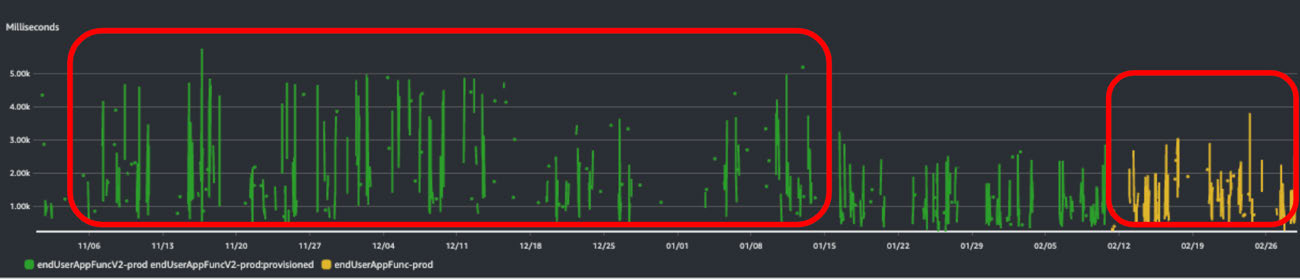
検証結果
こちらは平均速度になりますが、重めの関数に関してはやはり native-image に比べて SnapStart では平均速度も改善されています。
個人的に非常に面白いと思ったのは普通の関数の結果です。Native-image に比べ SnapStart の方が処理時間平均としてはやや、遅くなっています。これは外部ライブラリの初期化などが発生しない処理の場合はやはり native-image が高速であるということが言えるかと思います。
あくまで弊社の事例の1つではありますが、純粋な速度としては native-image の実行速度が高速であるが、利用しているライブラリなどで初期化処理が速度のネックになってくるような、snapshot であらかじめ保存できる処理の実行に時間がかかっている場合は SnapStart の方が高速である、と言えるかと思います。実装する処理や更新頻度、そしてチームによっていずれの方法を採用するべきかの最適解は異なるでしょう。
※画像の説明
普通の関数 (native-imiage) / 普通の関数 (snapstart)
処理時間の 1 時間平均値

利用費用
次に利用費用を確認してみましょう。図は Lambda の利用費用 (グラフ上) と、同時期の関数の起動回数 (グラフ下) を表したものです。SnapStart に切り替えてもコストがかかっていないことがみて取れるかと思います。また継続的に利用回数自体が増えているがコストがほとんど変わっていないということもわかるかと思います。
※画像の説明
重めの関数 (緑) / 普通の関数 (青)
関数起動回数 (1 日合計)
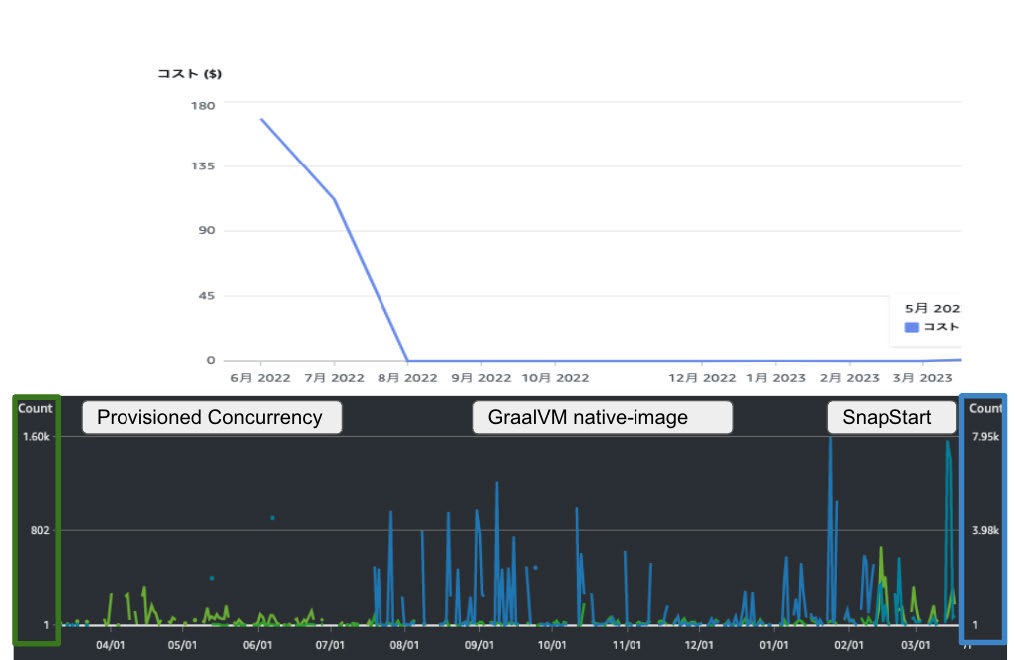
注釈
[1] サーバーレス技術を利用してスケールアウトする際にはいわゆるアプリケーション層だけではなく、DB など関連するリソースに対する考慮が必要です。弊社では 2022 年 5 月以降、Amazon Aurora Serverless V2 を採用することで AWS Lambda がスケールアウトするなどして Aurora の負荷が高まるとスケールアップする構成を取っています。
[2] AWS Amplify を用いてブラウザからのリクエストを AWS AppSync で受け、AppSync から Lambda を起動するような構成となっております。
参考 :
Amplify で企業向け SaaS 作ってみた (2021 AWS Startup Tech Meetup #8)
Amplifyを用いた企業向けマルチテナント アーキテクチャ事例 (AWS Startup Community Conference 2022)
[3] 弊社では Amplify と gradle のマルチプロジェクト構成を併用することで問題を解消しています。共通ライブラリは gradle 管理とし、ビルドおよび適用自体は Amplify CLI のコマンドによる一括適用を実現しています。
[4] 2021 年時点での設計であるため、現時点では多くの問題は他のソリューションにより解消されている部分もあると思います。しかし Java 利用時の Lambda の原理に寄り添った設計ではあるため基本的な考え方としては有用であると考え、記載しています。また当時は DI の初期コストが気になったこともあり、フレームワークを利用せず pure Java で実装しておりました。現在は Micronaut というフレームワークを利用しています。
[5] 現在は大幅に改善し 1 分間隔でメトリクスを監視できるようになっているようです。
[6] Mac OS だとファイル種別はUnix実行ファイルと表示されました。尚、余談ですが native コードは OS 依存のため、Lambda にアップロードする際には、Linux でビルドした成果物をアップロードしないと動作しません。
[7] 現在、有名なライブラリに関してmeta data がまとめられています。ご自身が利用しているライブラリの meta data があればこのような問題は起きないかもしれません。
[8] DB レイヤーに関しても同様の問題が発生するため、Mock 等を用いず実際に JUnit テストで永続層にまでアクセスするというテストを書いています。
[9] JUnit テストなど処理時に必要な定義ファイルを自動で解析する方法もありますが、特定パッケージ以下などの指定が可能なためコードベースで定義することが多かったです。
[10] 参考値ですが、解凍後の実行ファイルのサイズは以下の通りです。
native-image 普通の関数 : 約 180 MB、重めの関数 : 約 204 MB
通常 JVM 普通の関数 : 約 76 MB、重めの関数 : 約 88 MB
余談ですが、上記の値が取れるのは native-image ビルドの jarと通常 JVM ビルドの jar を別関数として定義していたからです。native-image 関数は、gradle で通常の Java プロジェクトを参照し、native-build することで作成していました。Amplify と AppSync で管理していたのですが、各 Query や Mutation でどちらの関数を利用するかが定義できるので、native-image を段階的に検証しながら導入することができました。
[11] 技術的には Lambda に Amazon ECR のコンテナイメージを採用することで上限を 10 GB まで上げる方法も存在しましたが、Amplify による統合管理をしている都合や、取り回しの難しさから採用を見送りました。
[12] 最終的に該当ライブラリは http リクエストで代替可能であったのでそのように変更しました。
[13] CRaC についての参考になる記事は こちら。SnapStart に関しても解説されています。
[14] その他にも beforeCheckPoint で実装してはいけない処理があります。 Lambda SnapStartでLambda関数を高速化
[15] Lambda では高いメモリを割り当てると、その分高いコンピューティングリソースが割り当てられます。
4. まとめ
2021 年から振り返ると Java × サーバーレスのソリューションは充実してきたと言えるかと思います。解決したい問題領域や用途ごとの検証の必要性はありますが Java × サーバーレス が Web アプリケーション用途で利用可能になってきたのではないかと思います。特にいわゆる AP サーバーと呼ばれる領域に関して非常に安価に、かつスケーリングするというのは無視できない要素ではないかと思います。
弊社では 2022 年 4 月の Conorisβ 版公開以降、本記事のような変更を適用し続けてきました。できた要因を振り返ると、粗くとも自動テストを書き続け、ビルド / デプロイを見直し、今のプロセスを短縮するために未来に投資し続けたからではないか思っています。自動回帰テストが回るから安心してリファクタできる、新しいバージョン、フレームワークに挑戦できる。これらが挑戦への心理的安全性になります。逆説的ですが一歩一歩地味に改善し続けることによる開発プロセスの短縮と品質向上こそが、継続的な技術的挑戦を可能とするのではないでしょうか。
なお、本稿の打ち合わせしている際に、Lambda の X-Ray でのパフォーマンス調査をご提案いただきました。言われてみると確かにパフォーマンスは可視化しておいた方がいいし、導入に伴う不具合があれば自動テストが検出するだろう、ということで軽い気持ちで導入しました。早速古いロジックが非効率な実装になっていることが明らかになり、無事、お客様のご指摘を受ける前に修正することができました。このような小さな改善こそが次の技術的挑戦への投資になると信じてやみません。
本稿がみなさまの Java × サーバーレス実装の参考になれば幸いです。
筆者プロフィール
近藤 徳行
株式会社ConorisTechnologies CTO/CPO
ERP パッケージベンダーにて内部統制向けプロダクト / 基盤の開発、導入、保守に携わる。2021 年 9 月より現職。セキュリティチェック業務支援 SaaS「Conoris」を AWS Amplify と AWS Lambda (Java) の構成で開発、運用。
普段は Amazon CloudWatch を眺めながらフロント-バックエンド - アーキテクチャのデザイン / 設計 / コーディングをしています。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages