- AWS Builder Center
- builders.flash
Amazon Bedrock を活用して 3D キャラクターと対話するサービスを構築する
2024-07-02 | Author : ピクシブ株式会社
はじめに
ChatRoid とはピクシブが提供する 3D キャラクターと対話できる新ソリューションサービスです。
リアルタイムでの会話生成を中心としながらも、ただテキストを表示するのではなく、フルボイスでの会話体験や 3D モデルのアニメーションを組み合わせたプロダクトです。3D キャラクターを通した、愛着を感じられる生きたインタフェースの実現を目指しています。
2023 年 4 月の技術デモ「ChatVRM」に始まり、様々な場所でイベントの案内や、ファンと特定のキャラクターとの会話を実現してきました。2024 年 3 月 20 日には FANTASTICS の佐藤大樹さん (注 1) 監修のもと「AI佐藤大樹」を制作し、多くのファンの方に会話いただきました。
本記事では ChatRoid で採用したアーキテクチャと採択理由に関して紹介したいと思います。
(注 1) 佐藤大樹
ダンス&ボーカルグループ EXILE/FANTASTICS のパフォーマー。
リーダーを務める FANTASTICS では 18 年「OVER DRIVE」でメジャーデビューし EXILE と兼任して活動中。俳優としても活躍しており、出演映画「逃走中 THE MOVIE」は今年 7/19 全国公開。24 年には初の冠ラジオ番組 NACK5「FANTASTICS 佐藤大樹のぼっちマイク」がスタート。FANTASTICS の初の単独アリーナツアー、ファイナル公演を今年 7/14, 15 に幕張メッセで開催。

builders.flash メールメンバー登録
AWS のベストプラクティスを毎月無料でお試しいただけます
概要
ChatRoid は下記のようなアーキテクチャで構成されています。
この中で特筆すべき点や工夫した点を紹介したいと思います。
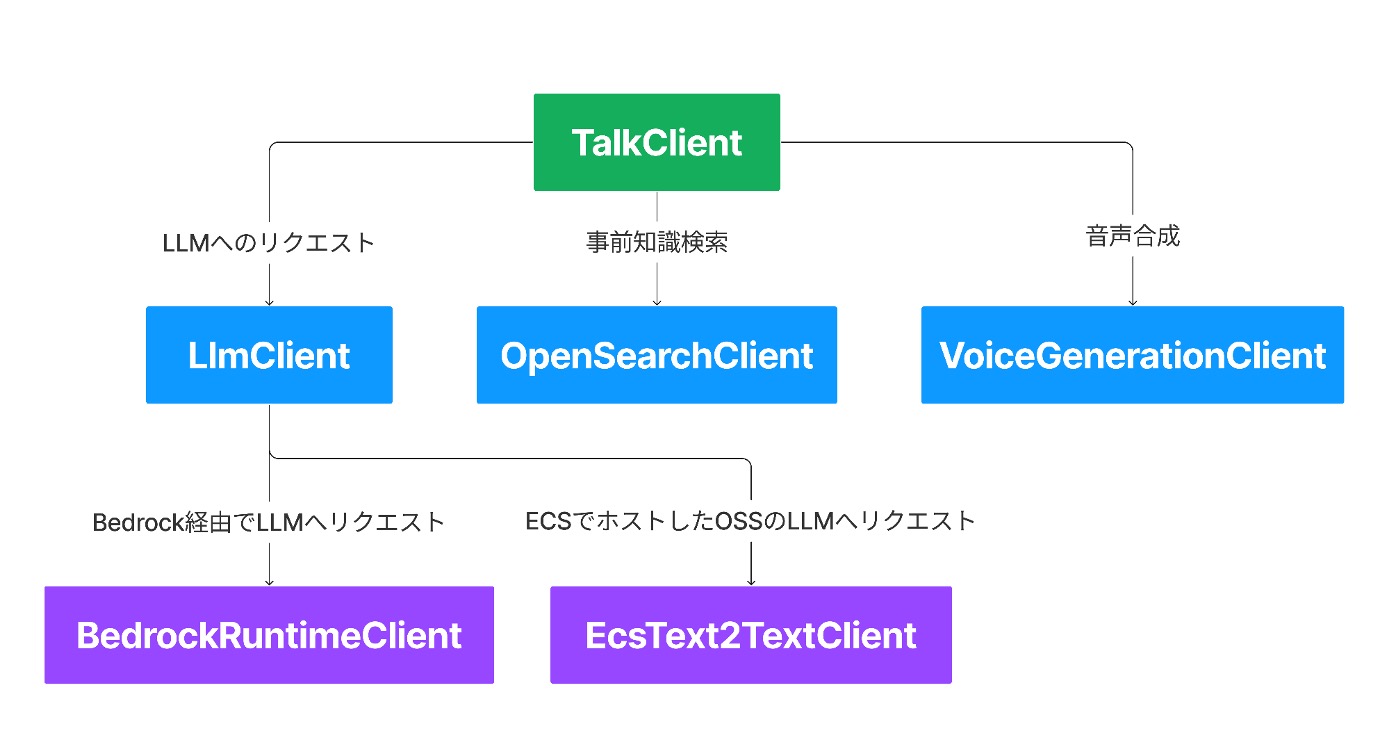
アーキテクチャ図
本題
LLM のモデル選定の過程
ChatRoid プロジェクトにおいて、LLM については新規公開されたモデルをすぐ手元で評価・動作させることを重視しています。
LLM モデルを巡る状況は数日で大きく変化するためです。
具体的には、TalkClient → LLMClient → BedrockClient のように、キャラクターとの会話プロセスを段階ごとに抽象化し、新しいモデルを使う時は末尾の Client (上記の例では BedrockClient) の疎通部分だけ実装すれば良いようにしています。
実際に、Amazon Bedrock で使えるようになってから一週間足らずで、Claude 3 Haiku の検証・導入ができました。
また、LLM の選定基準としてはレスポンスの速さとキャラクター設定通りに会話できるかを重視しています。
一般論として、パラメータ数が増えるほど AI は賢くなり、レスポンスは遅くなるため、上記 2 点の両方を満たすには比較的パラメータ数が少なく、質の良い (会話に適した) 学習データが必要になります。
しかし学習データの中身の検証はできないため、今回は手動での定性評価によって LLMモデルの選定を行いました。
Claude 3 Haiku は Claude 3 Sonnet と比べてレスポンスが速く、回答品質も会話のユースケースでは必要十分以上の性能を有していたため採用しました。イベント直前に利用可能になったことは本当に幸運でした。
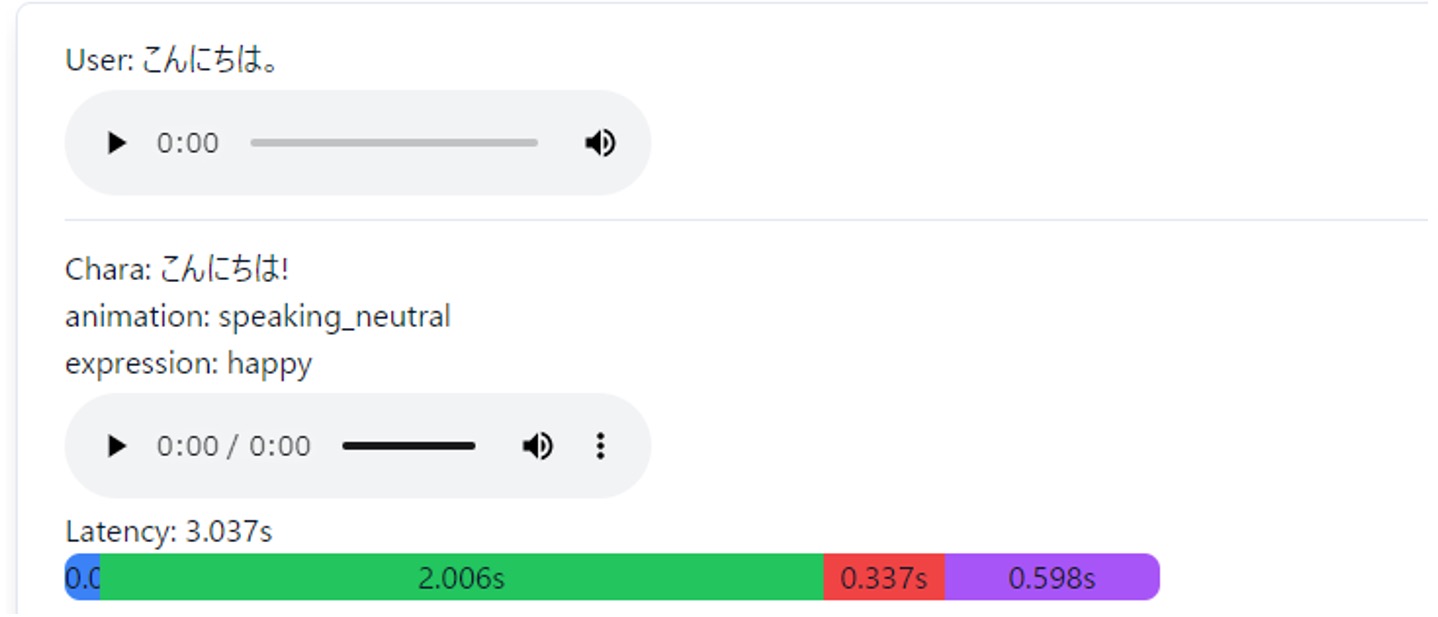
検証用ページ
また、検証用ページでは、ユーザーの入力と応答の詳細を表示できるようになっています。
ここでのポイントは、応答時間を表示することと、応答時間の内、どの要素にどれだけの時間がかかっているかを図示することです。
画像は表示の一例です。画像の Latency の色分けされたバーは、応答時間の各要素を以下のように色分けしています
-
青色が RAG の検索時間
-
緑色が LLM の応答ストリームが開始されるまでの時間
-
赤色が LLM の応答が一文を構成するまでにかかった時間
-
紫色が音声合成に要した時間
画像より、LLM の応答において緑色の部分、すなわちストリームが開始されるまでの時間=初期応答の影響が大きいことがわかります。
検証によってわかったこと
この検証画面をベースにプロンプトエンジニアリングを行い、初期応答時間の改善を行った結果、以下のような施策が効果的であることがわかりました
-
Temperature を下げる (0.4 くらいまでは回答に違和感が少ない)
-
入力トークン節約
-
長文は書かない。短文で指示する
-
LLM モデルを Claude 3 Sonnet から Claude 3 Haiku に変更した (より軽いモデルに変更した)
このような施策を実施し、初期応答が安定して 1.0 second(s) 以下になり、応答全体のレスポンスにかかる時間が安定して 2.5s 以下をキープできるようになりました。また、一つの目安として、3s 以上応答時間がかかるとユーザーが「AI が回答を考えている」と思ってしまうことがわかりました。
Amazon OpenSearch Service と Amazon Bedrock を利用した RAG アプリケーションの構築
OpenSearch の Hybrid Search を使って RAG を構築しています。
RAG とは Retrieval Augmented Generation、検索で拡張した文書生成のことであり、外部データストアから取得 (検索) した情報をプロンプトに渡すことで、動的な外部記憶機能を実現する手法です。
今回はデータストアに Amazon OpenSearch Service, 検索には OpenSearch の Hybrid Search を用いました。
また、OpenSearch に投入するドキュメントには chunking 済みのテキストとそのembedding 後のベクトル、元になったテキストのタイトルを投入しました。
chunking は Ruby の Text Splitter ライブラリである Baran のRecursiveCharacterTextSplitter メソッドを、embedding については Amazon OpenSearch Servie で利用可能でかつ多言語対応という条件の元、paraphrase-multilingual-MiniLM-L12-v2 のモデルを用いました。
Hybrid Search においてはタイトルを通常のテキスト検索・chunking と embedding 済みのテキストにベクトル検索を同等の重みで設定しました。
今回のケースでは RAG の外部記憶のことを事前知識と呼び、ChatRoid で表現するキャラクターの設定を OpenSearch に投入しました。設定の他にも、ある質問に対して誘導したい回答がある場合は、タイトルに質問、テキスト部分に回答を持つドキュメントを投入することである程度 AI の回答を制御することができました。
Amazon ECS における AWS Fargate と Amazon EC2 の使い分け
Amazon ECS の実行環境には AWS Fargate と Amazon EC2 の 2 種類を選択することができます。通常の Web アプリケーションだと Amazon ECS の実行環境には AWS Fargate を使うことが多いと思います。ChatRoid では Amazon ECS クラスタ上で複数のアプリケーションが動いていますが、アプリケーションの特性に応じて Amazon EC2 と AWS Fargate をそれぞれ使い分けています。
まずは ChatRoid のフロントエンドから呼ばれる API です。こちらは Ruby on Rails で作られています。API は Amazon ECS の他には下記のサービスを利用しています。
-
Amazon Aurora MySQL : キャラクターの設定の保存
-
Amazon ElastiCache for Redis : セッション情報の管理、非同期ジョブのバックエンド
-
Amazon OpenSearch Service : 事前知識、会話履歴などの検索
-
Amazon Bedrock : LLM によるチャット生成
余談ですが、実は Amazon MemoryDB for Redis ではなく Amazon ElastiCache for Redis を利用しているのにも理由があります。その理由はこの後の項目で書きます。
この API は AWS Fargate 上で動かしています。API の他には音声合成と音声認識のために GPU を必要とするコンテナがそれぞれ Amazon ECS のクラスタ上で動いています。
しかし、AWS Fargate だと GPU が使えません。そのため、GPU が利用できる Amazon EC2 インスタンス (具体的には g5.12xlarge) の上でコンテナを動かしています。
このように、GPU が必要なアプリケーションでは Amazon EC2 を利用しつつ、GPU を必要としないアプリケーションでは AWS Fargate を利用することで運用の手間がなるべくかからないようにしています。
これらのアプリケーションは全て ecspresso を用いて Amazon ECS にデプロイしています。
Amazon ElastiCache の選択理由
AWS で利用できるフルマネージドな Redis には Amazon MemoryDB for Redis と Amazon ElastiCache for Redis の 2 種類があります。
ChatRoid では Sidekiq を利用しています。Sidekiq とは非同期ジョブのライブラリで、Ruby では広く使われています。この Sidekiq のバックエンドとして Redis を利用するのですが、https://github.com/sidekiq/sidekiq/wiki/Using-Redis#architecture に
Cluster is NOT appropriate for Sidekiq as Sidekiq has a few very hot keys which are constantly changing (aka queues) and Cluster cannot guarantee high-performance transactions, necessary to keep your job system fast and consistent.
との記載があるように、Redis の Cluster Mode では動きません。しかし Amazon MemoryDB では Redis の Cluster Mode が必須になります。
そのため Sidekiq のバックエンドには Amazon MemoryDB ではなく、Amazon ElastiCacheを Cluster Mode が無効化した状態で利用しています。
まとめ
本稿では AWS をベースに LLM (RAG)・音声認識・音声合成を用いてキャラクターと対話するためのアプリケーションの構築と、技術選定について紹介しました。
このサービスを構築するために要した期間は 2 ~ 3 ヵ月ですが、その間にも LLM・音声認識・音声合成の新モデルがそれぞれ発表されたように、この領域では非常に短いスパンで技術の更新が行われています。今回のケースでは、各技術要素を抽象化し技術選定と更新にかかる工数の短縮に注力し、上手く対応することができました。
本記事がみなさまの手助けになれば幸いです。
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages