- AWS Builder Center
- builders.flash
Karpenter の魅力と実装にちょっぴり Dive Deep ~ Consolidation 編 ~
2024-09-03 | Author : 後藤 健汰
はじめに
こんにちは、ソリューションアーキテクトのごとけん (@kennygt51) です。
皆さま、Karpenter というツールをご存知でしょうか? Karpenter は AWS によって開発された Kubernetes クラスターオートスケーラーです。Kubernetes におけるノードのオートスケールを実現するために、Amazon EKS をご利用の多くのお客様が Karpenter を活用しています。
2021 年にリリースされた Karpenter は、多くのコントリビューターの協力もあって、日々成長を遂げています。2023 年には alpha 版から beta 版への昇格が発表 され、よりユーザーにとって使いやすく進化しました。そして 2024 年 8 月、ついに Karpenter v1.0.0 がリリースされ、安定版に移行しました。
一方で、Amazon EKS を利用しているお客様の中には「Karpenter についてよく知らない」あるいは「Karpenter の何が便利なのかよくわからない」という方もいらっしゃるのではないでしょうか。Karpenter は 2021 年にリリースされた比較的新しいオープンソースであるため、その魅力がまだ多くのお客様に届いていない可能性があると考えています。
本記事は、そんな Karpenter についてより多くの人に知っていただくために、ソースコードを読みながら Karpenter の魅力と実装にちょっぴり Dive Deep していこう ! という企画になっています。数多くある機能の全てのコードを読んでいくのは 1 本の記事では難しいので、今回は Consolidation (統合) という機能に焦点を当てて解説していきます。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
Karpenter とは ?

Karpenter の特徴
Karpenter が持つ大きな特徴として「シンプルな設定で、簡単にコスト最適化ができる」という点が挙げられます。Karpenter をインストールして、NodePool という名前のカスタムリソースを設定することで、簡単に使い始めることができます。
Karpenter は、ワークロードの要求を満たすコストの低いインスタンスタイプでノードを起動します。Cluster Autoscaler のようにインスタンスタイプを明示的に指定する必要はありません。
Karpenter についてより詳しく知りたい場合は、AWS BlackBelt Online Seminar で公開されている Karpenter Basic を併せてご覧ください。
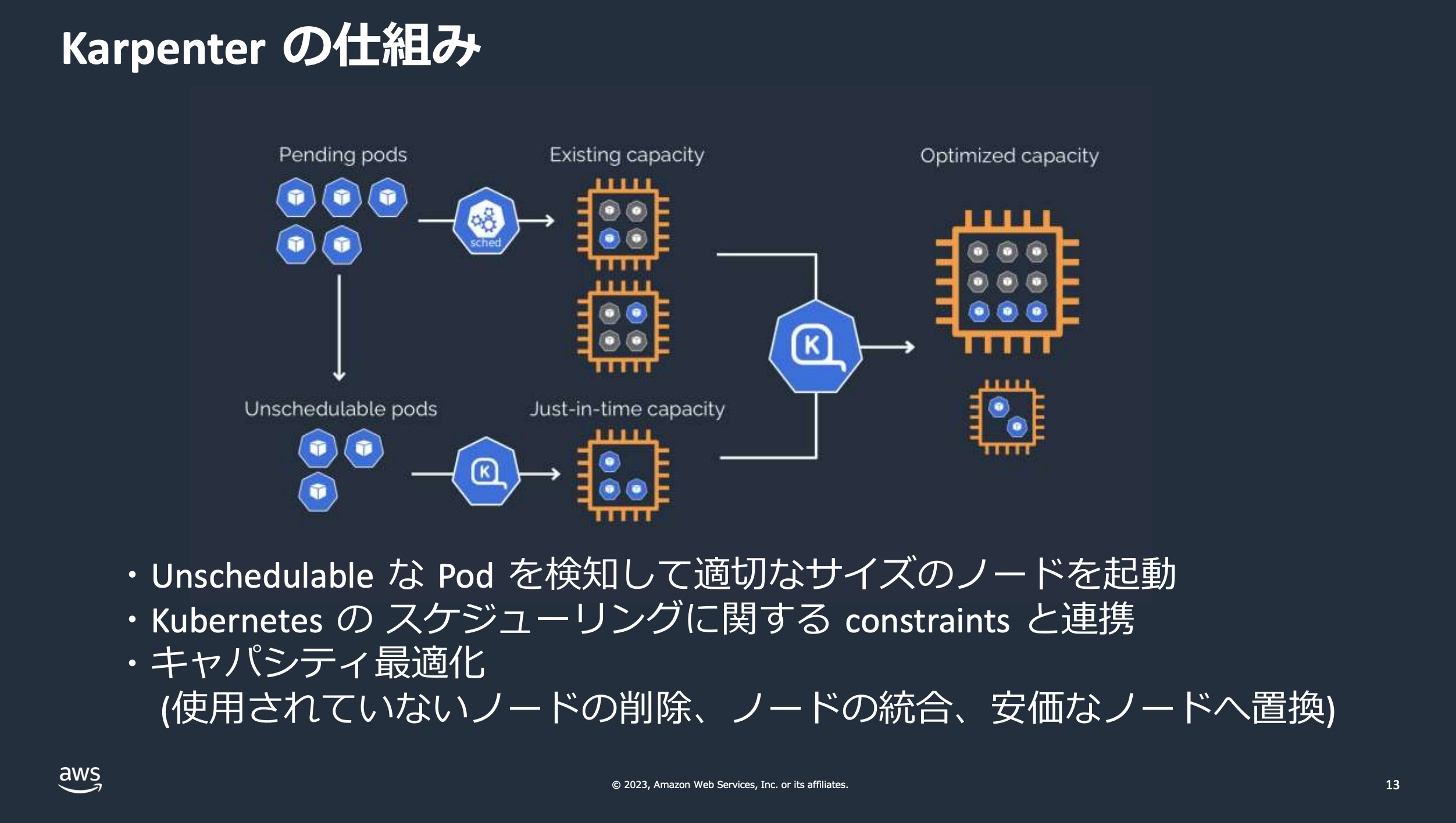
Consolidation とは ?
本記事では、冒頭でも述べたように Karpenter の Consolidation という機能について解説します。
Consolidation についてより正しく理解するためには、Karpenter がノードをどのように停止するか ? という、中断 (Disruption) プロセスについて理解することが重要になります。
kubectl などを使ったユーザーによる手動でのノードの中断や、外部システムからの中断を除くと、ノードの中断は Karpenter の Disrupition Controller によってトリガーされます。Disruption Controller によってトリガーされるノードの中断は、次に挙げる 4 つの方法に分かれます。
-
Expiration
Karpenter は NodePool の spec.template.spec.expireAfter の値に基づいて、設定された秒数を経過したノードを Expiration として Annotations を付与し、ノードを中断します -
Consolidation
Karpenter は様々な状況に応じて、クラスターのコストを削減します -
Drift
望ましい仕様からドリフトした (離れた) ノードを中断します -
Interruption
Karpenter はノードに影響を与える可能性のある中断イベント (スポット中断など) を監視し、イベントに先立ってノード上の Pod を退避し、ノードを終了させます
Consolidation は、これらの 4 つの方法のうちのひとつで、クラスター内のリソース利用効率を最適化し、コストを削減するための重要な機能です。例えば、とあるノードで Pod が動いていなかったり、より安いノードに置き換えることができると判断した場合、Karpenter はそのノードを削除する、あるいは置換するといった処理をおこないます。
整理すると、Karpenter は Consolidation を実現するための 2 つのメカニズムを持っているといえます。
-
削除
クラスター内の他のノードの空き容量で全ての Pod を実行できる場合、そのノードは削除の対象になります -
置換
クラスター内の他のノードの空き容量と、より低価格な単一の置換ノードの組み合わせで全ての Pod を実行できる場合、そのノードは置換の対象になります
また Consolidation によって行われる具体的なアクションですが、次に挙げる 3 つの動作があります。
-
Empty Node Consolidation
完全に空のノードを並列に削除 -
Multi Node Consolidation
2 つ以上のノードを並列に削除し、場合によっては削除される全てのノードの価格よりも安い 1 つの代替ノードを起動する -
Single Node Consolidation
単一ノードの削除を試みて、その削除されるノードの価格よりも低い価格の単一の代替ノードを起動する
では、Consolidation の機能を利用・設定する際には、どのような作業をおこなう必要があるのでしょうか。
Consolidation ポリシー
Consolidation は Karpenter によるノードの中断の仕組みのひとつとして提供されていますが、NodePool カスタムリソースの spec.disruption.consolidationPolicy によって設定を変更することが可能です。
spec:
disruption:
consolidationPolicy: WhenEmptyOrUnderutilizedConsolidation の魅力
consolidationPolicy は、WhenEmpty と WhenEmptyOrUnderutilized の 2 つの設定値から選択して指定します。デフォルトは WhenEmptyOrUnderutilized です。WhenEmpty を指定した場合、ワークロードとして動く Pod を含まないノードのみを Consolidation の対象とします。WhenEmptyOrUnderutilized を指定した場合、すべてのノードを Consolidation の対象とみなし、ノードが空であるか、十分に活用されておらずコスト削減のために変更できると判断した場合に、ノードの削除または置換を試みます。
以上をまとめると、Karpenter は、ノードのリソースに余剰がある場合、他のノードに Pod を退避させたうえで当該ノードを削除したり、より安いノードに置き換えられる場合にノードを置き換えたりしてくれます。こういったコスト最適化の仕組みを、ユーザーが複雑な設定をしなくても利用できるというのが「Consolidation」という機能の魅力、というわけです。
Consolidation の実装にちょっぴり Dive Deep
ここからは、実際に Karpenter のソースコードを読みながら「Consolidation」機能の実装にちょっぴり Dive Deep していきます。Karpenter はオープンソースのため、ソースコードは GitHub 上に公開されています。
本記事では、以下のリポジトリとバージョンを対象に、コードを読んでいきます。
-
対象リポジトリ : kubernetes-sigs/karpenter
-
リリースバージョン : v1.0.0
AWS (Amazon EKS) は Karpenter によってサポートされた最初のクラウドプロバイダーです。逆に言えば、Karpenter は他のクラウドプロバイダーでも利用できるような設計になっています。特定のクラウドプロバイダーに依存しない部分は kubernetes-sigs/karpenter にて開発され、特定のクラウドプロバイダーに依存する部分については、別のリポジトリに切り出されて開発がおこなわれています。AWS で Karpenter を利用する場合の実装は karpenter/aws-provider-karpenter で確認することが可能です。
さて、先ほど Karpenter による Node の中断は Disruption Controller によっておこなわれると説明しました。そこで、まずはじめに Disruption Controller の実装から Consolidation の処理を追っていきます。
Reconcile 処理
Disruption Controller の Reconcile 処理は pkg/controllers/disruption/controller.go にあります。
func (c *Controller) Reconcile(ctx context.Context) (reconcile.Result, error) {
ctx = injection.WithControllerName(ctx, "disruption")
// this won't catch if the reconcile loop hangs forever, but it will catch other issues
c.logAbnormalRuns(ctx)
defer c.logAbnormalRuns(ctx)
c.recordRun("disruption-loop")Reconciliation Loop
Reconcile はコントローラーのコアロジックに当たります。Kubernetes には「あるべき状態と実際のシステムの状態を比較し、差分が存在したらそれを解消するための処理を実行」する Reconciliation Loop というコンセンプトがあります。Karpenter では (controller-runtime というライブラリを使ってコントローラーを開発する場合は) Reconcile 処理を reconcile.Reconcile インタフェースを実装することで実現します。
Disruption 処理のループ
Reconcile メソッドの処理を上から読んでいくと、次のような処理 が実装されています。ここでは c.methods スライスの各要素 (メソッド) に対してループを実行しています。そして c.disrupt(ctx, m) を呼ぶことで、現在のメソッド m を使って disrupt (中断) を試みています。
// Attempt different disruption methods. We'll only let one method perform an action
for _, m := range c.methods {
c.recordRun(fmt.Sprintf("%T", m))
success, err := c.disrupt(ctx, m)
if err != nil {
return reconcile.Result{}, fmt.Errorf("disrupting via %q, %w", m.Type(), err)
}
if success {
return reconcile.Result{RequeueAfter: singleton.RequeueImmediately}, nil
}
}c.methods の定義
c.methods のスライスの各要素には何が格納されているのかについては、こちら に定義されています。
methods: []Method{
// Expire any NodeClaims that must be deleted, allowing their pods to potentially land on currently
NewExpiration(clk, kubeClient, cluster, provisioner, recorder),
// Terminate any NodeClaims that have drifted from provisioning specifications, allowing the pods to reschedule.
NewDrift(kubeClient, cluster, provisioner, recorder),
// Delete any remaining empty NodeClaims as there is zero cost in terms of disruption. Emptiness and
// emptyNodeConsolidation are mutually exclusive, only one of these will operate
NewEmptiness(clk, recorder),
NewEmptyNodeConsolidation(c),
// Attempt to identify multiple NodeClaims that we can consolidate simultaneously to reduce pod churn
NewMultiNodeConsolidation(c),
// And finally fall back our single NodeClaim consolidation to further reduce cluster cost.
NewSingleNodeConsolidation(c),
},3 つのメソッド定義
このオブジェクトスライスの定義を読むと、Consolidation に関連しそうな 3 つのメソッド (NewEmptiness、NewMultiNodeConsolidation、NewSingleNodeConsolidation) が定義されていることがわかります。
先ほど Consolidation によって行われる具体的な動作は 3 種類ある (Empty Node Consolidation、Multi Node Consolidation、Single Node Consolidation) と説明しましたが、コードで定義された 3 つがそれに該当しそうですね。
例えば、Single Node Consolidation に焦点を当ててコードを読んでいく場合は pkg/controllers/disruption/singlenodeconsolidation.go から追っていくとよさそうです。
singlenodeconsolidation.go
コード
// ComputeCommand generates a disruption command given candidates
// nolint:gocyclo
func (s *SingleNodeConsolidation) ComputeCommand(ctx context.Context, disruptionBudgetMapping map[string]map[v1.DisruptionReason]int, candidates ...*Candidate) (Command, scheduling.Results, error) {
if s.IsConsolidated() {
return Command{}, scheduling.Results{}, nil
}disrupt() メソッドを呼ぶ
少し話を戻しましょう。disrupt() メソッド を呼ぶことで、上に挙げたようなメソッドを使ってノードの disrupt (中断) を試みていました。disrupt() というメソッドの中身についても見ていきます。
func (c *Controller) disrupt(ctx context.Context, disruption Method) (bool, error) {
・・・GetCandidates 関数
コードを追っていくと、GetCandidates 関数 で中断の対象となるノードの候補 (candidates) を選んでいることがわかります。
candidates, err := GetCandidates(ctx, c.cluster, c.kubeClient, c.recorder, c.clock, c.cloudProvider, disruption.ShouldDisrupt, disruption.Class(), c.queue)ComputeCommand メソッドを呼ぶ
次に ComputeCommand メソッド を呼んでいます。このメソッドは、候補となったノードを引数として渡すことで、その候補ノードが中断の対象になるかを計算しています。
// Determine the disruption action cmd, schedulingResults, err := disruption.ComputeCommand(ctx, disruptionBudgetMapping, candidates...) if err != nil { return false, fmt.Errorf("computing disruption decision, %w", err) } if cmd.Decision() == NoOpDecision { return false, nil }executeCommand メソッドを呼ぶ
さらに追っていくと、executeCommand メソッド を呼ぶことでノードの中断を試みていることがわかります。
// Attempt to disrupt
if err := c.executeCommand(ctx, disruption, cmd, schedulingResults); err != nil {
return false, fmt.Errorf("disrupting candidates, %w", err)
}
return true, nilexecuteCommand メソッドの実装
では最後に、少しだけ executeCommand メソッド の実装にも目を通してみましょう。コメントを読むと、新しい Pod が古いノードにスケジューリングされないように、代替ノードを起動する前に古いノードに NoScedule Taint を付与した後に、代替ノードを起動し、中断の候補となるノードの削除待機コマンドをキューに追加するメソッドであることがわかります。
// executeCommand will do the following, untainting if the step fails.
// 1. Taint candidate nodes
// 2. Spin up replacement nodes
// 3. Add Command to orchestration.Queue to wait to delete the candiates.
func (c *Controller) executeCommand(ctx context.Context, m Method, cmd Command, schedulingResults scheduling.Results) error {
・・・置換ノードの作成
これらの処理のうち「代替となるノードの起動」を担う部分のコードをピックアップしてみましょう。cmd.replacements スライスに要素がある場合、置換ノードを作成する処理がおこなわれます。新しいノードをプロビジョニングする方法がない状態でワークロードが中断させることを防ぐため、置換ノードの作成に失敗した場合には中断を行わないという方針がコメントに明記されていますね。
if len(cmd.replacements) > 0 {
if nodeClaimNames, err = c.createReplacementNodeClaims(ctx, m, cmd); err != nil {
// If we failed to launch the replacement, don't disrupt. If this is some permanent failure,
// we don't want to disrupt workloads with no way to provision new nodes for them.
return multierr.Append(fmt.Errorf("launching replacement nodeclaim (command-id: %s), %w", commandID, err), state.RequireNoScheduleTaint(ctx, c.kubeClient, false, stateNodes...))
}
}ソースコードは GitHub 上で公開
さて、長くなってきたので実装へのちょっぴり Dive Deep は一旦ここで終了します。Karpenter はオープンソースであり、そのソースコードは GitHub 上で公開されています。コードを読み込むことで、Karpenter の機能の実装についてより深い理解が得られることがおわかりいただけたのではないでしょうか。
まとめ
Karpenter の Consolidation は、Kubernetes クラスターの効率性とコスト最適化を自動的に行う強力な機能です。ソースコードを読み解くことで、その仕組みと魅力をより深く理解できます。この機能を活用することで、クラスター運用の効率化とコスト削減を同時に実現することができるでしょう。
Karpenter の開発は日々進んでおり、今後もさらなる機能強化が期待されます。オープンソースプロジェクトとして、コミュニティからの貢献も歓迎されているので、興味のある方はぜひ参加してみてはいかがでしょうか。
「もっと Karpenter について知りたい !」という方は、僕の同僚が AWS Summit Japan 2024 で「Amazon EKS + Karpenter で始めるスケーラブルな基盤作り」という講演をおこなっているので、ぜひ併せてご覧ください。
最後になりますが、今回は「Consolidation」という機能に焦点を当てて解説しました。もしリクエストがあれば別の機能にフォーカスを当てた記事の執筆も検討しているので、ぜひ SNS などでのシェアをお願いします !
筆者プロフィール
後藤 健汰 (ごとけん / @kennygt51)
アマゾン ウェブ サービス ジャパン合同会社
技術統括本部 デジタルサービス技術本部 ISV/SaaS ソリューション部
ソリューションアーキテクト
SaaS 事業者でのインフラエンジニアを経験後、2022 年に AWS Japan に入社。現在は ISV/SaaS 領域のお客様を中心に技術支援をおこなっています。Kubernetes と Platform Engineering に興味があります。ホームサウナは「サウナ東京」です。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages