- AWS Builder Center›
- builders.flash
はじめに
SaaS 開発・運用に携わるみなさん、こんにちは。AWS で SaaS に特化した技術支援を行なっているパートナーソリューションアーキテクトの櫻谷です。
これまでコンテナサービスを活用したマルチテナント SaaS の構成例 (Amazon ECS 編 / Amazon EKS 編) についてご紹介してきた本連載ですが、最終回となる今回は、サーバーレスサービスによるアーキテクチャパターンを取り上げます。サーバーレスは、クラウドやモダンアプリケーション開発の文脈でコンテナとともに注目されることが多い技術ですが、SaaS との相性の良さはまだあまり知られていません。この記事では、まずサーバーレスの性質を改めて理解し、それが SaaS 実装にまつわる課題に対してどのようにアプローチできるかを確認します。その後、AWS が提供するサーバーレスサービスを活用したリファレンスアーキテクチャの中身を深掘りし、より実践的な実装パターンについてご説明していきます。これまでに紹介してきたコンテナサービスによる実装パターンとどこが異なるか、また、どこが共通しているかを考えながら読み進めていくのもおもしろいかもしれません。
builders.flash メールメンバー登録
サーバーレスとは
サーバーレスとは、開発者にサーバーの存在を意識させることなくアプリケーションの開発や実行、デプロイを可能にする技術や方法論を指す用語です。これは、クラウドの普及に伴い、クラウドプロバイダーが管理するマネージドなサーバーレスサービスが提供されることで可能になった比較的新しい技術です。
サーバーレスの強みは、面倒なことをサービスプロバイダーに丸投げできることです。自分でパッチ当てなど実行環境のメンテナンスをする必要もなければ、高可用性の担保や、負荷に応じたリソースの調整を気にする必要もありません。これらはすべて、設定に応じてサービスプロバイダーが自動で管理してくれます。また、料金は使った分だけの従量課金制のため、コスト削減にも効果があります。これらのサーバーレスの性質によって、開発者はコアビジネスに注力することができ、より多くのイノベーションを早い速度で実現できるようになります。
勘の良い方であればすでにお気づきかもしれませんが、これはまさに SaaS が目指すところと一致しています。SaaS の目的は、コストの削減や運用効率の向上、ビジネスのスケーリングであり、サーバーレスを活用することでこれらの実現を加速させることができます。特に、マルチテナント SaaS では各テナントの負荷を予測することが難しいため、サーバーレスの大規模で高速なスケーリングモデルによる恩恵を受けられることが多いでしょう。
サーバーレスリファレンスアーキテクチャ
このような利点を備えた AWS のサーバーレスサービスを活用して構成されたマルチテナント SaaS アーキテクチャが、サーバーレス SaaS リファレンスアーキテクチャです。コンピューティングに AWS Lambda、データベースに Amazon DynamoDB、API の公開に Amazon API Gateway、認証に Amazon Cognito など、可能な限りサーバーを意識しなくても済むような設計が採用されています。
サンプルの E コマースアプリケーションやコントロールプレーンの部分は、ECS 編 や EKS 編 で解説したものと共通しているため、この記事ではサーバーレス特有の考慮事項に焦点を当てて解説します。
※記事執筆時点で最新の main ブランチの バージョン を元にしています。最新のコードとは異なる可能性がありますのでご注意ください)。また、README にあるように SaaS Builder Toolkit for AWS (SBT) をベースにした構成にアップデートされているため、ドキュメント には一部古い情報が含まれていることにご注意ください (※例えば、Shared Services は SBT によって提供されるようになっています)。
アーキテクチャの全体像
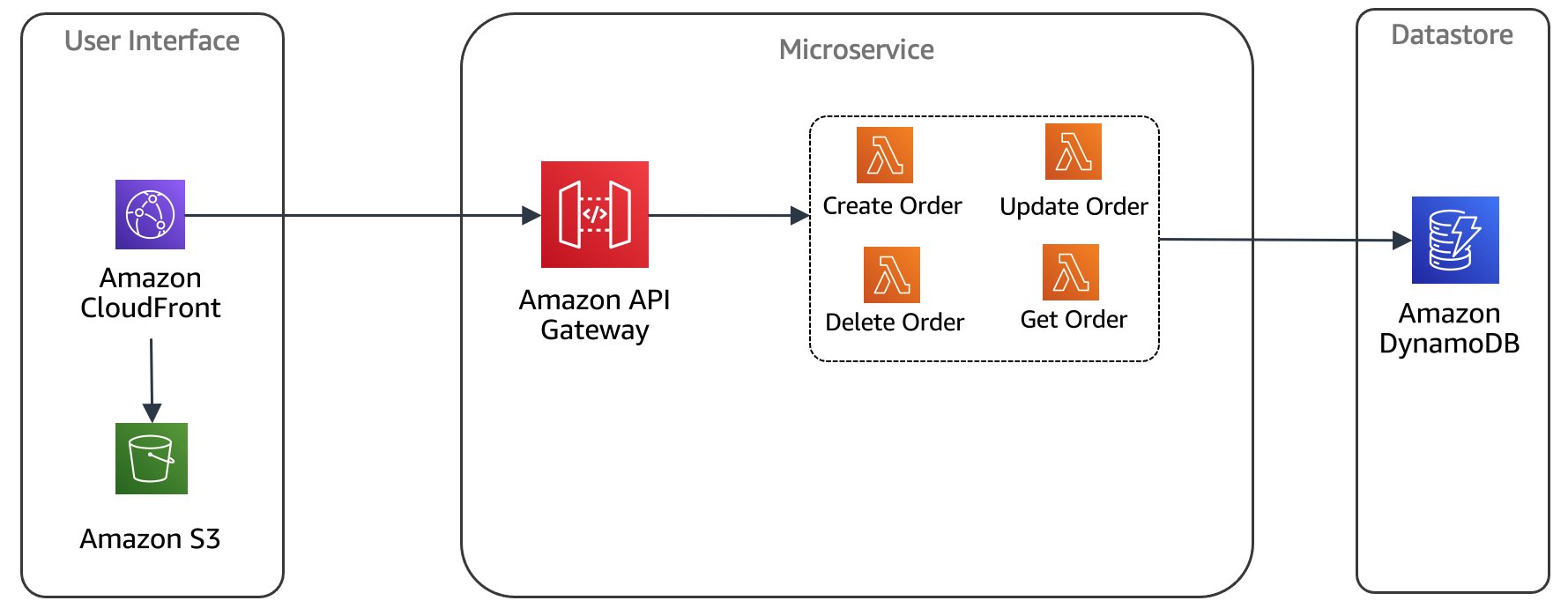
まずは、全体の構成を確認しましょう。これまでと同じく、SBT を使ってコントロールプレーンが導入されており、アプリケーションプレーンはサーバーレスサービスを使った構成となっています。具体的には、API Gateway を通じて受信したリクエストは、複数の Lambda 関数から成るマイクロサービスによって処理され、データは Amazon DynamoDB で管理されます。

図1: アーキテクチャ概要
アプリケーションの中身は ECS および EKS 編で見たリファレンスとほとんど同じです。SaaS プロバイダーが利用する管理者用コンソールと、テナントが利用する E コマースアプリケーションがあり、E コマースアプリケーションは商品サービスと注文サービスの 2 つのマイクロサービスで構成されています。この記事ではサーバーレスに焦点を当てるため、詳細については省略します。気になる方は ECS 編の記事 をご覧ください。
アプリケーションプレーンの構成
アプリケーションのデプロイモデルは、テナントのティアによって異なります。このリファレンスソリューションでは、各テナントはベーシック、スタンダード、プレミアム、プラチナの 4 つのティアから 1 つを選んで契約します。最上位のプラチナティアを契約した場合、そのテナント専用のリソース (Lambda 関数や DynamoDB テーブル) がプロビジョニングされるサイロモデルでデプロイされます。それ以外のティアのテナントは、同じ 1 つのリソースを共有して使用するプールモデルでデプロイされます。
インフラストラクチャは AWS CDK を使って構築されています。以下の図は、初回の環境構築時にデプロイされるリソースを表す概念図です。これには、SBT を使って作成するコントロールプレーン、複数のテナントで共有するプール環境、ティアごとの使用量プランや API キー、共通処理の Lambda レイヤーなどが含まれます。また、図には記載されていませんが、各テナント環境のアプリケーションのアップデートを行うためのデプロイパイプラインも作成されます。

図2: 環境構築時のベースラインアーキテクチャ
ここで 1 つ注目しておきたいのがアプリケーションのプール環境です。テナントがまだ 1 つも存在していない状態でも、すぐに利用可能なようにあらかじめ環境がプロビジョニングされています。従来のサーバーベースのソリューションでは、ここでアイドル状態のリソースが無駄なコストを生み出してしまいますが、前述の通りサーバーレスはリクエスト量に応じて課金が行われるため、ほとんどの場合リソースを作成しただけでは料金が発生しません。これは、需要の予測が難しいマルチテナント環境では特に効果的です。テナントがデプロイされた後でも、リクエストの増減に合わせてちょうど使った分だけの課金が発生するため、従来の「アイドル状態のコスト」という概念そのものがなくなるからです。
フロントエンドにはこれまでと同様に Amazon CloudFront と Amazon S3 を使用し、API Gateway を通じてバックエンドにアクセスします。データストアについては、テナントのティアによって分離レベルが異なります。どちらも DynamoDB を使用していますが、プラチナティアのテナントには専用のテーブルが作成されるのに対して、その他のティアでは 1 つのテーブルを共有し、パーティションキーにテナント識別子を含めることで、どのテナントに属するデータかを判別できるようにしています。実際のワークロードでは、データのアクセスパターンや、セキュリティ、パフォーマンス、コンプライアンス要件、コスト効率などを考慮して、自社のソリューションに最適なティアとデプロイモデルの組み合わせを検討してください。
オンボーディング
SBT を導入しているため、オンボーディングのフローは SBT 側でトリガーおよびオーケストレーションされます。管理者用のアプリケーションからテナントを作成すると、コントロールプレーンの API が呼び出され、DynamoDB にテナントのデータが登録されます。ここまでは SBT によるデフォルトの処理ですが、このソリューション特有のタスクを行うために、ScriptJob (旧 JobRunner) を使用して追加のカスタムスクリプトも実行しています。
server/scripts/provision-tenant.sh
以下はそのスクリプトの抜粋ですが、登録したテナントがプラチナティアの場合、専用リソースのプロビジョニングを行う必要があるため、CDK を使ってデプロイしているところです。API Gateway、Lambda 関数、DynamoDB テーブル、Cognito ユーザープールなどが作成されます。
# Deploy the tenant template for platinum tier(silo)
if [[ $TIER == "PLATINUM" ]]; then
STACK_NAME="serverless-saas-ref-arch-tenant-template-$CDK_PARAM_TENANT_ID"
export CDK_PARAM_CONTROL_PLANE_SOURCE='sbt-control-plane-api'
export CDK_PARAM_ONBOARDING_DETAIL_TYPE='Onboarding'
export CDK_PARAM_PROVISIONING_DETAIL_TYPE=$CDK_PARAM_ONBOARDING_DETAIL_TYPE
export CDK_PARAM_OFFBOARDING_DETAIL_TYPE='Offboarding'
export CDK_PARAM_DEPROVISIONING_DETAIL_TYPE=$CDK_PARAM_OFFBOARDING_DETAIL_TYPE
export CDK_PARAM_PROVISIONING_EVENT_SOURCE="sbt-application-plane-api"
export CDK_PARAM_APPLICATION_NAME_PLANE_SOURCE="sbt-application-plane-api"
cdk deploy $STACK_NAME --require-approval never
fiテナントで、ユーザープールに最初の管理者ユーザーとグループを作成
また、ティアに関わらずすべてのテナントで、ユーザープールに最初の管理者ユーザーとグループを作成し、そのグループに管理者ユーザーを追加することも行なっています。
# Create tenant admin user
aws cognito-idp admin-create-user \
--user-pool-id "$SAAS_APP_USERPOOL_ID" \
--username "$TENANT_ADMIN_USERNAME" \
--user-attributes Name=email,Value="$TENANT_ADMIN_EMAIL" Name=email_verified,Value="True" Name=phone_number,Value="+11234567890" Name="custom:userRole",Value="TenantAdmin" Name="custom:tenantId",Value="$CDK_PARAM_TENANT_ID" Name="custom:tenantTier",Value="$TIER" \
--desired-delivery-mediums EMAIL
# Create tenant user group
aws cognito-idp create-group \
--user-pool-id "$SAAS_APP_USERPOOL_ID" \
--group-name "$CDK_PARAM_TENANT_ID"
# Add tenant admin user to tenant user group
aws cognito-idp admin-add-user-to-group \
--user-pool-id "$SAAS_APP_USERPOOL_ID" \
--username "$TENANT_ADMIN_USERNAME" \
--group-name "$CDK_PARAM_TENANT_ID"作成されたリソースとテナントを紐付けた情報を保管用に残す
最後に、作成されたリソースとテナントを紐付けた情報を保管用に残しておきます。このデータは、後ほど認証の部分でも使用します。
# Create JSON response of output parameters
export tenantConfig=$(jq --arg SAAS_APP_USERPOOL_ID "$SAAS_APP_USERPOOL_ID" \
--arg SAAS_APP_CLIENT_ID "$SAAS_APP_CLIENT_ID" \
--arg API_GATEWAY_URL "$API_GATEWAY_URL" \
-n '{"userPoolId":$SAAS_APP_USERPOOL_ID,"appClientId":$SAAS_APP_CLIENT_ID,"apiGatewayUrl":$API_GATEWAY_URL}')
export tenantStatus="Complete"処理完了
処理が完了すると、テナント管理者ユーザーにパスワードを通知するメールが届き、アプリケーションを利用できるようになります。また、他のリファレンスアーキテクチャと同様に、管理者ユーザーは他のテナントユーザーを作成することができ、一般のテナントユーザーは、注文、商品に関する CRUD 処理を行うことができます。
認証
認証にはこれまでと同様に Cognito を使用しています。プール環境の共有ユーザープール内には、テナントごとにグループが作成され、テナントごとにユーザーは論理的に分離されます。一方、サイロ環境では個別の専用ユーザープールが作成されます。しかし、サインインを行うフロントエンドのページは、すべてのテナントで共有されています。未認証の状態では、アクセス元のユーザーがどのテナントに属しているかを知ることはできないはずですが、認証先のユーザープールをどのように特定しているのでしょうか?
これを解決する手段はいくつかありますが、このソリューションでは認証に追加の 1 ステップを設け、先にテナント名を入力させる方法を採用しています。
(図3: テナント名を入力するサインインの画面)
テナント名を入力して送信
ここでテナント名を入力して送信すると、コントロールプレーンの GET tenant-config/{tenantName} が呼び出され、このテナントに関するメタデータを取得してきます。コントロールプレーンが利用する DynamoDB テーブルにはテナント管理用の様々な情報が保存されており、その中には先ほどオンボーディングの処理内で export していた tenantConfig もあります。
{
"userPoolId": "us-west-2_2EEEXZ51f",
"appClientId": "7terkehljf7b2m2evgne50ddps",
"apiGatewayUrl": "https://4jaef73j55.execute-api.us-west-2.amazonaws.com/prod/"
}client/Application/src/app/views/auth/auth-configuration.service.ts
取得したデータは、一時的にブラウザのローカルストレージに保存されます。
public setTenantConfig(tenantName: string): Promise<any> {
const url = `${environment.regApiGatewayUrl}/tenant-config/` + tenantName;
this.params$ = this.http.get<string>(url);
const setup$ = this.params$.pipe(
map((val:unknown) => {
// remove trailing slash (/) if present
console.log("setTenantConfig val: ", val);
this.params = val as ConfigParams;
this.params.apiGatewayUrl = this.params.apiGatewayUrl.replace(
/\/$/,
''
);
localStorage.setItem('userPoolId', this.params.userPoolId);
localStorage.setItem('tenantName', tenantName);
localStorage.setItem('appClientId', this.params.appClientId);
localStorage.setItem('apiGatewayUrl', this.params.apiGatewayUrl);ユーザー認証ページでログイン
その 他の実装方法
API の認可、スロットリング
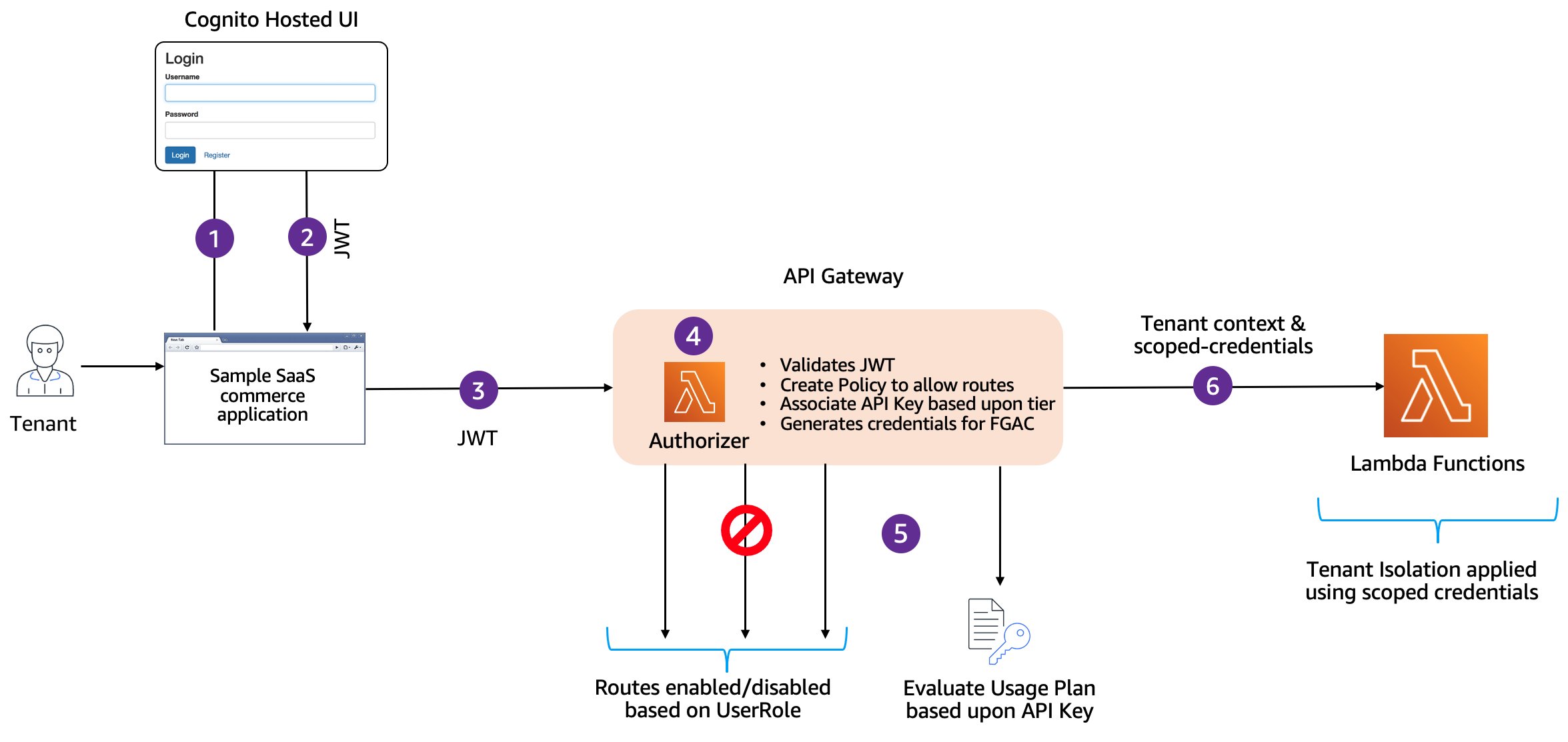
バックエンドのマイクロサービスに対する認証・認可は、API Gateway のレイヤーで Lambda オーソライザーを使用して実施されます。この Lambda オーソライザーは、認可やテナント分離、スロットリングを実現するために非常に多くの機能を担っている重要な関数です。一部の詳細については ECS 編の記事 で解説していますのでここでは省略しますが、JWT の検証、トークンからテナントコンテキストの抽出、ティアに応じた API キーの取得、コンテキスト変数への追加、認可ポリシーの作成などを行なっています。
API キーと使用量プランは環境構築時に作成済みです。リクエスト元のテナントのティアに応じたキーの取得と割り当ては、Lambda オーソライザーが行います。「API キーによるスロットリング」と聞くと、API を呼び出すクライアント側がリクエストにキーを付与するものとイメージする方も多いと思いますが、ここではクライアント側に API キーはありません。apiKeySource に AUTHORIZER を指定し、usageIdentifierKey プロパティの値として API キーを Lambda オーソライザーの出力に追加することで、スロットリングを適用することができます。実装の詳細については ドキュメント をご覧ください。
(図5: Lambda オーソライザーの動作)
server/cdk/lib/tenant-template/usage-plans.ts
ティアごとのクォータやレートを変更したい場合は、以下の箇所のコードを変更してみてください。
if (props.isPooledDeploy) {
this.usagePlanBasicTier = props.apiGateway.addUsagePlan('UsagePlanBasicTier', {
quota: {
limit: 1000,
period: Period.DAY,
},
throttle: {
burstLimit: 50,
rateLimit: 50,
},
});テナント分離
テナント分離に関する検討を行うためには、利用しているサーバーレスサービスの裏側の仕組みを正しく理解することが不可欠です。フロントエンドと API Gateway の認証・認可についてはすでに確認したので、メインとなるのはコンピューティング (Lambda) とデータベース (DynamoDB) のレイヤーです。
(図 6: アプリケーションの構成)
プール環境の構成
先にプール環境の構成について確認しましょう。プール環境では複数のテナントが同一の Lambda 関数を共有し、データは単一の DynamoDB テーブル内に混在する形になっています。どのテナントのデータかは、パーティションキーの値から識別することができます。また、リクエスト元のテナントは、先ほど解説した Lambda オーソライザーで抽出できます。
Lambda のテナント分離を考えるにあたってまず注意すべきポイントは、Lambda の実行モデルです。下の図は、Lambda が受信したリクエスト (イベント) をどのように処理するかを表したものです。オレンジの丸が実行環境の 1 つを表しており、Lambda はすべてのリクエストをできる限り効率的に処理できるように、自動で実行環境をスケーリングします。処理が完了した実行環境は解放され、次のリクエストの処理に利用できるようになります。
(図7: Lambda の実行モデル)
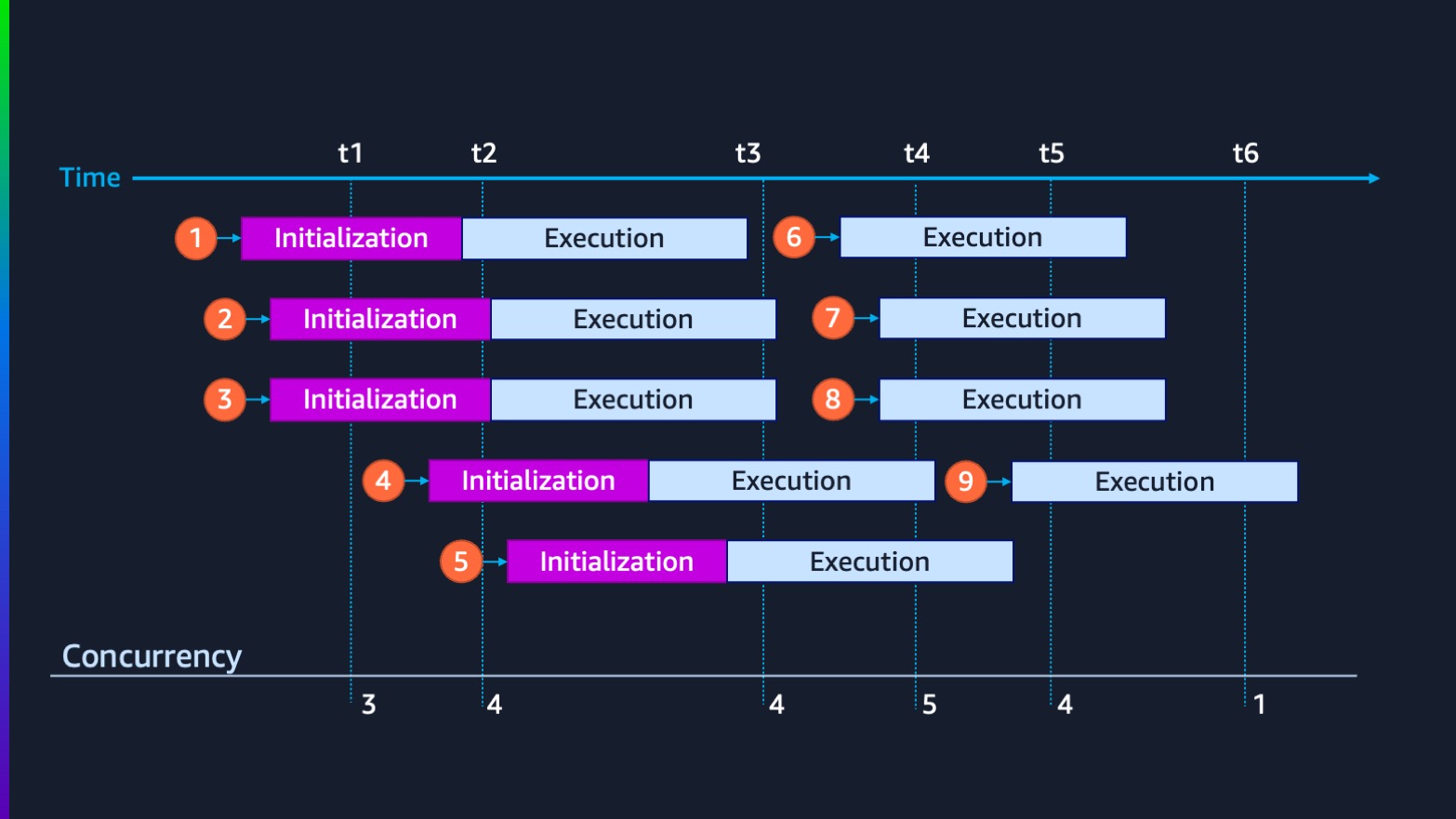
プール環境における留意すべき点
実行環境が再利用される可能性のある Lambda の実行モデルでは、複数の呼び出しで共通して利用するデータなどを関数ハンドラー外で定義したり、一時ディレクトリである /tmp でキャッシュすることがベストプラクティスとされていますが、プール環境でこれを行うのは注意が必要です。というのも、同じ実行環境が複数のテナントのリクエストの処理に使用される可能があるため、意図しないデータアクセスを引き起こすリスクがあります。テナント固有のデータについてはキャッシュせず、実行環境をステートレスに保つようにコーディングを行うことで、より強固なテナント分離を実現することが可能になります。
実行ロール
Lambda のテナント分離におけるもう 1 つの鍵は、実行ロールです。Lambda では関数ごとに実行ロールと呼ばれる IAM ロールをアタッチして、他の AWS サービスに対するアクセスを管理します。今回の例で言うと、関数内では DynamoDB テーブルに対するデータの読み書きが発生するため、DynamoDB の必要なアクションを許可した IAM ポリシーを定義する必要があります。試しに、注文の作成を担う Lambda 関数にアタッチされているポリシーを見てみましょう。
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"xray:PutTelemetryRecords",
"xray:PutTraceSegments"
],
"Resource": "*",
"Effect": "Allow"
},
{
"Action": [
"dynamodb:BatchWriteItem",
"dynamodb:DeleteItem",
"dynamodb:DescribeTable",
"dynamodb:PutItem",
"dynamodb:UpdateItem"
],
"Resource": [
"arn:aws:dynamodb:us-west-2:123456789:table/serverless-saas-ref-arch-tenant-template-pooled-ServicesOrderMicroserviceTable53CF6217-1J6YZZIPYEJ93"
],
"Effect": "Allow"
}
]
}リクエストに行っているテナントに合わせて、動的にアクセス範囲を絞り込む
上はトレースを取得するための AWS X-ray のアクセス権限で、下がデータアクセス用の DynamoDB テーブルに対する権限です。Resource でテーブルが指定されています。テーブル名に pooled とあるように、これはプール環境で共有しているテーブルを表しており、テーブル内のすべてのレコードに対する書き込みが許可されている状態です。複数のテナントからのリクエストを処理しなければいけない都合上、Lambda 関数にはこのような広めの権限を付与する必要がありますが、これではテナント分離は十分ではありません。実際は、リクエストを行なっているテナントに合わせて、動的にアクセス範囲を絞り込む必要があります。
これには、すでに ECS 編 で紹介した行レベルセキュリティの仕組みを活用することができます。IAM ポリシーの Condition として dynamodb:LeadingKeys を定義すればよいのですが、このポリシーの作成と一時クレデンシャルの生成も、先ほど説明した Lambda オーソライザーの責務です。
server/src/OrderService/order_service_dal.py
ここで生成されたクレデンシャルを使用して、AWS サービスへのアクセスを行います。AWS SDK for Python (Boto3) でアクセスキーとシークレットキーを直接指定してセッションオブジェクトを作成することで、Lambda 関数にアタッチされた実行ロールとは別の、アクセス元のテナントにスコープが絞られた動的なポリシーを適用することができます。
def __get_dynamodb_table(event, dynamodb):
""" Determine the table name based upo pooled vs silo model
Args:
event ([type]): [description]
Returns:
[type]: [description]
"""
if (is_pooled_deploy=='true'):
accesskey = event['requestContext']['authorizer']['accesskey']
secretkey = event['requestContext']['authorizer']['secretkey']
sessiontoken = event['requestContext']['authorizer']['sessiontoken']
dynamodb = boto3.resource('dynamodb',
aws_access_key_id=accesskey,
aws_secret_access_key=secretkey,
aws_session_token=sessiontoken
)
else:
if not dynamodb:
dynamodb = boto3.resource('dynamodb')
return dynamodb.Table(table_name)サイロ環境の場合
ノイジーネイバー
ノイジーネイバーの問題については、この連載では API Gateway で使用量プランを用いたスロットリングで対処するように説明してきました。しかし、サーバーレスのアーキテクチャでは、この課題への対策を検討する必要がある別のレイヤーが登場します。それは、Lambda のサービスクォータ です。同時実行数の上限はデフォルト 1,000 (※引き上げ可能) となっていますが、このクォータは、同一リージョン内のすべての関数が共有します。つまり、極端に高頻度で呼び出されたり、処理に時間のかかる関数があると、それ以外の関数がスロットリングされる可能性があるということです。
また、マルチテナント環境においては、ティアという観点でもこれらに注意を払う必要があります。今回のアーキテクチャではプラチナティアに専用の Lambda 関数がデプロイされていますが、これはプール環境の Lambda 関数と同一アカウント、同一リージョン内に存在します。つまり、これらの関数は同じクォータを共有しているということです。そのため、ベーシックティアのテナントからのリクエストが大量に発生した場合、プラチナティアのテナントの処理にも影響が発生する可能性があります。
確かに、前段の API Gateway によるスロットリングでも、この問題への対処はある程度は可能でしょう。しかし、Lambda の実行時間や各テナントのリクエストレートを精緻に見積もることは難しく、Lambda のレイヤーでノイジーネイバーが発生するリスクを完全に排除することはできません。そこで、このソリューションでは、Lambda 関数単位での同時実行数を制御することができる 予約済み同時実行数 を導入しています。関数ごとに予約済み同時実行数を設定することで、実行環境のスケールアウトをコントロールすることができるようになります。これは、ティアや機能ごとに SLA が設定されている場合などで特に有効です。
server/cdk/bin/serverless-saas-ref-template.ts
このソリューションでは、デフォルトの予約済み同時実行数を 1 と定義していますが、パラメータによって設定を上書きできるようにしています。
const defaultLambdaReserveConcurrency = '1';
const lambdaReserveConcurrency = Number(
process.env.CDK_PARAM_LAMBDA_RESERVE_CONCURRENCY || defaultLambdaReserveConcurrency
);server/scripts/provision-tenant.sh
例えば、プラチナティアのサイロ環境ではもっと増やしたいという場合は、以下のようにコードを変更します。
# Deploy the tenant template for platinum tier(silo)
if [[ $TIER == "PLATINUM" ]]; then
...
# 以下の1行を追加
export CDK_PARAM_LAMBDA_RESERVE_CONCURRENCY="10"
cdk deploy $STACK_NAME --require-approval never
fi継続的なモニタリング
デプロイ戦略
今回のように複数テナントで共有するプール環境とプラチナティアのテナント専用のサイロ環境が混在している場合、アプリケーションの可用性を最大化するために、複雑なデプロイ戦略を導入することがあります。この戦略にはいくつかの種類がありますが、共通する考え方としては、環境をいくつかのグループに分け、段階的に最新のバージョンをロールアウトしていくというものです。このソリューションでは、環境ごとに waveNumber を設定した wave-based デプロイを採用しています。
これは、環境構築時に ServerlessSaaSPipeline スタックがデプロイされており、主に AWS CodePipeline と AWS Step Functions を使用して実装されています。各テナント環境にはオンボーディング時に waveNumber が割り当てられており、アプリケーションの更新時にはこの数値に基づいて段階的にデプロイが進みます。
ステートマシンの起動
具体的には、まずスタック ID や waveNumber など各テナント環境のデータを取得する Lambda 関数が実行され、以下のような値を入力としてステートマシンが起動します。
{
"stacks": [
{
"stackName": "serverless-saas-ref-arch-tenant-template-pooled",
"tenantId": "pooled",
"commitId": "rs_CaHKHetb8eZr0e68lzxQhCjcw2.CY",
"waveNumber": 1
},
{
"stackName": "serverless-saas-ref-arch-tenant-template-e54440d9-dfad-4822-8a86-db06b8f9f04f",
"tenantId": "e54440d9-dfad-4822-8a86-db06b8f9f04f",
"commitId": "rs_CaHKHetb8eZr0e68lzxQhCjcw2.CY",
"waveNumber": 2
},
{
"stackName": "serverless-saas-ref-arch-tenant-template-53fb645c-1170-4976-8db9-78ee3342ba1e",
"tenantId": "53fb645c-1170-4976-8db9-78ee3342ba1e",
"commitId": "rs_CaHKHetb8eZr0e68lzxQhCjcw2.CY",
"waveNumber": 3
}
]
}詳細なワークフロー
詳細なワークフローは Step Functions で定義されているので確認してみましょう。
大まかな流れ
大まかな流れとしては、以下のようなステップを踏んでいます。
- wave の数だけイテレーションを回し、各環境に Map 処理を実行。対象の waveNumber が設定されている環境であれば、cdk deploy を実行。対象外であればデプロイをスキップする。
- wave の処理が完了後、承認ステップを挟む。新しいデプロイが問題なく機能しているかを確認し、承認作業を行う (※具体的な処理は未実装。Step Functions のコールバックパターンを利用しており、Amazon SQS のメッセージからタスクトークンを確認可能)。
- 承認されたら、次の wave に進む。
どのように waveNumber を設計すればよいかは、ソリューションの性質やビジネス要件に依存するため一概には言えません。例えば、重要な顧客への影響を避けるために下位のティアから優先的にデプロイして動作を検証したい場合もあれば、長く利用してくれているヘビーユーザーに対していち早くベータ機能をリリースしてフィードバックを集めるという考え方もあります。この分野をもっと掘り下げてみたい方は、セルベースアーキテクチャを題材にしたワークショップなどもあるのでぜひ参考にしてみてください。
Lambda レイヤー
最後に、運用の側面についても軽く触れておきたいと思います。マルチテナント SaaS では、運用においてもテナントの存在を強く意識した設計と実装が不可欠です。特にログやメトリクス、トレースなどのテレメトリデータを、テナントレベルでドリルダウンして検索・分析・表示できるように、収集の仕組みを検討しておく必要があります。
具体的には、それぞれのデータにテナント ID のようなコンテキスト情報を付与する必要があるのですが、これを各開発者に意識させて個別で実装してもらうのは現実的ではありません。共通処理としてライブラリ化し、開発者にテナントの存在を意識させないことが、生産性の面からも、そして強固なテナント分離を実現するためにも有効と言えるでしょう。
アプリケーションが Lambda で実装されている場合、これは Lambda レイヤーを用いることで簡単に実現することができます。
server/src/layers/logger.py
例えば、logger.py にはテナント ID を付与した上で構造化したログを出力するためのヘルパー関数が用意されています。テナント ID の抽出も前述の Lambda オーソライザーによって処理されているため、各アプリケーションサービスの開発者は特に意識せずともテナントコンテキストを含む標準化されたログの出力を実現することができます。
"""Log with tenant context. Extracts tenant context from the lambda events
"""
def log_with_tenant_context(event, log_message):
logger.structure_logs(append=True, tenant_id= event['requestContext']['authorizer']['tenantId'])
logger.info (log_message)
server/src/OrderService/order_service.py
@tracer.capture_lambda_handler
def get_order(event, context):
tenantId = event['requestContext']['authorizer']['tenantId']
tracer.put_annotation(key="TenantId", value=tenantId)
logger.log_with_tenant_context(event, "Request received to get a order")Powertools for AWS Lambda
また、ここでは Powertools for AWS Lambda も使用しています。これは、サーバーレスアプリケーションの開発を加速させるために、サーバーレスのベストプラクティスが実装された開発者向けツールキットで、オープンソースで利用できるライブラリです。ログの他にも、X-ray によるトレースの取得、アノテーションの追加などをサポートする Tracer ユーティリティなども活用しています。これも開発者の生産性を高め、SaaS のコアビジネスに注力してもらうのを助ける便利なツールなので、積極的に導入を検討してみてください。
まとめ
サーバーレスサービスを用いたマルチテナント SaaS の構成例と、注意すべきポイントについて解説しました。実装の詳細については掘り下げたい方はドキュメントやコードをご覧ください。前回までのコンテナ編と比較して、マネージドサービスならではの性質を考慮すべき点が多かったのではないでしょうか。しかしこれは、どちらの技術が優れているかといったようなものではありません。SaaS はビジネスモデルであり、それを実現する技術は多岐にわたります。技術選定には、開発者がどの技術に慣れているかといった多くの要因が関わります。
取り上げたリファレンスはあくまで一例であり、もちろんこの他の技術でマルチテナント SaaS を実装することも可能です。ただし、これまで説明してきた概念や実装方針の根底には共通する考え方があり、これらは他のアーキテクチャの設計・実装においても大きく役立つでしょう。リファレンスをそのまま利用するのではなく、必要なエッセンスを自社のアーキテクチャにうまく取り入れるような形で参考にしていただければ幸いです。
本連載はこれで最後となりますが、引き続き SaaS に関する情報を発信していきますのでよろしくお願いします !
筆者プロフィール
櫻谷 広人
アマゾン ウェブ サービス ジャパン合同会社
パートナーソリューションアーキテクト
大学 4 年から独学でプログラミングを習得。新卒で SIer に入社して Web アプリケーションの受託開発案件を中心にバックエンドエンジニアとして働いた後、フリーランスとして複数のスタートアップで開発を支援。その後、toC 向けのアプリを提供するスタートアップで執行役員 CTO を務める。現在は SaaS 担当のパートナーソリューションアーキテクトとして、主に ISV のお客様の SaaS 移行を支援。

Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages