- AWS Builder Center
- builders.flash
看護学生向け就職情報「ナース専科 就職」の SLI 設定の変遷と SLO 運用
2025-06-03 | Author : 山口 隆史 (株式会社エス・エム・エス)
はじめに
こんにちは、株式会社エス・エム・エスで全社 SRE チームに所属している山口 隆史です。
弊社で運営している「ナース専科 就職」は病院検索や説明会・インターンシップ・採用試験申込み、無料適職診断など、就職活動に役立つ情報を提供しています。オンライン就活ゼミや合同就職フェアも実施しキャリア形成を支援しています。看護学生向けの求人サービスです。
説明会・インターンシップへの申し込みや合同就職フェアでは、そのイベントの特性から多数の同時アクセスが発生しやすいです。過去に一部のリクエストのレイテンシーが悪化したことが原因となり、全体的なリクエストのレイテンシー悪化につながったことがありました。
そこで、開発チームと全社 SRE チームで連携してユーザー体験を守っていくために Service Level Objective (SLO: サービスレベル目標) の運用を開始しました。本記事では「ナース専科 就職」で行った Service Level Indicator (SLI: サービスレベル指標) 設定の変遷について紹介します。
ご注意
本記事で紹介する AWS サービスを起動する際には、料金がかかります。builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
SLI/SLO 導入の課題・背景
「ナース専科 就職」は、看護学生向けの求人サービスであり、病院検索や説明会・インターンシップの申し込みなど、就職活動に役立つ情報を提供しています。
説明会・インターンシップへの申し込みや合同就職フェアでは、多数の同時アクセスが発生しやすく、過去にリクエストのレイテンシーが悪化したことがありました。レイテンシーの悪化は、ユーザー体験を損なうだけでなく、サービスの信頼性にも影響を与えますが、ユーザー体験が定量的に把握できていないことが課題でした。
そのため、説明会・インターンシップへの申し込みや合同就職フェア開催時には、規模に応じてですが、メトリクス上でなにか変化があった場合に備え、エンジニアが待機する運用を行っていました。
そこで、サービスの信頼性を定量的に把握し、サービスの品質の改善に利用することを目指して、開発チームと全社 SRE チームが連携しユーザー体験を守るために SLO の運用を開始しました。
1. システム概要
「ナース専科 就職」は、Amazon CloudFront、Application Load Balancer、Amazon ECS on AWS Fargate、Amazon Aurora MySQL、Amazon ElastiCache for Redis、Amazon S3 を利用したシンプルなシステム構成です。
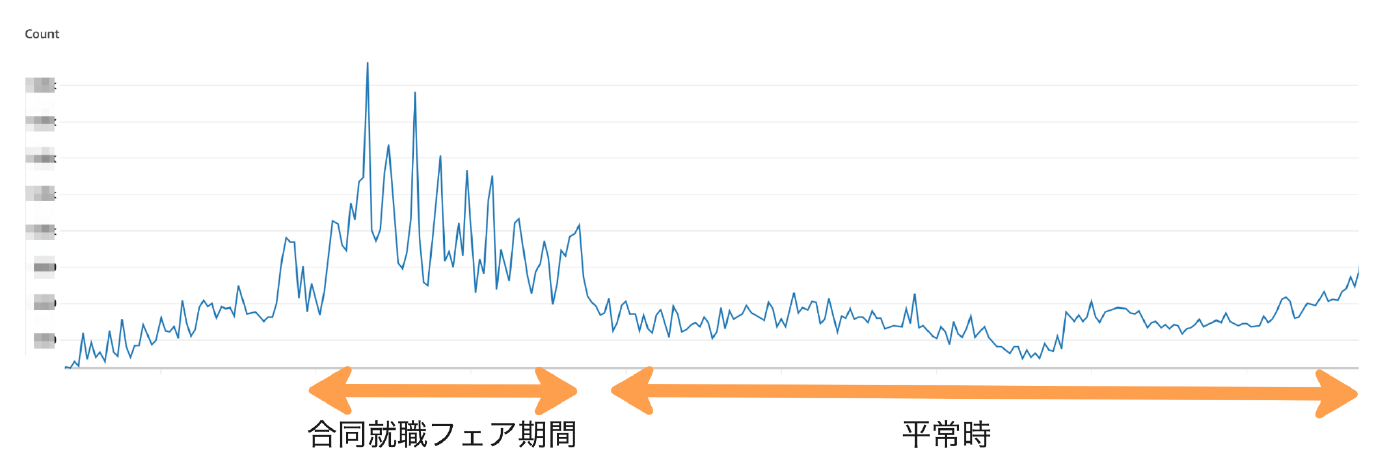
合同就職フェア期間と平常時のリクエスト数
リクエスト数のグラフからわかるように、合同就職フェア期間は平常時よりも多くのリクエストが発生し、平常時の 5 から 10 倍程度増加します。
2. SLI 設定の変遷
2-1. Application Load Balancer の TargetResponseTime で SLI 設定
SLI としてApplication Load Balancer の TargetResponseTime で SLI を設定し運用してみました。数週間監視してみたところ、ログ上では看護学生のユーザー体験は問題がないように見えるにも関わらず、SLO が悪化していたりと看護学生のユーザー体験と指標値とのズレが発生しました。
これは、1つの Application Load Balancer に管理用のサービスと看護学生向けのサービスがぶら下がる構成になっていること、管理用サービスはその特性上レイテンシーが長くなりやすいアップロード・ダウンロード系のリクエストが発生するが看護学生のユーザー体験には影響がないこと、というシステム特性があります。パーセンタイルを調整して管理用サービスを除外しようとしましたが、ユーザー体験と SLI とのズレが解消できず SLO としては運用できませんでした。
ここからの学びは、異なるサービス特性が同居するメトリクスは SLI としては適さないということです。
2-2. Application Load Balancer のターゲットグループ の TargetResponseTime で SLI 設定
次に Application Load Balancer のターゲットグループの TargetResponseTime を SLI として設定し運用してみました。これは、管理用のサービスと看護学生向けのサービスでターゲットグループレベルで分離できていたため可能でした。
こちらも数週間運用してみました。説明会・インターンシップへの申し込みや合同就職フェアでは無い期間に SLO が悪化したり、期間中は常に SLO が悪化する傾向が見られました。
SLO が悪化する傾向(=バジェットが不足する可能性)がみられたタイミングで、悪化の原因に対してなんらかの対策をしたいのですが、SLO とリソースのメトリクスからは具体的な原因の追求ができず、したがって有効な対策もできませんでした。
これは、看護学生向けのサービスでもレイテンシーが低い PATH とレイテンシーが高い PATH があり、それらを同じ SLI で扱っていたから発生した事象でした。これはアクセスログを分析して判明しました。
ここからの学びは、同じサービスでも PATH 特性が異なる場合にレイテンシーで SLI を設定する場合は分割すべきということです。
2-3. Datadog APM で SLI 設定
そこで PATH 別に SLI を取得しようと試行錯誤しましたが、AWSのマネージドサービスではターゲットグループ内のリクエスト PATH 別にメトリクスを取得することはできませんでした。 Application Load Balancer のアクセスログを加工すれば可能なのですが、手間がかかりすぎます。
SLI を設定する目的から考えるとユーザーに近いところで設定をしたいのですが、ユーザーに近いところでは簡便な方法で PATH 別にメトリクスが取得できなかったため、最終的に既に導入済みであった Datadog APM で SLI を設定することにしました。
Datadog APM を使用した SLI/SLO 設定
4 つの API を対象
SLI を設定する際は、説明会・インターンシップへの申し込みや合同就職フェアでの看護学生がたどる一般的と思われる導線をクリティカルユーザージャーニーとし、そこでコールされる PATH に対して設定を行いました。
クリティカルユーザージャーニーとして、以下の 4 つの API を対象としました。
- TOPページ
- 病院検索ページ
- 説明会・インターンシップ一覧ページ
- 説明会・インターンシップ申し込みページ
3. SLO を使って改善のサイクルを回す
SLO が悪化したときに原因追及が出来るようになったことで、初めて改善のサイクルを回すことが出来るようになりました。
具体的にはアラート設定は行わず、定点観測で監視を行っています。これは SLO によるアラートは即時にアクションが必要なものではなく、加えて即時にアクションが可能な性質のものではないという判断をしたためです。
定点観測は、全社 SRE チームと開発チームで定期的に実施している定例ミーティングで実施しています。ダッシュボードを眺め、ダッシュボード上で SLO 違反が頻発している箇所や、エラーバジェットの消費が早い事象が確認された場合は、共同で異常が発生し始めた近辺での本番作業やリリースの内容を確認したり、メトリクスや APM で原因を追求することを行っています。
原因追及の結果、対応が必要な場合は開発チーム側のスプリントバックログに追加したり、全社 SRE チームのバックログに追加したりして対応を実施しています。
数ヶ月こういった取り組みを続けた結果、説明会・インターンシップへの申し込みや合同就職フェアの開催期間中も SLO 違反が継続することがない状態となり、エンジニアが待機する必要がなくなりました。
まとめ
本記事では「ナース専科 就職」での SLI 設定について紹介しました。
「ナース専科 就職」では、段階を踏んで SLI の設定に取り組んできました。結果として Datadog APM を使用した SLI に行き着きましたが、サービスによっては Application Load Balancer やターゲットグループのメトリクスだけで十分なことも考えられます。
また、APM で SLI を設定する場合、アプリケーションの手前で発生したエラーや障害は SLO に反映されないため、Application Load Balancer やターゲットグループのメトリクスも合わせて監視する必要があることにも注意が必要です。
筆者プロフィール
山口 隆史 (やまぐち たかし)
株式会社エス・エム・エス
プロダクト推進本部 技術推進グループ
2024 年に株式会社エス・エム・エスに入社。
現在は、全社 SRE チームとして全社へのクラウド技術の展開やクラウドセキュリティ、ガバナンス強化にむけた施策の推進を行っています。
