- AWS Builder Center›
- builders.flash
Icebergの衝撃 - AWS 環境で始める次世代データ管理 (AWS Lake Formation & Amazon S3 Tables 対応版)
2025-09-04 | Author : 丸本 健二郎 (AWS Data Hero)
はじめに
こんにちは。AWS Data Hero の丸本です。
今回は、私が実際に業務で活用している Apache Iceberg について、その魅力、活用のユースケース、そして AWS 環境での実践的な導入方法まで、現場の視点から詳しく紹介します。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
Icebergとは何か?
Apache Iceberg は、Netflix 発のオープンソースのテーブルフォーマットで、Hadoop や Hive に依存せず、大規模データレイク環境でスキーマ進化や ACID トランザクションを実現する次世代アーキテクチャです。
従来、データレイクの実装ではHive互換形式の Parquet ファイルを用い、「ファイルベースで処理できる = RDBよりもコストがかからず、クラウドにも最適」という理由で広く採用されてきました。私自身も、Amazon S3 と AWS Glue、Amazon Athena を組み合わせた構成で、Hive 形式のパーケットを使ったデータ分析を長年運用してきました。
ただし、その形式には明確な限界がありました。たとえば:
- データの UPDATE や DELETE に対応できず、上書きにはファイル全体の作り直しが必要
- スキーマ変更時の互換性維持に苦労する
- パーティション数が増えるとクエリ性能や運用が破綻する
見た目は単なる Parquet ファイルの管理に見えるかもしれませんが、Iceberg の本質はそこにはありません。
Amazon S3 を前提としたファイルベースのクラウドデータレイクに、RDB の ACID 特性・スキーマ進化性を持ち込んだイノベーションだと捉えています。
これにより、Amazon S3 上のデータが「読み出し専用」から「更新・削除・履歴管理も可能」なデータソースへと進化し、クラウド時代の新しい “RDB の形” として注目すべき技術になっています。
Amazon S3 Tablesとは ?
AWS では、Iceberg などの次世代テーブルフォーマットをベースとした 「Amazon S3 Tables」 を正式にサポートしています。S3 Tables とは、Amazon S3 上のファイルを Iceberg 形式で管理し、AWS Glue Catalog で定義された「SQL で扱えるテーブル」として運用する仕組みです。
以下が主な特徴です:
- Iceberg 形式で定義されたテーブルを AWS Glue Catalog に登録
- Amazon Athena や Amazon Redshift Spectrum からそのままクエリ可能
- ACID トランザクション、スナップショット、スキーマ進化に対応
- AWS Lake Formation と連携して列単位・ユーザー単位の制御が可能
Iceberg + Lake Formation 連携構成
こちらの構成図は、Iceberg 形式で管理された S3 Tables を、Lake Formation を通じてセキュアに制御しながら、Athena や Amazon QuickSight などの分析系サービスから活用する構成を示しています。
Iceberg は、スキーマ進化・DELETE・MERGE・スナップショットによる履歴管理など、Amazon S3 上のデータを「RDB のように扱う」ための機能を数多く備えており、データの保存・操作においてはまさに最強クラスの基盤です。
ただし、「誰に、どのカラムや行を見せるか」というアクセス制御の話は別問題です。特に実運用では、以下のようなニーズが頻出します:
- 担当者によって見せてよいカラムを制限したい(例:個人情報は非表示)
- 部署や地域によってアクセスできる店舗・エリアを制限したい
- AthenaやQuickSight経由のアクセスでも一貫したセキュリティポリシーを担保したい
Lake Formation は、Glue Catalogと連携しながら、 テーブル単位・列単位・行フィルター単位でアクセス制御を適用できるサービスです。
つまり、Icebergが「自由なデータ操作」を可能にし、Lake Formationが「きめ細やかなアクセス制御」を担うことで、 柔軟さと安全性が両立した分析基盤を構築できるのです。
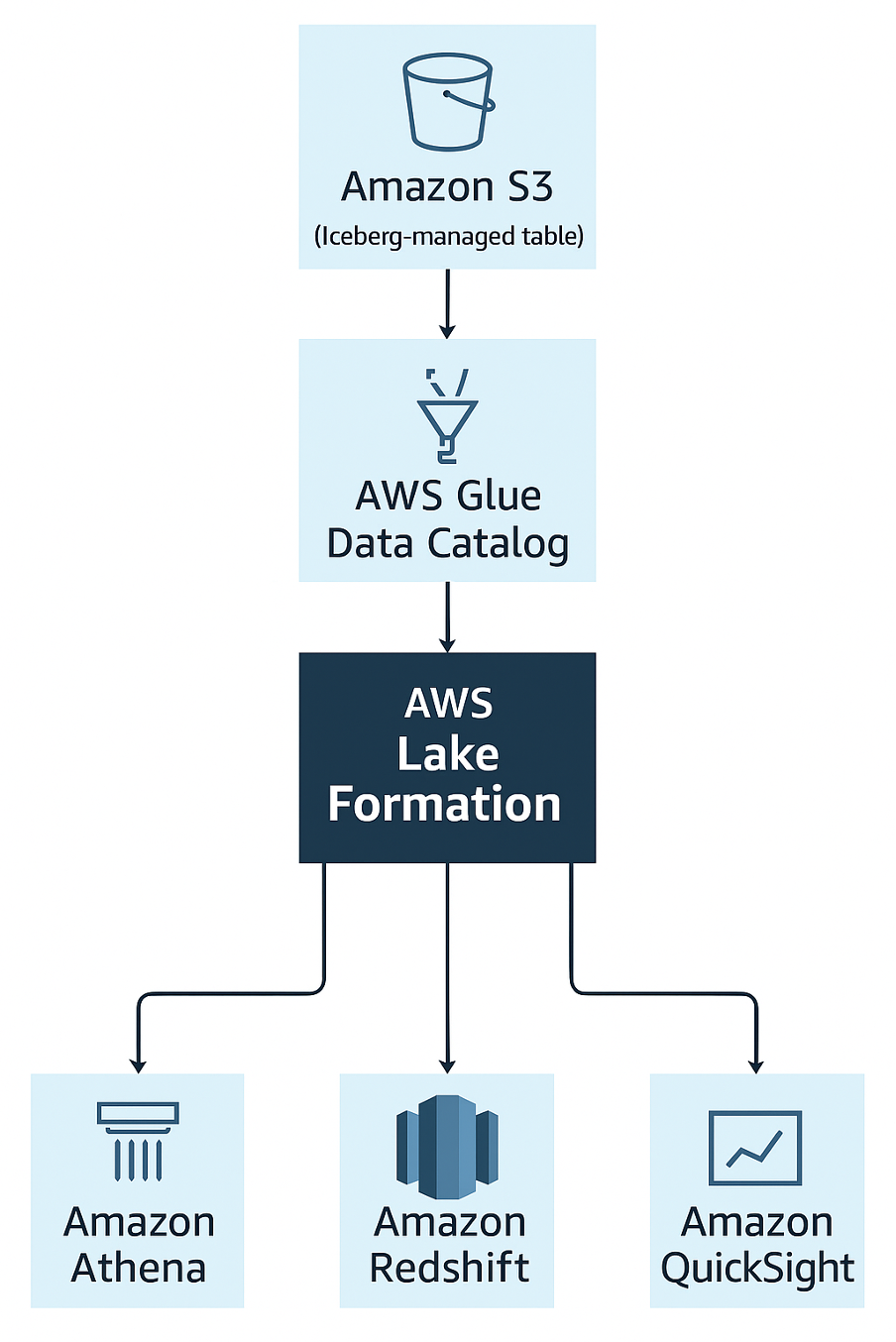
実プロジェクトでの構成例
私の関わるプロジェクトでは、以下の構成を採用しています。
- データ保存:Amazon S3 (Iceberg 形式の S3 Table)
- カタログ管理:AWS Glue Data Catalog
- クエリエンジン:Athena、Redshift Spectrum
- 可視化:QuickSight
- アクセス制御:Lake Formation
- パイプライン:Amazon EventBridge + AWS Lambda
Iceberg が向いているケース / 向かないケース
Iceberg が強い場面
- ログ・IoT など日次の蓄積データ
- UPDATE / DELETE を伴う履歴分析
- 複数部門での共通分析
- Hive 形式に限界を感じている環境
Iceberg では不足する場面
- ミリ秒単位のトランザクション (→ Amazon RDS)
- 即時のストリーム集計 (→ Flink 等)
- 小規模ユースケース
Iceberg と Amazon RDS の比較
まとめ
Iceberg は単なるファイル管理フォーマットではなく、AWS 時代の標準的なデータ基盤の構成要素となっています。
特に「S3 Tables として管理すること」「Lake Formation で制御すること」の 2 つを組み合わせることで、 柔軟性とセキュリティの両立が可能になります。
Amazon S3 や Athena を既に導入している方であれば、Iceberg へのステップアップは思った以上にスムーズです。
builders.flash をご覧の皆さんにも、ぜひこの構成を試していただきたいと思います。
筆者プロフィール
丸本健二郎
オプターク合同会社 代表
AWS Data HERO | BigData-JAWS 運営メンバー
1980 年、広島県東広島市生まれ。2005 年、大学の情報学部を卒業し大阪の SIer に就職。人事パッケージの導入支援コンサルティングに携わる。2008 年、日本オラクルに移り大手企業を対象とした人事給与システムなどの構築に従事。2011 年、広島の大型プロジェクトをきっかけに帰郷し、翌年、同市に本社を置く大創産業の情報システム部門に転職。入社後はシステムの内製化を推進し、AWS を採用した発注システムやAmazon Redshift を用いた自動発注システムを構築に尽力。その後も AWS のサーバーレス環境により 5,000 店舗 × 7 万アイテムのデータを処理する POS データ集中処理システム構築や BI 環境の整備などを通じて、クラウドシフトに取り組む。AWS Cloud Roadshow 2017 広島での登壇を機に、 JAWS-UG 広島支部の運営にかかわるようになり、2018 年、AWS Samurai に選出される。2019 年、オプターク合同会社を創業。2020 年、県立広島大学大学院経営管理研究科を修了。同年 3 月から専業に。
BigData-JAWS は 4 半期に 1 度、RedShift/EMR/Athena といった分析集計、DaynamoDB に代表される分散 KVS、QuickSight といったビジネスインテリジェンスなどに関連する勉強会を開催しています。ぜひ こちらから登録メンバー となって勉強会に参加ください。
